Cloud Intelligence™
Amazon Redshift: Warum Ihre Concurrency Scaling-Kosten immer weiter steigen (und wie Sie das Problem lösen)
Diese Seite ist auch in English, Español, Français, Italiano, 日本語 und Português verfügbar.









About Joseph Allam
Databases have been my craft for a long time — long before the cloud, and deep into it across AWS and GCP. I know what breaks, what costs too much, and what needs rethinking before it hurts. I also know how to bring AI into the work: into how databases are designed, operated, and accessed by the intelligent systems being built on top of them.
My personal pageUnerwartete Kostensteigerungen bei Amazon Redshift wirken auf den ersten Blick oft wie isolierte Ausschläge. In der Praxis stecken meist Workload-Muster dahinter, die Concurrency Scaling unbemerkt über seine eigentliche Rolle hinaus beanspruchen.
Concurrency Scaling soll zusätzliche Redshift-Kapazität bereitstellen, wenn die Abfragelast steigt, und sie wieder abbauen, sobald die Last nachlässt. Für Lastspitzen ist das nützlich. Ist es jedoch über längere Zeiträume aktiv, verhält es sich weniger wie Überlaufkapazität und mehr wie Grundlast-Compute. Damit verändert sich in der Regel das Kostenprofil des Workloads.
Dieser Beitrag schildert eine Redshift-Analyse aus der Praxis, bei der erhöhte Ausgaben zunächst wie normales Workload-Wachstum aussahen. Eine genauere Auswertung der Abrechnungsdaten, der Cluster-Konfiguration und der CloudWatch-Metriken zeigte ein anderes Bild: Gemischte workloads teilten sich denselben Cluster, erzeugten dauerhaft CPU-Druck und lösten Concurrency Scaling über weite Teile des Tages aus.
Wir gehen die Analyse Schritt für Schritt durch: die entscheidenden Metriken, die Konfigurationsentscheidungen, die Kosten verstärkt haben, und den Maßnahmenplan.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Was Sie aus diesem Beitrag mitnehmen
Am Ende verfügen Sie über einen praxistauglichen Ablauf, um:
- zu erkennen, welcher Redshift-Cluster die Kosten treibt
- CPU-Druck von Queue-Druck zu unterscheiden
- zu erkennen, wann Concurrency Scaling als Grundkapazität dient
- WLM-Routing-Probleme aufzuspüren, die Kosten in die Höhe treiben
- einen stufenweisen Maßnahmenplan zu erstellen
Schritt 1: Kostentreiber identifizieren, bevor Sie etwas ändern
Wenn die Redshift-Kosten unerwartet steigen, ist die Versuchung groß, direkt in Query-Tuning oder Cluster-Resizing einzusteigen. Das ist riskant. Query-Tuning kann helfen, und Resizing wird vielleicht irgendwann nötig — doch keines von beiden sollte der erste Schritt sein.
Die erste Frage ist einfacher:
Welche Redshift-Ressource ist tatsächlich für den Anstieg verantwortlich?
In dieser Analyse umfasste die Umgebung zwei provisionierte Redshift-Cluster:
| Cluster | Rolle | Kostenverhalten |
|---|---|---|
analytics-production-cluster |
Haupt-Analytics, BI, Anwendungs-, Batch- und ML-workloads | Hohe Kosten, starke Schwankungen |
batch-processing-cluster |
Dedizierter Batch- bzw. Single-Purpose-Workload | Stabil und vorhersehbar |
Die Abrechnungsdaten zeigten, dass nahezu sämtliche Ausgaben und Schwankungen vom Mixed-Use-Analytics-Cluster stammten. Der kleinere Batch-Cluster hatte stabile Kosten, geringe Verbindungsaktivität und keinerlei Concurrency Scaling-Nutzung.
Diese Unterscheidung war wichtig. Sie engte die Untersuchung schnell ein und ersparte uns Zeit für einen Cluster, der nicht maßgeblich zum Problem beitrug.
