Cloud Intelligence™
Costi di Concurrency Scaling di Amazon Redshift fuori controllo? Ecco come rimetterli in riga
Questa pagina è disponibile anche in English, Deutsch, Español, Français, 日本語 e Português.









About Joseph Allam
Databases have been my craft for a long time — long before the cloud, and deep into it across AWS and GCP. I know what breaks, what costs too much, and what needs rethinking before it hurts. I also know how to bring AI into the work: into how databases are designed, operated, and accessed by the intelligent systems being built on top of them.
My personal pageGli aumenti imprevisti dei costi di Amazon Redshift, a prima vista, sembrano spesso picchi isolati. Nella pratica, sono quasi sempre causati da pattern di workloads che spingono il Concurrency Scaling ben oltre il ruolo per cui è stato pensato, e lo fanno senza farsi notare.
Il Concurrency Scaling nasce per aggiungere capacità a Redshift quando la domanda di query cresce, e per rimuoverla quando la domanda cala. È utile per gestire i picchi. Se però resta attivo per lunghi periodi, smette di comportarsi come capacità di overflow e inizia a comportarsi come compute di base. E questo cambia il profilo di costo del workload.
In questo articolo ripercorriamo un'indagine su Redshift ispirata a un caso reale, in cui una spesa elevata sembrava all'inizio una normale crescita del workload. Un'analisi più approfondita dei dati di fatturazione, della configurazione del cluster e delle metriche CloudWatch ha fatto emergere un pattern diverso: workloads misti condividevano lo stesso cluster, generando una pressione costante sulla CPU e attivando il Concurrency Scaling per gran parte della giornata.
Vedremo insieme l'indagine, le metriche che hanno fatto la differenza, le scelte di configurazione che hanno amplificato i costi e il piano di intervento.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Cosa porta a casa chi legge questo articolo
Alla fine della lettura avrà a disposizione un workflow pratico per:
- Capire quale cluster Redshift sta trainando i costi
- Distinguere la pressione sulla CPU da quella sulle code
- Riconoscere quando il Concurrency Scaling viene usato come capacità di base
- Individuare problemi di routing WLM che gonfiano i costi
- Costruire un piano di intervento per fasi
Passo 1: individuare il driver di costo prima di toccare qualunque cosa
Quando i costi di Redshift salgono in modo inatteso, la tentazione è buttarsi subito sul tuning delle query o sul ridimensionamento del cluster. È un approccio rischioso. Il tuning può aiutare e il ridimensionamento può rendersi necessario più avanti, ma né l'uno né l'altro dovrebbero essere la prima mossa.
La prima domanda è molto più semplice:
Quale risorsa Redshift è davvero all'origine dell'aumento?
In questa indagine l'ambiente contava due cluster Redshift provisioned:
| Cluster | Ruolo | Andamento dei costi |
|---|---|---|
analytics-production-cluster |
Workloads principali di analytics, BI, applicazioni, batch e ML | Costo elevato e alta variabilità |
batch-processing-cluster |
Workload batch dedicato / monoscopo | Stabile e prevedibile |
I dati di fatturazione mostravano che quasi tutta la spesa e la variabilità arrivavano dal cluster analytics a uso misto. Il cluster più piccolo, orientato al batch, presentava costi stabili, scarsa attività di connessione e nessun utilizzo del Concurrency Scaling.
Una distinzione tutt'altro che secondaria: ha permesso di restringere subito il campo dell'indagine ed evitare di perdere tempo su un cluster che non contribuiva in modo rilevante al problema.
