Cloud Intelligence™
Por qué los costos de Concurrency Scaling de Amazon Redshift no paran de crecer (y cómo solucionarlo)
Esta página también está disponible en English, Deutsch, Français, Italiano, 日本語 y Português.









About Joseph Allam
Databases have been my craft for a long time — long before the cloud, and deep into it across AWS and GCP. I know what breaks, what costs too much, and what needs rethinking before it hurts. I also know how to bring AI into the work: into how databases are designed, operated, and accessed by the intelligent systems being built on top of them.
My personal pageLos aumentos inesperados en los costos de Amazon Redshift suelen parecer picos aislados a primera vista. En la práctica, casi siempre se deben a patrones de workloads que, sin que nadie lo note, llevan a Concurrency Scaling más allá del rol para el que fue pensado.
Concurrency Scaling está diseñado para sumar capacidad a Redshift cuando aumenta la demanda de consultas y para retirarla cuando esa demanda baja. Es útil para picos puntuales. Pero cuando se mantiene activo durante períodos largos, deja de comportarse como capacidad de desborde y empieza a operar como cómputo base. Eso, por lo general, cambia el perfil de costos del workload.
Este artículo recorre una investigación de Redshift basada en un caso real, donde un gasto elevado parecía, en principio, un crecimiento normal del workload. Al revisar de cerca los datos de facturación, la configuración del clúster y las métricas de CloudWatch apareció otro patrón: varios workloads compartían el mismo clúster, generaban presión sostenida sobre la CPU y disparaban Concurrency Scaling durante la mayor parte del día.
Vamos a recorrer la investigación, las métricas que importaron, las decisiones de configuración que amplificaron el costo y el plan de remediación.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Qué te llevas de este artículo
Al final, vas a tener un flujo de trabajo práctico para:
- Identificar qué clúster de Redshift está generando el costo
- Separar la presión de CPU de la presión por encolamiento
- Detectar cuándo Concurrency Scaling se está usando como capacidad base
- Encontrar problemas de enrutamiento en WLM que amplifican el costo
- Armar un plan de remediación por fases
Paso 1: Confirma el origen del costo antes de cambiar nada
Cuando los costos de Redshift suben de forma inesperada, la tentación es ir directo al tuning de consultas o al redimensionamiento del clúster. Eso es arriesgado. El tuning puede ayudar y, con el tiempo, quizá haga falta redimensionar, pero ninguna de las dos cosas debería ser la primera jugada.
La primera pregunta es más simple:
¿Qué recurso de Redshift es el verdadero responsable del aumento?
En esta investigación, el entorno tenía dos clústeres de Redshift aprovisionados:
| Clúster | Rol | Comportamiento de costos |
|---|---|---|
analytics-production-cluster |
Workloads principales de analítica, BI, aplicaciones, batch y ML | Costo alto y muy variable |
batch-processing-cluster |
Workload batch dedicado / de propósito único | Estable y predecible |
Los datos de facturación mostraban que casi todo el gasto y la variabilidad venían del clúster analítico de uso mixto. El clúster más chico, orientado a batch, tenía un costo estable, baja actividad de conexiones y nada de uso de Concurrency Scaling.
Esa distinción importaba. Acotó la investigación rápido y evitó perder tiempo en un clúster que no contribuía de forma significativa al problema.