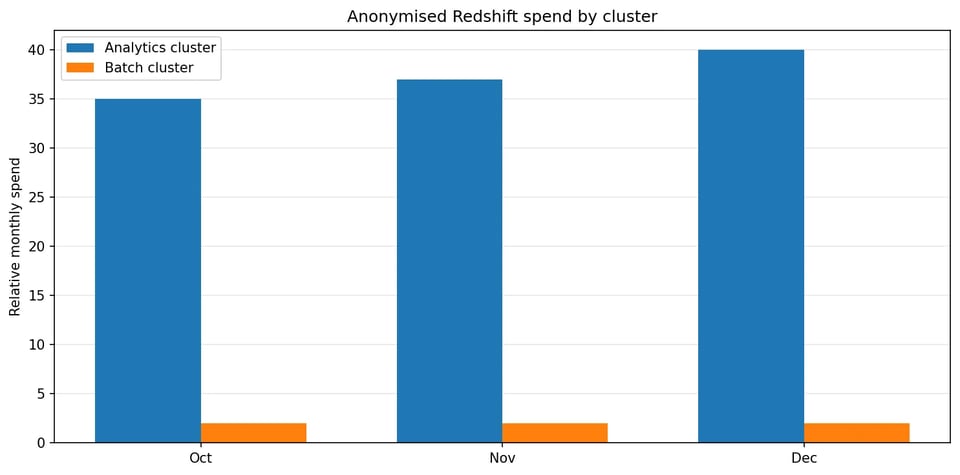
Nahezu sämtliche Kostenschwankungen stammten von einem einzigen Mixed-Use-Analytics-Cluster.
Die Kostendaten zeigten außerdem, dass die größten Ausschläge auf Compute- und Scaling-Verhalten zurückgingen, nicht auf Speicherwachstum. Das verlagerte den Fokus auf das Laufzeitverhalten, den CPU-Druck und die Scaling-Aktivität.
Die Arbeitshypothese war einfach: Der Analytics-Cluster griff über längere Zeiträume als erwartet auf zusätzliche Compute-Kapazität zurück.
Schritt 2: Mit der Cluster-Konfiguration beginnen
Nachdem der kostentreibende Cluster identifiziert war, ging es im nächsten Schritt darum, seine Konfiguration zu prüfen.
Der Cluster nutzte RA3-Knoten, Managed Storage, Workload Management und Concurrency Scaling. Auf Konfigurationsebene war nichts offensichtlich falsch. Das ist einen kurzen Moment des Innehaltens wert: Ein Redshift-Cluster kann aus statischer Konfigurationssicht solide aussehen und trotzdem schlecht auf die tatsächliche Nutzung durch die workloads abgestimmt sein.
Die entscheidende Frage lautete nicht ist der Cluster korrekt konfiguriert?, sondern passt die Cluster-Konfiguration zum Workload-Muster? Damit verlagerte sich die Analyse weg von der statischen Konfigurationsprüfung hin zum Laufzeitverhalten.
Der Cluster unterstützte mehrere Workload-Typen:
- BI-dashboards
- Anwendungsgetriebene Analytics
- Batch- und Transformations-Pipelines
- ML- oder kampagnenbezogene Verarbeitung
- Geplante Data-Engineering-Jobs
Dieses Mixed-Use-Muster ist verbreitet, erfordert aber eine sorgfältige Workload-Isolation. Redshift Workload Management (WLM) definiert Query-Queues und leitet Arbeit zur Laufzeit in diese Queues. AWS beschreibt WLM als den Mechanismus zur Verwaltung von Query-Queues, Prioritäten und Workload-Routing.
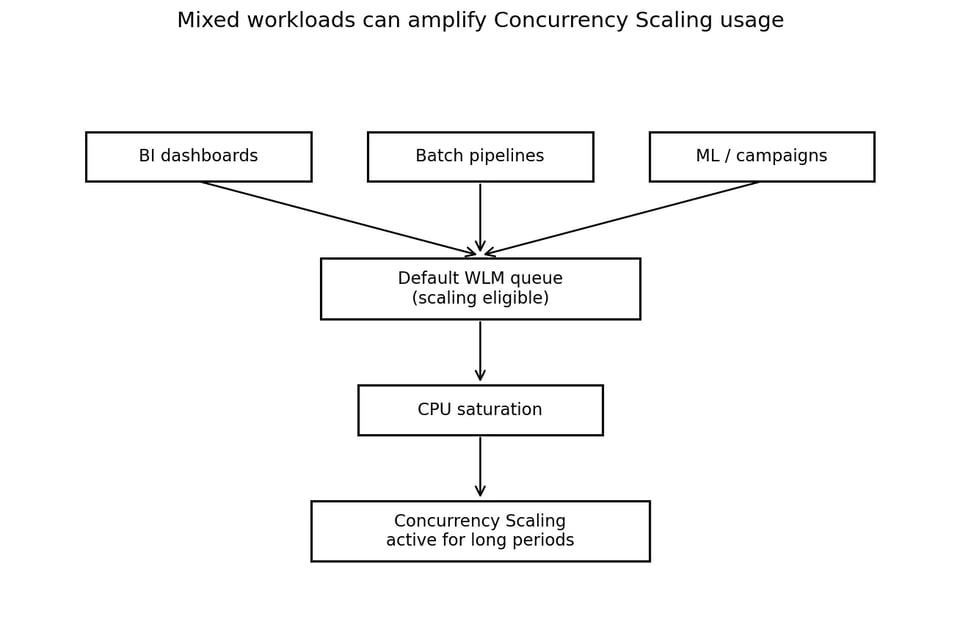
Teilen sich mehrere Workload-Typen eine scaling-fähige Queue, ist Concurrency Scaling keine Burst-Kapazität mehr.