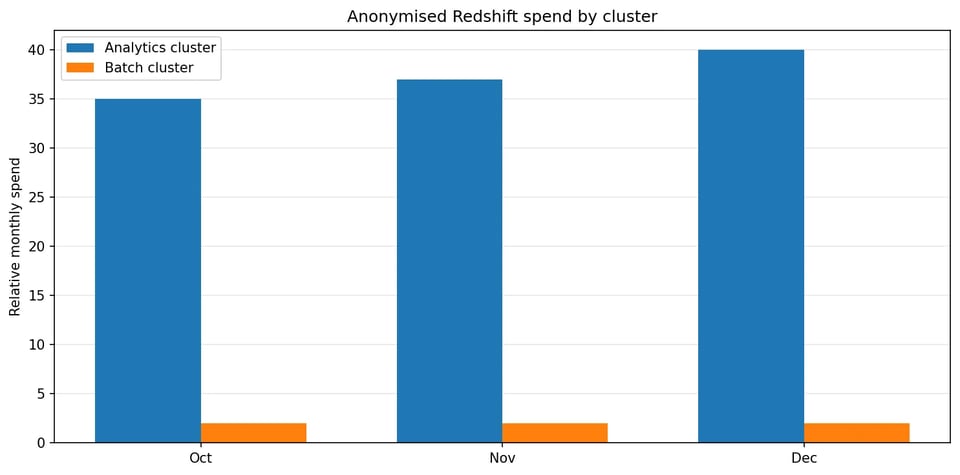
Quasi tutta la variabilità di spesa proveniva da un unico cluster analytics a uso misto.
I dati di costo mostravano inoltre che le oscillazioni più ampie erano legate al comportamento di compute e scaling, e non alla crescita dello storage. Questo ha spostato il focus sul comportamento a runtime, sulla pressione della CPU e sull'attività di scaling.
L'ipotesi di lavoro era semplice: il cluster analytics si stava appoggiando a capacità di compute aggiuntiva per periodi più lunghi del previsto.
Passo 2: partire dall'assetto del cluster
Identificato il cluster responsabile dei costi, il passo successivo è stato analizzarne l'assetto.
Il cluster usava nodi RA3, managed storage, Workload Management e Concurrency Scaling. A livello di configurazione, nulla appariva chiaramente sbagliato. Vale la pena fermarsi qui un momento. Un cluster Redshift può sembrare ragionevole da una semplice lettura statica della configurazione e, allo stesso tempo, risultare poco allineato a come i workloads lo usano davvero.
La domanda giusta non era il cluster è configurato correttamente?, ma la configurazione del cluster è allineata al pattern dei workloads?. Questo ha spostato l'indagine dalla revisione statica della configurazione al comportamento a runtime.
Sul cluster convivevano diversi tipi di workload:
- Dashboard BI
- Analytics applicative
- Pipeline batch e di trasformazione
- Elaborazioni ML o legate a campagne
- Job pianificati di data engineering
Si tratta di un pattern a uso misto molto comune, ma richiede un attento isolamento dei workloads. Il Workload Management (WLM) di Redshift definisce le code di query e instrada il lavoro al loro interno a runtime. AWS descrive il WLM come il meccanismo per gestire code di query, priorità e routing dei workloads.
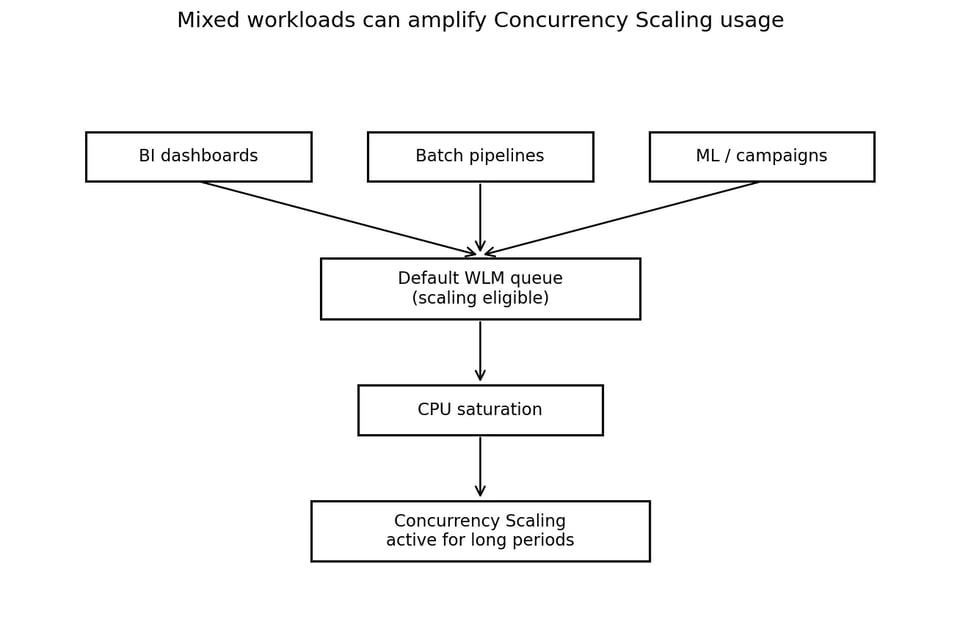
Quando diversi tipi di workload condividono un'unica coda abilitata allo scaling, il Concurrency Scaling smette di essere capacità di burst.