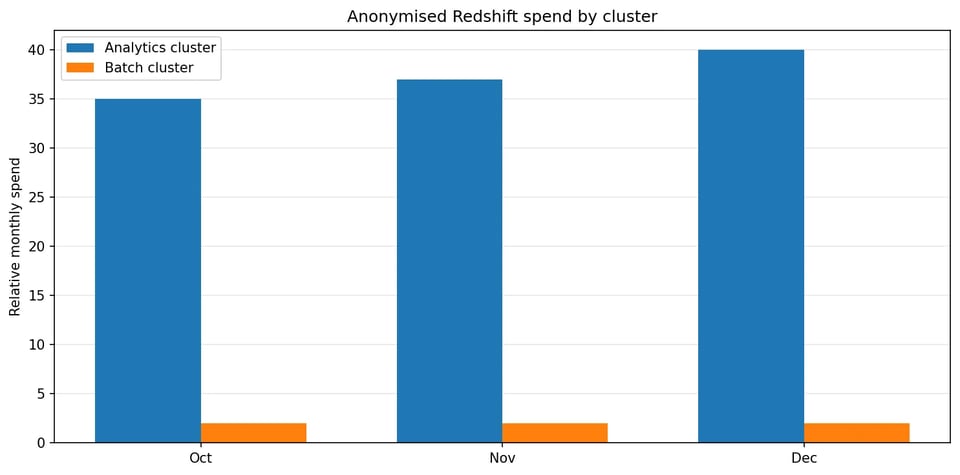
Casi toda la variabilidad del gasto venía de un único clúster analítico de uso mixto.
Los datos de costos también mostraron que las mayores fluctuaciones estaban ligadas al cómputo y al comportamiento de escalado, más que al crecimiento del almacenamiento. Eso corrió el foco hacia el comportamiento en runtime, la presión de CPU y la actividad de escalado.
La hipótesis de trabajo era simple: el clúster analítico se estaba apoyando en capacidad de cómputo adicional durante períodos más largos de lo esperado.
Paso 2: Arranca por el estado del clúster
Una vez identificado el clúster que estaba generando el costo, el siguiente paso fue revisar su estado.
El clúster usaba nodos RA3, almacenamiento gestionado, Workload Management y Concurrency Scaling. A nivel de configuración, nada parecía claramente roto. Vale la pena detenerse en eso. Un clúster de Redshift puede verse razonable desde una vista estática de configuración y, aun así, estar mal alineado con la forma en que los workloads lo usan en la realidad.
La pregunta útil no era ¿el clúster está bien configurado?, sino ¿la configuración del clúster está alineada con el patrón del workload? Eso desplazó la investigación de la revisión estática de la configuración hacia el comportamiento en runtime.
El clúster soportaba varios tipos de workloads:
- Dashboards de BI
- Analítica impulsada por aplicaciones
- Pipelines de batch y transformación
- Procesamiento de ML o vinculado a campañas
- Jobs programados de data engineering
Este patrón de uso mixto es común, pero exige un aislamiento cuidadoso de los workloads. Workload Management (WLM) de Redshift define colas de consultas y enruta el trabajo hacia esas colas en runtime. AWS lo documenta como el mecanismo para gestionar colas de consultas, prioridades y enrutamiento de workloads.
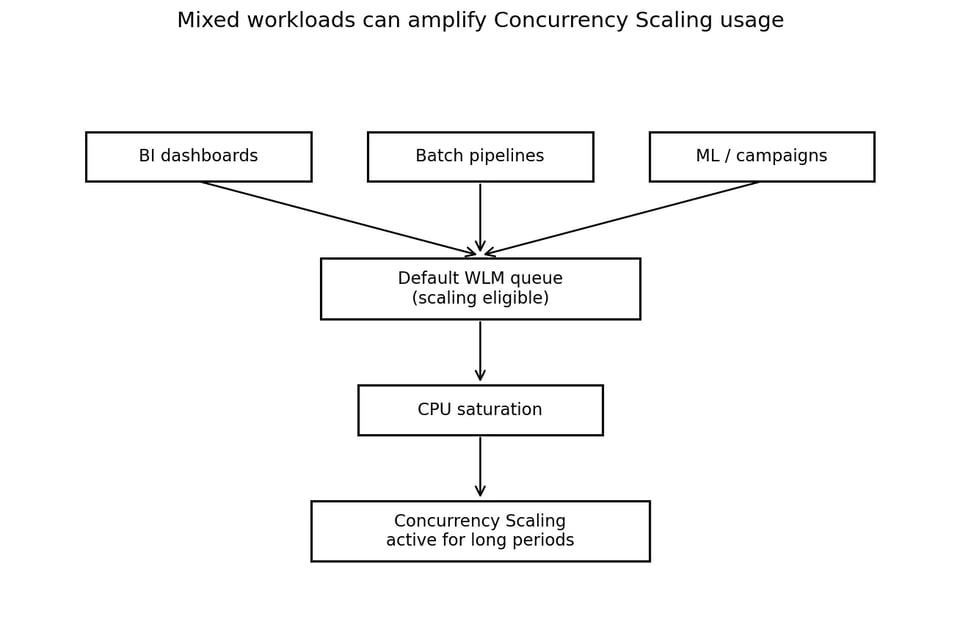
Cuando varios tipos de workloads comparten una sola cola apta para escalar, Concurrency Scaling deja de ser capacidad de pico.