Schritt 3: CloudWatch erzählt die Geschichte
Im nächsten Schritt prüften wir eine kleine Auswahl an CloudWatch-Metriken für Redshift.
Das Ziel: eine einzige Frage zu beantworten — verzeichnete dieser Cluster kurze Lastspitzen oder dauerhaften Druck?
Am nützlichsten waren folgende Metriken:
CPUUtilizationConcurrencyScalingActiveClustersConcurrencyScalingSecondsDatabaseConnections- Festplattenauslastung
Das Muster wurde schnell deutlich.
Belastungsfenster: 00:00 bis 09:00 UTC
In diesem Zeitraum waren die Belastungsanzeichen am stärksten: höchste CPU-Auslastung, höchste Anzahl an Datenbankverbindungen, anhaltendste Concurrency Scaling-Aktivität und mehrere überlappende workloads. Das deutete darauf hin, dass Batch-, Dashboard- und Anwendungs-workloads im selben Zeitfenster kollidierten.
Geschäftszeiten-Fenster: 09:00 bis 17:00 UTC
Die Aktivität blieb erhöht, lag aber meist unter dem frühen Fenster. Treiber waren wahrscheinlich BI, Dashboard-Nutzung und interaktive Analytics.
Niedriglast-Fenster: 17:00 bis 23:00 UTC
In diesem Zeitraum gab es mehr Reserven: geringere CPU-Auslastung, reduzierte Scaling-Aktivität, weniger Verbindungsdruck. Das machte es zum natürlichen Kandidaten, um Batch- oder Transformations-workloads mit niedrigerer Priorität umzuplanen.
Schritt 4: Concurrency Scaling verhielt sich nicht wie Burst-Kapazität
Der wichtigste Befund betraf das Concurrency Scaling-Muster. Der Cluster nutzte Concurrency Scaling nicht nur während kurzer Spitzen, sondern über den Großteil des Tages — oft mit mehreren Scaling-Clustern gleichzeitig. Im beobachteten Zeitraum war Concurrency Scaling etwa 18 bis 20 Stunden pro Tag aktiv.
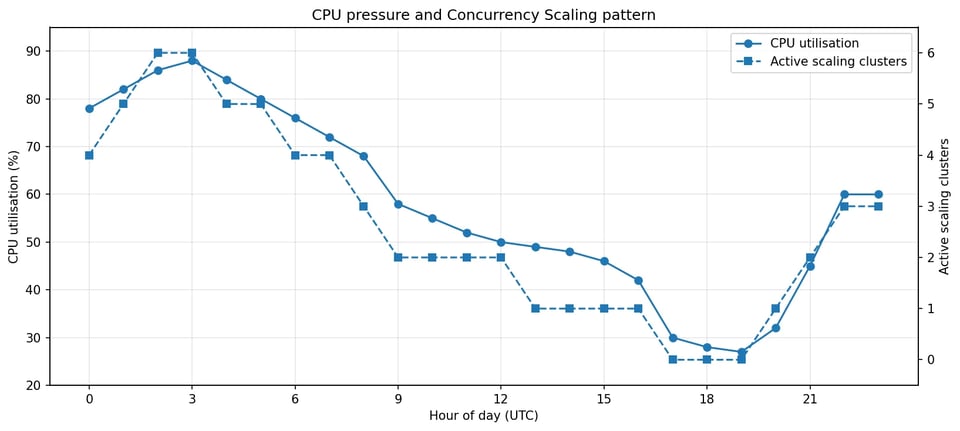
Concurrency Scaling folgte dem CPU-Druck über den Großteil des Tages, nicht nur bei Spitzen.