Passo 3: lasciar parlare CloudWatch
Il passo successivo è stato esaminare un piccolo set di metriche CloudWatch per Redshift.
L'obiettivo era rispondere a una sola domanda: il cluster stava vivendo picchi brevi o una pressione prolungata?
Le metriche più utili sono state:
CPUUtilizationConcurrencyScalingActiveClustersConcurrencyScalingSecondsDatabaseConnections- Utilizzo del disco
Il pattern è emerso in fretta.
Finestra ad alto carico: 00:00 - 09:00 UTC
È il periodo con i segnali di pressione più forti: utilizzo della CPU al massimo, numero di connessioni al database al massimo, attività di Concurrency Scaling più prolungata e più workloads sovrapposti. Tutto faceva pensare a workloads batch, di dashboard e applicativi in collisione nella stessa finestra temporale.
Finestra in orario d'ufficio: 09:00 - 17:00 UTC
L'attività restava elevata, anche se in genere più bassa rispetto alla prima finestra. Era probabilmente trainata da BI, utilizzo delle dashboard e analytics interattive.
Finestra a basso carico: 17:00 - 23:00 UTC
In questo periodo emergevano margini più ampi: utilizzo della CPU più basso, attività di scaling ridotta, minore pressione sulle connessioni. Un candidato naturale per riprogrammare i workloads batch o di trasformazione a priorità più bassa.
Passo 4: il Concurrency Scaling non si comportava da capacità di burst
L'evidenza più rilevante riguardava proprio il pattern del Concurrency Scaling. Il cluster non lo usava solo durante brevi picchi: lo usava per gran parte della giornata, spesso con più cluster di scaling attivi contemporaneamente. Nel periodo osservato, il Concurrency Scaling è rimasto attivo per circa 18-20 ore al giorno.
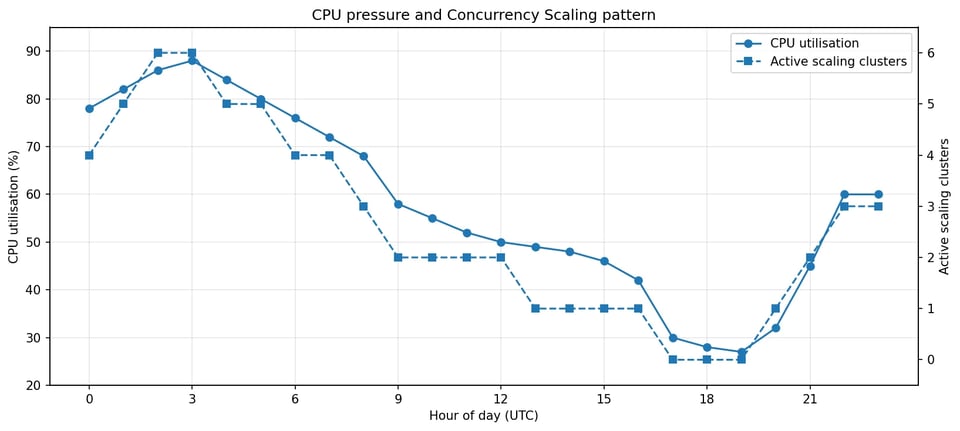
Il Concurrency Scaling seguiva la pressione sulla CPU per gran parte della giornata, non solo durante i picchi.