Paso 3: Deja que CloudWatch cuente la historia
El siguiente paso fue revisar un conjunto acotado de métricas de CloudWatch para Redshift.
El objetivo era responder una sola pregunta: ¿este clúster estaba teniendo picos breves o presión sostenida?
Las métricas más útiles fueron:
CPUUtilizationConcurrencyScalingActiveClustersConcurrencyScalingSecondsDatabaseConnections- Utilización de disco
El patrón se hizo evidente rápido.
Ventana de alta actividad: 00:00 a 09:00 UTC
Este período mostraba las señales más fuertes de presión: la mayor utilización de CPU, los conteos más altos de conexiones a la base de datos, la actividad más sostenida de Concurrency Scaling y múltiples workloads superpuestos. Eso sugería que los workloads batch, de dashboards y de aplicaciones estaban colisionando en la misma franja horaria.
Ventana de horario laboral: 09:00 a 17:00 UTC
La actividad se mantenía elevada, aunque por lo general menor que en la ventana temprana. Probablemente impulsada por BI, uso de dashboards y analítica interactiva.
Ventana de baja actividad: 17:00 a 23:00 UTC
Este período mostraba más margen disponible: menor utilización de CPU, menos actividad de escalado y menor presión de conexiones. Eso la convertía en una candidata natural para reprogramar workloads batch o de transformación de menor prioridad.
Paso 4: Concurrency Scaling no se comportaba como capacidad de pico
El hallazgo más importante fue el patrón de Concurrency Scaling. El clúster no lo usaba solo durante picos breves: lo usaba la mayor parte del día, muchas veces con varios clústeres de escalado activos al mismo tiempo. En el período observado, Concurrency Scaling estuvo activo entre 18 y 20 horas por día, aproximadamente.
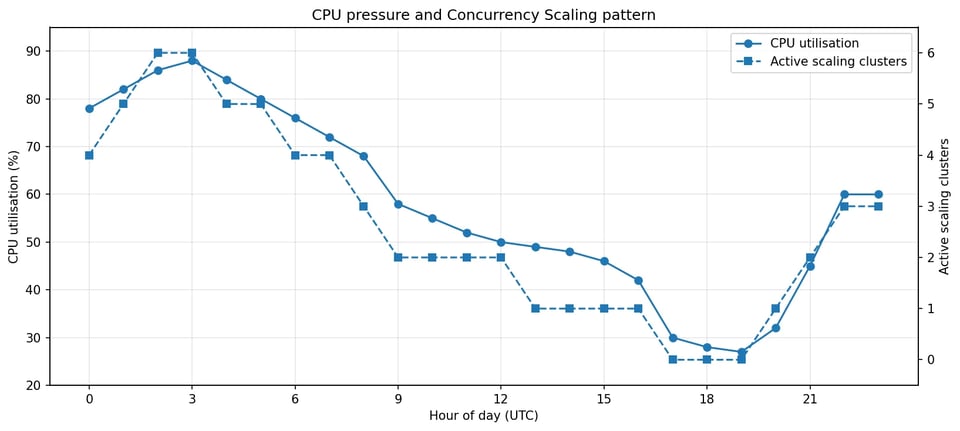
Concurrency Scaling acompañaba la presión de CPU durante la mayor parte del día, no solo durante los picos.