Das veränderte den Charakter der Untersuchung. Die Frage lautete nicht mehr warum hat Redshift bei einer Spitze skaliert?, sondern warum braucht dieser Cluster dauerhaft Überlaufkapazität?
Dauerhafte Concurrency Scaling-Nutzung ist ein Signal dafür, dass der Workload möglicherweise nicht zur Grundkapazität, zum Workload-Routing oder zur Planung passt. An diesem Punkt verschob sich die Untersuchung von "die Spitze finden" hin zu "die Form des Workloads verstehen".
Schritt 5: Den Engpass identifizieren
Als Nächstes galt es herauszufinden, was den Scaling-Druck tatsächlich verursachte. Es gibt mehrere typische Möglichkeiten:
- CPU-Sättigung
- Queue-Wartezeit
- Festplattendruck
- I/O-Druck
- Verbindungsdruck
- Schlechtes Workload-Routing
Die Metriken wiesen klar auf die CPU hin. Die CPU-Auslastung blieb hoch, mit häufigen Spitzen in genau den Fenstern, in denen Concurrency Scaling aktiv war. Die Festplattenauslastung war unauffällig. I/O- und Netzwerk-Durchsatz waren aktiv, schienen aber nicht der primäre Engpass zu sein.
Das ist wichtig, denn die Lösung für CPU-Sättigung unterscheidet sich von der für Queue- oder Speicherdruck. Queue-Wartezeit verweist auf die WLM-Konfiguration und Slot-Zuweisung. Speicherdruck deutet auf Tabellen-Design, Datenlebenszyklus und Managed Storage-Nutzung hin. CPU-Druck verweist auf Query-Effizienz, Workload-Planung, Queue-Isolation und Compute-Grundkapazität.
In diesem Fall verrichtete der Cluster über lange Zeit sehr viel Arbeit, wobei viele workloads um die CPU konkurrierten.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Schritt 6: Die WLM-Queue war der Kostenverstärker
Der nächste Befund lag im Workload Management. Es waren mehrere Queues definiert, doch Concurrency Scaling war auf der Default Auto WLM-Queue aktiviert — und diese Queue fungierte zugleich als Auffangbecken für workloads, die nicht explizit anderweitig geroutet wurden.
Daraus ergab sich ein einfaches, aber teures Muster:
Nicht klassifizierte oder gemischte workloads vDefault Auto WLM-Queue (Scaling aktiviert) vCPU-Druck vConcurrency Scaling vHöhere Compute-KostenDas Problem war nicht, dass Auto WLM oder Concurrency Scaling "falsch" wären. Beide sind nützliche Redshift-Funktionen. Das Problem war, dass zu viel gemischter Workload durch die eine Queue floss, die Zugriff auf Scaling-Kapazität hatte.
WLM-Routing kann auf User-Gruppen, Query-Gruppen und verwandten Klassifizierungsregeln basieren — und ist damit ein zentraler Steuerungspunkt für die Workload-Isolation. Landen BI-dashboards, Batch-Jobs, ML-workloads und Anwendungs-Queries alle in derselben scaling-fähigen Queue, wird Concurrency Scaling zur breiten Notlösung statt zum gezielten Werkzeug.
So wachsen Kosten unbemerkt.
Schritt 7: Verbindungen sind nicht dasselbe wie aktive Concurrency
Eine weitere nützliche Beobachtung betraf die Datenbankverbindungen. Der Cluster zeigte regelmäßige Spitzen bei der Verbindungsanzahl, die in belastungsstarken Fenstern teils hohe Werte erreichten. Zunächst sah das nach einem möglichen Problem mit dem Verbindungslimit aus.
Datenbankverbindungen sind aber nicht dasselbe wie aktiv laufende Queries. Ein Redshift-Cluster kann viele offene Verbindungen haben, während nur ein Teil der Arbeit tatsächlich ausgeführt wird — abhängig von Workload Management, Speicher, CPU und Queue-Konfiguration. Hohe Verbindungszahlen sind dennoch ein nützliches Signal, weil sie häufig auf Dashboard-Refreshes, Anwendungs-Fan-out oder Job-Bursts hinweisen. Für sich genommen sind sie aber kein Beleg für aktive Query-Concurrency.