Questo ha cambiato la natura dell'indagine. La domanda non era più perché Redshift ha scalato durante un picco?, ma perché questo cluster ha bisogno di capacità di overflow in modo continuativo?.
Un utilizzo prolungato del Concurrency Scaling segnala che il workload potrebbe non essere allineato a capacità di base, routing dei workloads o pianificazione. A quel punto l'indagine è passata da "trovare il picco" a "capire la forma del workload".
Passo 5: individuare il collo di bottiglia
Il passo successivo è stato capire cosa stesse davvero generando la pressione sullo scaling. Le possibilità più comuni sono diverse:
- Saturazione della CPU
- Tempo di attesa in coda
- Pressione sul disco
- Pressione I/O
- Pressione sulle connessioni
- Routing dei workloads inefficace
Le metriche puntavano con decisione alla CPU. L'utilizzo restava elevato, con picchi frequenti nelle stesse finestre in cui era attivo il Concurrency Scaling. L'utilizzo del disco era nella norma. I/O e throughput di rete erano attivi, ma non sembravano essere il collo di bottiglia principale.
Un dettaglio rilevante, perché la soluzione per la saturazione della CPU è diversa da quella per la pressione su code o storage. Il tempo di attesa in coda rimanda alla configurazione del WLM e all'allocazione degli slot. La pressione sullo storage rimanda al design delle tabelle, al ciclo di vita dei dati e all'uso del managed storage. La pressione sulla CPU rimanda all'efficienza delle query, alla pianificazione dei workloads, all'isolamento delle code e alla capacità di compute di base.
In questo caso, il cluster stava facendo molto lavoro, per molto tempo, con molti workloads in competizione per la CPU.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Passo 6: la coda WLM era l'amplificatore di costi
L'evidenza successiva è arrivata dal Workload Management. La configurazione prevedeva più code definite, ma il Concurrency Scaling era abilitato sulla coda Default Auto WLM, che fungeva anche da catch-all per i workloads non instradati esplicitamente altrove.
Si creava così un pattern semplice ma costoso:
Workloads non classificati o misti vCoda Default Auto WLM (scaling abilitato) vPressione sulla CPU vConcurrency Scaling vCosto di compute più elevatoIl problema non era che Auto WLM o Concurrency Scaling fossero "sbagliati": sono entrambe funzionalità utili di Redshift. Il problema era che troppi workloads misti passavano dall'unica coda con accesso alla capacità di scaling.
Il routing WLM può basarsi su user groups, query groups e regole di classificazione correlate, e questo lo rende un punto di controllo chiave per l'isolamento dei workloads. Se dashboard BI, job batch, workloads ML e query applicative finiscono tutti nella stessa coda abilitata allo scaling, il Concurrency Scaling diventa una via di fuga generica invece di uno strumento mirato.
È così che i costi crescono senza farsi notare.
Passo 7: le connessioni non equivalgono alla concorrenza attiva
Un'altra osservazione interessante ha riguardato le connessioni al database. Il cluster mostrava picchi regolari nel numero di connessioni, con valori a volte molto alti nelle finestre di carico maggiore. A prima vista sembrava un possibile problema di limite di connessioni.
Ma le connessioni al database non sono la stessa cosa delle query in esecuzione. Un cluster Redshift può avere molte connessioni aperte mentre, in un dato momento, viene eseguita solo una parte del lavoro, in funzione di workload management, memoria, CPU e configurazione delle code. Un numero elevato di connessioni resta comunque un segnale utile, perché spesso indica refresh delle dashboard, fan-out applicativi o burst di job. Di per sé, però, non è prova di concorrenza attiva delle query.