Eso cambió la naturaleza de la investigación. La pregunta ya no era ¿por qué Redshift escaló durante un pico?, sino ¿por qué este clúster necesita capacidad de desborde de forma sostenida?
El uso prolongado de Concurrency Scaling es una señal de que el workload puede estar desalineado con la capacidad base, con el enrutamiento de workloads o con la programación. En este punto, la investigación pasó de "encontrar el pico" a "entender la forma del workload".
Paso 5: Identifica el cuello de botella
El siguiente paso fue averiguar qué estaba causando realmente la presión de escalado. Hay varias posibilidades comunes:
- Saturación de CPU
- Tiempo de espera en cola
- Presión de disco
- Presión de I/O
- Presión de conexiones
- Enrutamiento deficiente de workloads
Las métricas apuntaban con fuerza a la CPU. La utilización se mantenía elevada, con picos frecuentes en las mismas ventanas en las que Concurrency Scaling estaba activo. La utilización de disco se mantenía saludable. El throughput de I/O y de red estaba activo, pero no parecía ser el cuello de botella principal.
Eso importa porque la solución para la saturación de CPU es distinta de la solución para la presión por encolamiento o por almacenamiento. El tiempo de espera en cola apunta a la configuración de WLM y a la asignación de slots. La presión de almacenamiento apunta al diseño de tablas, al ciclo de vida de los datos y al uso del almacenamiento gestionado. La presión de CPU apunta a la eficiencia de las consultas, a la programación de workloads, al aislamiento de colas y a la capacidad de cómputo base.
En este caso, el clúster estaba haciendo mucho trabajo, durante mucho tiempo, con muchos workloads compitiendo por CPU.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Paso 6: La cola de WLM era el amplificador de costo
El siguiente hallazgo estuvo en Workload Management. La configuración tenía varias colas definidas, pero Concurrency Scaling estaba habilitado en la cola Default Auto WLM, y esa cola también funcionaba como cajón de sastre para los workloads no enrutados de forma explícita a otra parte.
Esto generó un patrón simple, pero costoso:
Workloads sin clasificar o mixtos vCola Default Auto WLM (escalado habilitado) vPresión de CPU vConcurrency Scaling vMayor costo de cómputoEl problema no era que Auto WLM o Concurrency Scaling estuvieran "mal". Ambas son funcionalidades útiles de Redshift. El problema era que demasiado workload mixto fluía por la única cola que tenía acceso a capacidad de escalado.
El enrutamiento de WLM puede basarse en grupos de usuarios, grupos de consultas y reglas de clasificación relacionadas, lo que lo convierte en un punto de control clave para el aislamiento de workloads. Si los dashboards de BI, los jobs batch, los workloads de ML y las consultas de aplicaciones caen todos en la misma cola con escalado habilitado, Concurrency Scaling se vuelve una válvula de escape amplia en vez de una herramienta puntual.
Así es como los costos crecen en silencio.
Paso 7: Las conexiones no son lo mismo que la concurrencia activa
Otra observación útil tuvo que ver con las conexiones a la base de datos. El clúster mostraba picos regulares en el conteo de conexiones, llegando a veces a niveles altos durante las ventanas de mayor actividad. A primera vista, parecía un posible problema de límite de conexiones.
Pero las conexiones a la base de datos no son lo mismo que las consultas que se están ejecutando activamente. Un clúster de Redshift puede tener muchas conexiones establecidas mientras solo una parte del trabajo se ejecuta en un momento dado, según el workload management, la memoria, la CPU y la configuración de colas. Los conteos altos de conexiones siguen siendo una señal útil porque suelen indicar refrescos de dashboards, fan-out de aplicaciones o ráfagas de jobs. Por sí solos, no son prueba de concurrencia activa de consultas.