In dieser Analyse waren die Verbindungsspitzen nützlich, weil sie mit dem CPU-Druck und der Concurrency Scaling-Nutzung zusammenfielen. Damit gehörten sie zur Geschichte, waren aber nicht die alleinige Ursache.
Die bessere Schlussfolgerung: Viele Clients verbanden sich und schickten Arbeit in vorhersehbaren Fenstern ein, und der Cluster hatte für diesen Workload-Mix nicht genug effektive Compute-Reserven.
Schritt 8: Query-Sichtbarkeit hängt von Datenbank-Berechtigungen ab
Bei der Analyse von Query-Verhalten sind die Systemtabellen und -Views von Redshift unverzichtbar. Ein häufiger Stolperstein ist dabei die Query-Sichtbarkeit. In den Redshift-Systemviews sehen Superuser alle Zeilen, normale User in der Regel nur ihre eigenen Daten. AWS weist auf diese Sichtbarkeitsregel für Views wie SYS_QUERY_HISTORY, STL_WLM_QUERY, STL_QUERY_METRICS und verwandte Monitoring-Views hin.
Für eine clusterweite Workload-Analyse benötigt die ausführende Person die passenden Datenbank-Berechtigungen.
Nützliche Fragen sind unter anderem:
- Welche User verbrauchen die meiste Ausführungszeit?
- Welche Queries laufen im belastungsstarken Fenster?
- Welche workloads nutzen Concurrency Scaling?
- Welche Queues nehmen den Großteil der Arbeit auf?
- Welche Queries wiederholen sich häufig genug, dass sich eine Optimierung lohnt?
Wo verfügbar, empfiehlt AWS die neueren SYS-Monitoring-Views, da sie übersichtlicher aufbereitet sind. Die älteren STL- und SVL-Views sind weiterhin verbreitet und für Untersuchungen nützlich, doch die SYS-Views sind der sauberere Ausgangspunkt, wenn sie das Benötigte abdecken.
Top-Queries nach Ausführungszeit
SELECT h.user_id, u.usename AS user_name, h.query_id, h.query_type, h.status, h.start_time, h.end_time, h.elapsed_time / 1000000.0 AS elapsed_seconds, h.execution_time / 1000000.0 AS execution_seconds, h.queue_time / 1000000.0 AS queue_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY h.execution_time DESCLIMIT 50;Top-User nach gesamter Ausführungszeit
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, COUNT(*) AS query_count, SUM(h.execution_time) / 1000000.0 AS total_execution_seconds, SUM(h.queue_time) / 1000000.0 AS total_queue_secondsFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)GROUP BY h.user_id, u.usenameORDER BY total_execution_seconds DESC;Top-Queries nach CPU-Zeit
SVL_QUERY_METRICS_SUMMARY ist hier nützlich, da diese View query_cpu_time, query_blocks_read und verwandte Metriken für abgeschlossene Queries enthält. AWS dokumentiert query_cpu_time als die von der Query verbrauchte CPU-Zeit in Sekunden.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.service_class_name, h.compute_type, m.query_cpu_time, m.query_execution_time, m.query_blocks_read, m.query_temp_blocks_to_disk, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hJOIN svl_query_metrics_summary m ON h.query_id = m.queryLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY m.query_cpu_time DESCLIMIT 50;WLM-Queue-Nutzung
SELECT service_class_name, compute_type, COUNT(*) AS query_count, SUM(queue_time) / 1000000.0 AS total_queue_seconds, SUM(execution_time) / 1000000.0 AS total_execution_seconds, AVG(queue_time) / 1000000.0 AS avg_queue_seconds, AVG(execution_time) / 1000000.0 AS avg_execution_secondsFROM sys_query_historyWHERE start_time >= dateadd(day, -7, current_date)GROUP BY service_class_name, compute_typeORDER BY total_execution_seconds DESC;Queries, die auf Concurrency Scaling liefen
In SYS_QUERY_HISTORY zeigt die Spalte compute_type bei provisionierten Redshift-Clustern an, ob eine Query auf dem Haupt-Cluster oder einem Concurrency Scaling-Cluster lief. AWS dokumentiert primary-scale als compute_type für Queries, die auf einem Concurrency-Cluster ausgeführt werden.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.end_time, h.execution_time / 1000000.0 AS execution_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date) AND h.compute_type = 'primary-scale'ORDER BY h.start_time DESCLIMIT 100;Diese Queries sind nicht das Ende der Optimierung, sondern der Anfang der Priorisierung. Es geht darum, das Raten zu beenden und zu identifizieren, welche workloads isoliert, umgeplant, getunt oder weiterhin mit Scaling versorgt werden sollten.