In questa indagine i picchi di connessioni sono stati utili perché coincidevano con la pressione sulla CPU e con l'uso del Concurrency Scaling. Erano un pezzo della storia, non la causa radice.
La conclusione più solida è un'altra: molti client si connettevano e inviavano lavoro in finestre prevedibili, e il cluster non aveva margine di compute effettivo sufficiente per quel mix di workloads.
Passo 8: la visibilità delle query dipende dai privilegi sul database
Quando si analizza il comportamento delle query, le tabelle e le viste di sistema di Redshift sono fondamentali. Un equivoco frequente riguarda proprio la visibilità delle query. Nelle viste di sistema di Redshift, i superuser vedono tutte le righe, mentre gli utenti normali in genere vedono solo i propri dati. AWS riporta questa regola di visibilità per viste come SYS_QUERY_HISTORY, STL_WLM_QUERY, STL_QUERY_METRICS e altre viste di monitoraggio correlate.
Per un'analisi dei workloads a livello di cluster, chi esegue le query deve disporre dei permessi giusti sul database.
Tra le domande utili a cui rispondere:
- Quali utenti consumano più tempo di esecuzione?
- Quali query girano durante la finestra di alto carico?
- Quali workloads usano il Concurrency Scaling?
- Quali code ricevono la maggior parte del lavoro?
- Quali query si ripetono abbastanza spesso da meritare un'ottimizzazione?
Dove disponibili, AWS consiglia di usare le nuove viste di monitoraggio SYS, pensate per essere più semplici da leggere e interpretare. Le viste più vecchie STL e SVL sono ancora ampiamente usate e utili per le indagini, ma le SYS sono un punto di partenza più pulito quando coprono ciò che serve.
Top query per tempo di esecuzione
SELECT h.user_id, u.usename AS user_name, h.query_id, h.query_type, h.status, h.start_time, h.end_time, h.elapsed_time / 1000000.0 AS elapsed_seconds, h.execution_time / 1000000.0 AS execution_seconds, h.queue_time / 1000000.0 AS queue_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY h.execution_time DESCLIMIT 50;Top utenti per tempo totale di esecuzione
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, COUNT(*) AS query_count, SUM(h.execution_time) / 1000000.0 AS total_execution_seconds, SUM(h.queue_time) / 1000000.0 AS total_queue_secondsFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)GROUP BY h.user_id, u.usenameORDER BY total_execution_seconds DESC;Top query per tempo di CPU
In questo caso è utile SVL_QUERY_METRICS_SUMMARY, perché include query_cpu_time, query_blocks_read e altre metriche correlate per le query completate. AWS documenta query_cpu_time come tempo di CPU usato dalla query, espresso in secondi.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.service_class_name, h.compute_type, m.query_cpu_time, m.query_execution_time, m.query_blocks_read, m.query_temp_blocks_to_disk, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hJOIN svl_query_metrics_summary m ON h.query_id = m.queryLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY m.query_cpu_time DESCLIMIT 50;Utilizzo delle code WLM
SELECT service_class_name, compute_type, COUNT(*) AS query_count, SUM(queue_time) / 1000000.0 AS total_queue_seconds, SUM(execution_time) / 1000000.0 AS total_execution_seconds, AVG(queue_time) / 1000000.0 AS avg_queue_seconds, AVG(execution_time) / 1000000.0 AS avg_execution_secondsFROM sys_query_historyWHERE start_time >= dateadd(day, -7, current_date)GROUP BY service_class_name, compute_typeORDER BY total_execution_seconds DESC;Query eseguite su Concurrency Scaling
In SYS_QUERY_HISTORY, la colonna compute_type indica se una query è stata eseguita sul cluster principale o su un cluster di Concurrency Scaling, nel caso dei cluster Redshift provisioned. AWS documenta primary-scale come compute type di una query eseguita su un cluster di concorrenza.