En esta investigación, los picos de conexiones fueron útiles porque coincidían con la presión de CPU y el uso de Concurrency Scaling. Eso los hizo parte de la historia, no la causa raíz por sí mismos.
La mejor conclusión: muchos clientes se estaban conectando y enviando trabajo en ventanas predecibles, y el clúster no tenía suficiente margen efectivo de cómputo para esa mezcla de workloads.
Paso 8: La visibilidad de las consultas depende de los privilegios en la base de datos
Al investigar el comportamiento de las consultas, las tablas y vistas del sistema de Redshift son esenciales. Un punto común de confusión es la visibilidad. En las vistas del sistema de Redshift, los superusuarios ven todas las filas, mientras que los usuarios regulares por lo general solo ven sus propios datos. AWS documenta esta regla de visibilidad para vistas como SYS_QUERY_HISTORY, STL_WLM_QUERY, STL_QUERY_METRICS y otras vistas de monitoreo relacionadas.
Para el análisis de workloads a nivel del clúster, quien ejecuta las consultas necesita los permisos adecuados en la base de datos.
Algunas preguntas útiles para responder:
- ¿Qué usuarios consumen más tiempo de ejecución?
- ¿Qué consultas corren durante la ventana de alta actividad?
- ¿Qué workloads usan Concurrency Scaling?
- ¿Qué colas reciben la mayor parte del trabajo?
- ¿Qué consultas se repiten con la frecuencia suficiente como para que valga la pena optimizarlas?
Cuando están disponibles, AWS recomienda las vistas de monitoreo más nuevas SYS porque tienen un formato más fácil de usar y entender. Las vistas más antiguas STL y SVL se siguen usando bastante y son útiles para investigaciones, pero las SYS son un punto de partida más limpio cuando cubren lo que necesitas.
Top de consultas por tiempo de ejecución
SELECT h.user_id, u.usename AS user_name, h.query_id, h.query_type, h.status, h.start_time, h.end_time, h.elapsed_time / 1000000.0 AS elapsed_seconds, h.execution_time / 1000000.0 AS execution_seconds, h.queue_time / 1000000.0 AS queue_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY h.execution_time DESCLIMIT 50;Top de usuarios por tiempo total de ejecución
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, COUNT(*) AS query_count, SUM(h.execution_time) / 1000000.0 AS total_execution_seconds, SUM(h.queue_time) / 1000000.0 AS total_queue_secondsFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)GROUP BY h.user_id, u.usenameORDER BY total_execution_seconds DESC;Top de consultas por tiempo de CPU
SVL_QUERY_METRICS_SUMMARY es útil acá porque incluye query_cpu_time, query_blocks_read y métricas relacionadas para consultas completadas. AWS documenta query_cpu_time como el tiempo de CPU usado por la consulta, en segundos.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.service_class_name, h.compute_type, m.query_cpu_time, m.query_execution_time, m.query_blocks_read, m.query_temp_blocks_to_disk, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hJOIN svl_query_metrics_summary m ON h.query_id = m.queryLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY m.query_cpu_time DESCLIMIT 50;Uso de las colas de WLM
SELECT service_class_name, compute_type, COUNT(*) AS query_count, SUM(queue_time) / 1000000.0 AS total_queue_seconds, SUM(execution_time) / 1000000.0 AS total_execution_seconds, AVG(queue_time) / 1000000.0 AS avg_queue_seconds, AVG(execution_time) / 1000000.0 AS avg_execution_secondsFROM sys_query_historyWHERE start_time >= dateadd(day, -7, current_date)GROUP BY service_class_name, compute_typeORDER BY total_execution_seconds DESC;Consultas que se ejecutaron en Concurrency Scaling
En SYS_QUERY_HISTORY, la columna compute_type indica si una consulta se ejecutó en el clúster principal o en un clúster de Concurrency Scaling, para clústeres de Redshift aprovisionados. AWS documenta primary-scale como el tipo de cómputo para una consulta que corre en un clúster de concurrencia.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.end_time, h.execution_time / 1000000.0 AS execution_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date) AND h.compute_type = 'primary-scale'ORDER BY h.start_time DESCLIMIT 100;Estas consultas no son el final de la optimización. Son el comienzo de la priorización. La idea es dejar de adivinar e identificar qué workloads habría que aislar, reprogramar, ajustar o dejar que usen escalado.