Schritt 9: Empfohlener Maßnahmenplan
Sobald das Muster klar war, ergab sich der Maßnahmenplan fast von selbst. Ziel war nicht, Concurrency Scaling blind abzuschalten. Das würde zwar wahrscheinlich Kosten senken, könnte aber auch das Queueing erhöhen und wichtige workloads ausbremsen.
Der sicherere Ansatz ist stufenweise: Er beginnt mit risikoarmen Routing-Änderungen und geht erst dann zu Entscheidungen über, die teurer rückgängig zu machen sind.
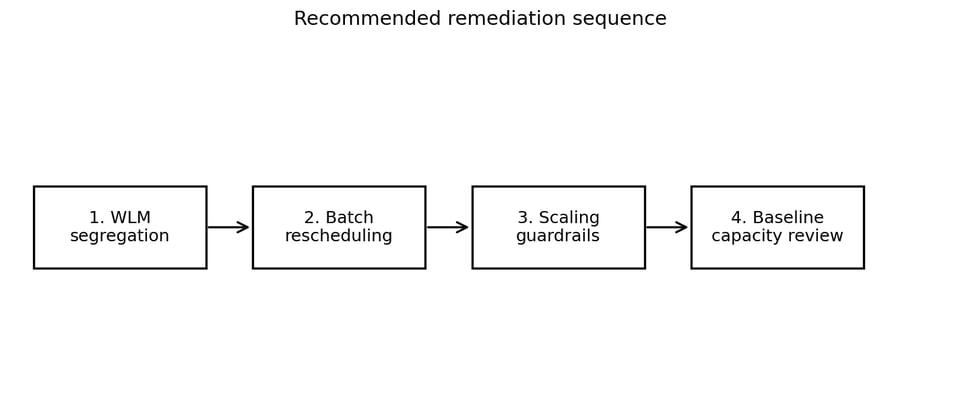
Eine stufenweise Reihenfolge hält die ersten Schritte günstig und reversibel.
1. workloads mit WLM trennen
WLM sollte die Workload-Priorität widerspiegeln. Zum Beispiel:
| Workload-Typ | Mögliche Behandlung |
|---|---|
| BI-dashboards | Höhere Priorität, eingeschränkter Scaling-Zugang |
| Kritische Anwendungs-Queries | Höhere Priorität, geschützte Queue |
| Batch-Jobs | Dedizierte Queue, oft ohne Scaling |
| ML- oder Transformations-workloads | Dedizierte Queue, wo möglich geplant |
| Ad-hoc-Analysen | Niedrigere Priorität oder eingeschränktes Scaling |
So verbraucht Batch-Arbeit mit niedrigerer Priorität nicht denselben Scaling-Pool wie interaktive oder geschäftskritische Queries. Da es sich um eine reine Routing-Änderung handelt, lässt sie sich schnell zurückrollen, falls eine Queue-Grenze nicht passt.
2. Batch-Jobs in Niedriglast-Fenster verschieben
Die Metriken zeigten ein klares Niedriglast-Fenster später am Tag — und damit einen unmittelbaren operativen Hebel.
Nicht jeder Batch-Job muss in der belastungsstärksten Phase laufen. Werden Transformations-, ML- oder Reporting-Jobs mit niedrigerer Priorität in ruhigere Fenster verlagert, sinkt der Spitzen-CPU-Druck, ohne dass die Clustergröße verändert werden muss. Das ist oft einer der praktischsten Kostenhebel, weil er das Timing ändert, nicht die Architektur.
3. Guardrails für Concurrency Scaling einziehen
Sind workloads korrekt geroutet und getaktet, ist der nächste Schritt, Concurrency Scaling selbst zu begrenzen. Darf es zu breit skalieren, schützt es zwar die Performance, erzeugt aber unvorhersehbare Kosten.
Ein sinnvoller erster Schritt ist, die maximale Anzahl erlaubter Scaling-Cluster auf einen kontrollierten Wert zu reduzieren und die Auswirkung zu beobachten. Das hilft bei der Beantwortung folgender Fragen:
- Welche workloads beginnen zu warten?
- Welche Jobs sind wirklich latenzsensitiv?
- Welche workloads griffen ohne fachlichen Grund auf Scaling-Kapazität zurück?