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.end_time, h.execution_time / 1000000.0 AS execution_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date) AND h.compute_type = 'primary-scale'ORDER BY h.start_time DESCLIMIT 100;Queste query non sono il punto di arrivo dell'ottimizzazione, ma il punto di partenza della prioritizzazione. L'obiettivo è smettere di andare a tentativi e capire quali workloads vadano isolati, riprogrammati, ottimizzati o autorizzati a usare lo scaling.
Passo 9: piano di intervento consigliato
Chiarito il pattern, il piano di intervento è diventato lineare. L'obiettivo non era disattivare il Concurrency Scaling alla cieca: avrebbe probabilmente ridotto i costi, ma rischiava anche di aumentare l'attesa in coda e rallentare workloads importanti.
Un approccio più sicuro procede per fasi, partendo da modifiche di routing a basso rischio e arrivando alle decisioni più onerose da invertire.
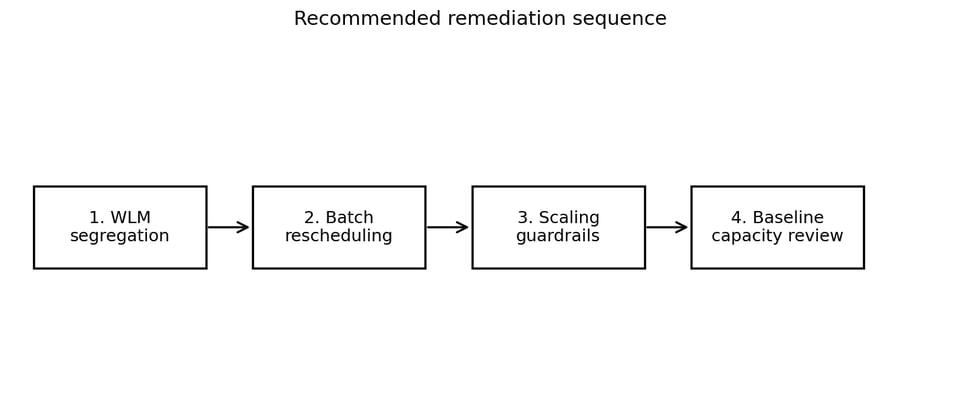
Procedere per fasi consente di mantenere i primi passi economici e reversibili.
1. Separare i workloads con il WLM
Il WLM dovrebbe riflettere la priorità dei workloads. Per esempio:
| Tipo di workload | Possibile trattamento |
|---|---|
| Dashboard BI | Priorità più alta, accesso allo scaling limitato |
| Query applicative critiche | Priorità più alta, coda protetta |
| Job batch | Coda dedicata, spesso senza scaling |
| Workloads ML o di trasformazione | Coda dedicata, pianificati quando possibile |
| Analisi ad hoc | Priorità più bassa o scaling limitato |
In questo modo si evita che il lavoro batch a priorità più bassa consumi lo stesso pool di scaling delle query interattive o business-critical. È un cambio di routing, quindi può essere annullato in fretta se il confine di una coda risulta sbagliato.
2. Spostare i job batch nelle finestre a basso carico
Le metriche mostravano una chiara finestra a basso carico nella seconda parte della giornata: una leva operativa immediata.
Non tutti i job batch devono girare nella fascia più affollata. Spostare job di trasformazione, ML o reporting a priorità più bassa nelle finestre più tranquille può ridurre i picchi di pressione sulla CPU senza modificare la dimensione del cluster. Spesso è una delle leve di costo più pratiche, perché cambia la tempistica, non l'architettura.
3. Aggiungere guardrail al Concurrency Scaling
Una volta che i workloads sono instradati e schedulati correttamente, il passo successivo è mettere un tetto al Concurrency Scaling stesso. Se può scalare in modo troppo ampio, può proteggere le prestazioni ma generare costi imprevedibili.
Un primo passo ragionevole è ridurre il numero massimo di cluster di scaling consentiti a un livello controllato e osservare l'impatto. Questo aiuta a rispondere a:
- Quali workloads iniziano ad attendere?