Paso 9: Plan de remediación recomendado
Una vez que el patrón quedó claro, el plan de remediación fue directo. El objetivo no era apagar Concurrency Scaling a ciegas. Eso probablemente reduciría el costo, pero también podría aumentar el encolamiento y ralentizar workloads importantes.
Un enfoque más seguro es por fases, empezando por cambios de enrutamiento de bajo riesgo y avanzando hacia decisiones que cuesta más revertir.
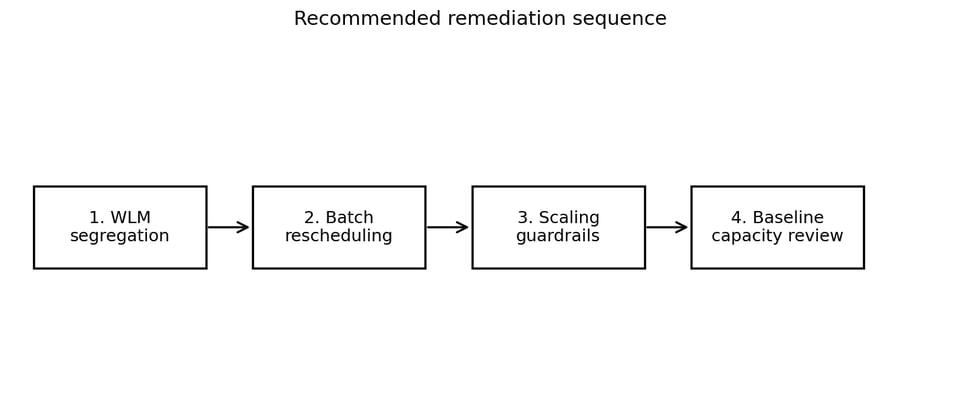
Un orden por fases mantiene los primeros pasos baratos y reversibles.
1. Segrega los workloads con WLM
WLM debería reflejar la prioridad de cada workload. Por ejemplo:
| Tipo de workload | Tratamiento posible |
|---|---|
| Dashboards de BI | Mayor prioridad, acceso limitado a escalado |
| Consultas críticas de aplicaciones | Mayor prioridad, cola protegida |
| Jobs batch | Cola dedicada, normalmente sin escalado |
| Workloads de ML o transformación | Cola dedicada, programados cuando se pueda |
| Análisis ad hoc | Menor prioridad o escalado restringido |
Esto evita que el trabajo batch de menor prioridad consuma el mismo pool de escalado que las consultas interactivas o críticas para el negocio. Es un cambio de enrutamiento, así que se puede revertir rápido si un límite de cola está mal.
2. Mueve los jobs batch a ventanas de baja actividad
Las métricas mostraron una ventana clara de baja actividad al final del día, lo que abre una palanca operativa inmediata.
No todo job batch necesita correr durante el período más ocupado. Mover jobs de transformación, ML o reporting de menor prioridad a ventanas más tranquilas puede reducir la presión pico de CPU sin cambiar el tamaño del clúster. Suele ser una de las palancas de costo más prácticas porque cambia el timing, no la arquitectura.
3. Suma guardrails a Concurrency Scaling
Con los workloads bien enrutados y temporizados, el siguiente paso es ponerle un tope al propio Concurrency Scaling. Si se le permite escalar sin límite, puede proteger el rendimiento, pero genera un costo impredecible.
Un primer paso razonable es reducir el número máximo de clústeres de escalado permitidos a un nivel controlado y observar el impacto. Eso ayuda a responder:
- ¿Qué workloads empiezan a esperar?