Es geht nicht darum, die Performance zu verschlechtern. Es geht darum, Scaling zu einer bewussten Ressource zu machen — und nicht zur unbegrenzten Standardeinstellung.
4. Grundkapazität neu bewerten
Bleibt Concurrency Scaling auch nach WLM- und Planungsänderungen über lange Zeit aktiv, ist der Basis-Cluster möglicherweise schlicht zu klein für den Workload. In diesem Fall kann es günstiger sein, Basiskapazität hinzuzufügen, statt dauerhaft auf Überlaufkapazität zu setzen.
Das ist kontraintuitiv, aber häufig: Mehr Grundkapazität kann die Gesamtkosten senken, wenn sie die dauerhafte Concurrency Scaling-Nutzung spürbar reduziert.
Entscheidend ist, diese Entscheidung nach der Workload-Isolation und Planungsverbesserung zu treffen. Sonst riskieren Sie, Knoten hinzuzufügen, während ineffizientes Workload-Routing weiterhin Scaling-Kapazität verbraucht.
5. Queries auf Basis von Evidenz tunen
Query-Optimierung sollte sich auf die workloads konzentrieren, die am stärksten ins Gewicht fallen:
- Hohe gesamte Ausführungszeit
- Hoher CPU-Verbrauch
- Häufige wiederholte Ausführung
- Ausführung in belastungsstarken Fenstern
- Queries, die in scaling-fähigen Queues landen
Hier wird die Analyse der Systemtabellen wirklich nützlich. Optimieren Sie die Queries, die Kosten und Performance maßgeblich beeinflussen — nicht die, die einfach nur hässlich aussehen.
Die wichtigsten Erkenntnisse
Diese Analyse hat einige praktische Redshift-Lehren bekräftigt.
Concurrency Scaling sollte nicht zur Grundkapazität werden. Ist es den Großteil des Tages aktiv, verhält es sich nicht mehr wie Burst-Kapazität. Es ist Teil des Steady-State-Compute-Modells geworden — und das ist ein Kostensignal.
CPU-Druck und Queue-Druck sind unterschiedliche Probleme. Hohe Concurrency Scaling-Nutzung bedeutet nicht automatisch, dass WLM-Queueing die Grundursache ist. Prüfen Sie CPU, Queue-Wartezeit, Festplatte, I/O und Verbindungsmuster gemeinsam.
Default-Queue-Routing kann teuer werden. Eine Catch-all-Queue mit aktiviertem Concurrency Scaling kann sich unbemerkt zum Hauptkostenverstärker entwickeln. WLM-Routing sollte der Workload-Priorität entsprechen.
Workload-Timing zählt. Überlappen sich Batch-Jobs, dashboards, ML-workloads und Anwendungs-Analytics, steigt der Scaling-Druck. Nicht-kritische Batch-workloads in ruhigere Fenster zu verlagern, kann Kosten senken, ohne die Funktionalität zu verändern.
Query-Tuning folgt auf die Attribution. Bevor Sie Queries tunen, identifizieren Sie, welche User, workloads und Queues den Ressourcenverbrauch treiben. Raten kostet meist nur Zeit.
Abschließende Gedanken
Redshift-Kostenoptimierung dreht sich selten um eine einzelne Einstellung. In diesem Fall war das Problem weder ein defekter Cluster noch eine einzelne schlechte Query. Es war eine Kombination aus gemischten workloads, vorhersehbaren Timing-Kollisionen, CPU-Sättigung und breitem Zugriff auf Concurrency Scaling über den Default-WLM-Pfad.
Der nützlichste Teil der Analyse war keine einzelne Metrik, sondern deren Verknüpfung:
- Der Kostenreport identifiziert den Cluster
- CloudWatch zeigt dauerhaftes Scaling und CPU-Druck
- Die WLM-Konfiguration erklärt, warum Scaling breit verfügbar ist
- Systemtabellen zeigen, welche User und Queries zu priorisieren sind
Wenn Ihre Redshift-Rechnung steigt und Concurrency Scaling unbemerkt vom Burst zur Grundlast geworden ist, sind Sie damit nicht allein. Diese Art von Kostenanalyse führt DoiT Woche für Woche mit AWS-Kunden durch. Unser Team aus über 100 Cloud-Experten hilft Ihnen, die Treiber zu identifizieren, workloads zu trennen und Concurrency Scaling wieder dorthin zu bringen, wo es hingehört. Kontaktieren Sie uns.