- Quali job sono davvero sensibili alla latenza?
- Quali workloads si appoggiavano alla capacità di scaling senza una vera ragione di business?
L'obiettivo non è peggiorare le prestazioni, ma fare dello scaling una risorsa intenzionale e non un default illimitato.
4. Rivedere la capacità di base
Se il Concurrency Scaling resta attivo per lunghi periodi anche dopo gli interventi su WLM e pianificazione, il cluster di base è probabilmente sottodimensionato per il workload. In quel caso, aumentare la capacità di base può costare meno che appoggiarsi continuamente alla capacità di overflow.
È controintuitivo ma frequente: aumentare la capacità di base può ridurre il costo totale, se abbatte in modo significativo l'uso prolungato del Concurrency Scaling.
La cosa importante è prendere questa decisione dopo aver migliorato isolamento dei workloads e pianificazione. Altrimenti si rischia di aggiungere nodi mentre un routing inefficiente continua a consumare capacità di scaling.
5. Ottimizzare le query partendo dai dati
L'ottimizzazione delle query dovrebbe concentrarsi sui workloads che pesano davvero:
- Tempo totale di esecuzione elevato
- Consumo di CPU elevato
- Esecuzioni ripetute frequenti
- Esecuzioni nelle finestre di alto carico
- Query che finiscono in code abilitate allo scaling
È qui che l'analisi delle tabelle di sistema diventa preziosa. Ottimizzi le query che incidono realmente su costi e prestazioni, non quelle che semplicemente "sembrano brutte".
Punti chiave
Questa indagine ha riportato a galla alcune lezioni pratiche su Redshift.
Il Concurrency Scaling non dovrebbe diventare capacità di base. Se è attivo per gran parte della giornata, non si comporta più da capacità di burst: è diventato parte del modello di compute a regime, ed è un segnale di costo.
Pressione sulla CPU e pressione sulle code sono problemi diversi. Un uso elevato del Concurrency Scaling non significa automaticamente che le code WLM siano la causa radice. Vanno analizzati insieme CPU, tempo di attesa in coda, disco, I/O e pattern di connessione.
Il routing verso la coda di default può uscire caro. Una coda catch-all con Concurrency Scaling abilitato può diventare, senza farsi notare, il principale amplificatore di costi. Il routing WLM deve rispecchiare la priorità dei workloads.
La tempistica dei workloads conta. Se job batch, dashboard, workloads ML e analytics applicative si sovrappongono, la pressione sullo scaling cresce. Spostare i workloads batch non critici in finestre più tranquille può ridurre i costi senza intaccare le funzionalità.
Il tuning delle query viene dopo l'attribuzione. Prima di ottimizzare le query, occorre identificare quali utenti, workloads e code stanno trainando il consumo di risorse. Andare a tentativi, di solito, è solo tempo perso.
Riflessioni conclusive
L'ottimizzazione dei costi di Redshift raramente si riduce a una singola impostazione. In questo caso il problema non era un cluster guasto o una singola query mal scritta, ma una combinazione di workloads misti, collisioni temporali prevedibili, saturazione della CPU e accesso troppo ampio al Concurrency Scaling attraverso il percorso WLM di default.
La parte più utile dell'indagine non è stata una singola metrica, ma il fatto di metterle in relazione tra loro:
- Il report dei costi individua il cluster
- CloudWatch mostra scaling prolungato e pressione sulla CPU
- La configurazione WLM spiega perché lo scaling è così disponibile
- Le tabelle di sistema indicano quali utenti e query mettere in cima alla lista
Se la bolletta Redshift continua a salire e il Concurrency Scaling è passato senza farsi notare da capacità di burst a capacità di base, non è un caso isolato. È esattamente il tipo di indagine sui costi che DoiT conduce ogni settimana con i clienti AWS. Il nostro team di oltre 100 esperti cloud può aiutarla a individuare i driver, separare i workloads e riportare il Concurrency Scaling al ruolo che gli compete. Ci contatti.