- ¿Qué jobs son realmente sensibles a la latencia?
- ¿Qué workloads dependían de la capacidad de escalado sin una razón de negocio?
El punto no es degradar el rendimiento, sino que el escalado sea un recurso intencional, no un valor por defecto ilimitado.
4. Revisa la capacidad base
Si Concurrency Scaling sigue activo durante períodos prolongados después de los cambios de WLM y de programación, puede que el clúster base simplemente esté subdimensionado para el workload. En ese caso, sumar capacidad base puede salir más barato que apoyarse de manera continua en la capacidad de desborde.
Es contraintuitivo, pero común: aumentar la capacidad base puede reducir el costo total si recorta de forma significativa el uso sostenido de Concurrency Scaling.
La clave es tomar esta decisión después de haber mejorado el aislamiento y la programación de los workloads. Si no, corres el riesgo de sumar nodos mientras sigue habiendo un enrutamiento ineficiente que consume capacidad de escalado.
5. Optimiza consultas con evidencia
La optimización de consultas debería enfocarse en los workloads que más pesan:
- Alto tiempo total de ejecución
- Alto consumo de CPU
- Ejecución repetida con frecuencia
- Ejecución durante ventanas de alta actividad
- Consultas que caen en colas con escalado habilitado
Acá es donde el análisis de las tablas del sistema se vuelve útil. Optimiza las consultas que impactan de verdad en el costo y el rendimiento, no las que simplemente se ven feas.
Conclusiones clave
Esta investigación reforzó algunas lecciones prácticas sobre Redshift.
Concurrency Scaling no debería convertirse en capacidad base. Si está activo la mayor parte del día, ya no se comporta como capacidad de pico. Pasó a formar parte del modelo de cómputo de estado estable, y eso es una señal de costo.
La presión de CPU y la presión de cola son problemas distintos. Un uso alto de Concurrency Scaling no significa automáticamente que el encolamiento de WLM sea la causa raíz. Revisa en conjunto CPU, tiempo de espera en cola, disco, I/O y patrones de conexiones.
El enrutamiento por la cola por defecto puede salir caro. Una cola cajón de sastre con Concurrency Scaling habilitado puede volverse, sin que nadie lo note, el principal amplificador de costos. El enrutamiento de WLM debería coincidir con la prioridad de cada workload.
El timing de los workloads importa. Si jobs batch, dashboards, workloads de ML y analítica de aplicaciones se superponen, la presión de escalado aumenta. Mover workloads batch no críticos a ventanas más tranquilas puede reducir el costo sin cambiar la funcionalidad.
El tuning de consultas debería venir después de la atribución. Antes de ajustar consultas, identifica qué usuarios, workloads y colas están impulsando el consumo de recursos. Adivinar suele ser perder el tiempo.
Reflexiones finales
La optimización de costos en Redshift rara vez se reduce a un solo ajuste. En este caso, el problema no era un clúster roto ni una única consulta mala. Era una combinación de workloads mixtos, colisiones de timing predecibles, saturación de CPU y acceso amplio a Concurrency Scaling a través de la ruta por defecto de WLM.
La parte más útil de la investigación no fue ninguna métrica individual, sino conectarlas:
- El reporte de costos identifica el clúster
- CloudWatch muestra el escalado sostenido y la presión de CPU
- La configuración de WLM explica por qué el escalado está ampliamente disponible
- Las tablas del sistema identifican qué usuarios y consultas priorizar
Si tu factura de Redshift no para de crecer y Concurrency Scaling pasó silenciosamente de ser capacidad de pico a capacidad base, no eres el único. Este es el tipo de investigación de costos que DoiT lleva adelante con clientes de AWS todas las semanas. Nuestro equipo de más de 100 expertos en la nube puede ayudarte a detectar los factores que impulsan el costo, segregar workloads y devolver Concurrency Scaling al lugar que le corresponde. Contáctanos.