Cloud Intelligence™
Amazon Redshiftの同時実行スケーリング費用が膨らみ続ける理由と解決策
このページはEnglish、Deutsch、Español、Français、Italiano、Portuguêsでもご覧いただけます。









About Joseph Allam
Databases have been my craft for a long time — long before the cloud, and deep into it across AWS and GCP. I know what breaks, what costs too much, and what needs rethinking before it hurts. I also know how to bring AI into the work: into how databases are designed, operated, and accessed by the intelligent systems being built on top of them.
My personal pageAmazon Redshiftのコストが想定外に跳ね上がるとき、最初は単発のスパイクに見えることがほとんどです。しかし実際の原因は、同時実行スケーリング(Concurrency Scaling)を本来の役割を超えて使い込んでしまうワークロードパターンであるケースが大半です。
同時実行スケーリングは、クエリ需要が増えたときにRedshiftの容量を追加し、需要が落ち着けば容量を解放する仕組みです。バースト対応には有効ですが、長時間にわたって稼働し続けるようになると、オーバーフロー容量というより、もはやベースコンピュートのように振る舞い始めます。これにより、ワークロード全体のコスト構造が変わってしまうのです。
本記事では、当初は通常のワークロード増加に見えていたRedshiftのコスト上昇を題材に、実例ベースの調査プロセスを紹介します。請求データ、クラスター構成、CloudWatchメトリクスを精査したところ、別のパターンが浮かび上がりました。混在するワークロードが同一クラスターを共有し、CPUに継続的な負荷がかかり、ほぼ一日中、同時実行スケーリングが作動していたのです。
調査の流れ、注目すべきメトリクス、コストを押し上げた構成上の判断、そして改善計画について、順を追って見ていきます。
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
本記事で得られること
読み終える頃には、以下を実践的に進められるようになっているはずです。
- コストを押し上げているRedshiftクラスターを特定する
- CPU負荷とキュー待機の負荷を切り分ける
- 同時実行スケーリングがベース容量として使われている兆候を見抜く
- コストを増幅させるWLMのルーティング問題を発見する
- 段階的な改善計画を組み立てる
ステップ1:何かを変える前に、コストの原因を見極める
Redshiftのコストが想定外に上昇すると、ついクエリチューニングやクラスターのリサイズに飛びつきたくなります。しかし、これはリスクの高い対応です。クエリチューニングは有効ですし、最終的にリサイズが必要になることもありますが、いずれも最初の一手にすべきではありません。
まず問うべきは、もっとシンプルな質問です。
コスト上昇の原因となっているRedshiftリソースは、実際にどれなのか?
今回の調査対象環境には、プロビジョン済みのRedshiftクラスターが2つありました。
| クラスター | 役割 | コストの傾向 |
|---|---|---|
analytics-production-cluster |
メインの分析、BI、アプリケーション、バッチ、MLワークロード | 高コストかつ変動が大きい |
batch-processing-cluster |
専用バッチ/単一用途ワークロード | 安定しており予測しやすい |
請求データを見ると、支出と変動のほぼすべてが混在用途の分析クラスターに集中していました。もう一方の小規模なバッチ向けクラスターはコストが安定しており、接続のアクティビティも少なく、同時実行スケーリングは一切使われていませんでした。
この切り分けは重要でした。調査範囲を素早く絞り込め、問題に実質的に寄与していないクラスターに時間を費やすのを避けられたからです。
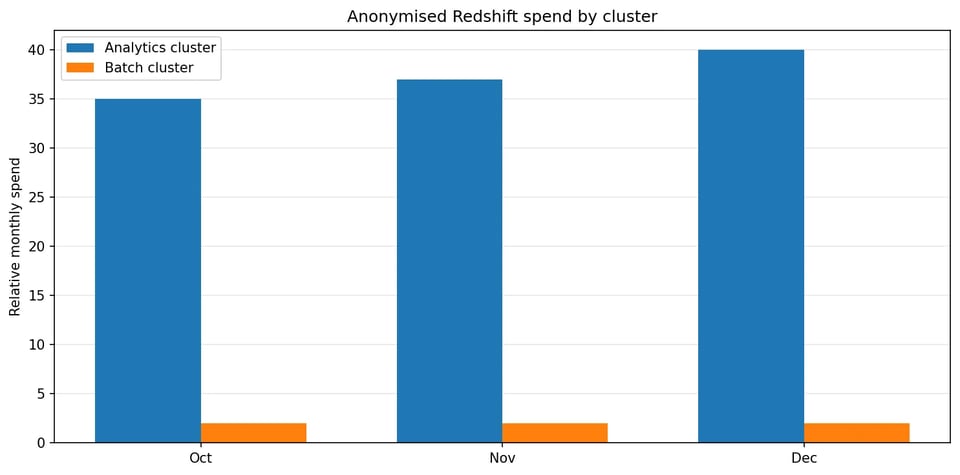
支出変動のほぼすべては、1つの混在用途の分析クラスターから生じていました。
コストデータからは、最大の変動がストレージ増加ではなく、コンピュートとスケーリング挙動に紐づいていることも分かりました。これにより、調査の焦点は実行時の挙動、CPU負荷、スケーリング活動へと移りました。
作業仮説はシンプルです。分析クラスターが、想定より長い時間にわたって追加のコンピュート容量に依存しているのではないか、というものでした。
ステップ2:まずはクラスターの状態(ポスチャ)を確認する
コストを押し上げているクラスターを特定できたら、次はその状態を確認するステップです。
このクラスターはRA3ノード、マネージドストレージ、Workload Management、同時実行スケーリングを利用していました。構成レベルで見るかぎり、明らかな問題は見当たりません。ここは立ち止まる価値があります。Redshiftクラスターは、静的な構成画面では妥当に見えても、実際のワークロードの使われ方と噛み合っていないことがあるからです。
有用な問いは「クラスターは正しく構成されているか?」ではなく、「クラスター構成はワークロードのパターンと噛み合っているか?」でした。これにより、調査は静的な構成レビューから実行時の挙動へとシフトしました。
このクラスターは、複数のワークロードタイプを支えていました。
- BIダッシュボード
- アプリケーション駆動の分析
- バッチおよび変換パイプライン
- MLやキャンペーン関連の処理
- スケジュール実行されるデータエンジニアリングジョブ
この混在用途のパターンはよくあるものですが、ワークロードの分離を慎重に行う必要があります。RedshiftのWorkload Management(WLM)はクエリキューを定義し、実行時に処理をそれらのキューへルーティングします。AWSはWLMを、クエリキュー、優先度、ワークロードルーティングを管理する仕組みとして説明しています。
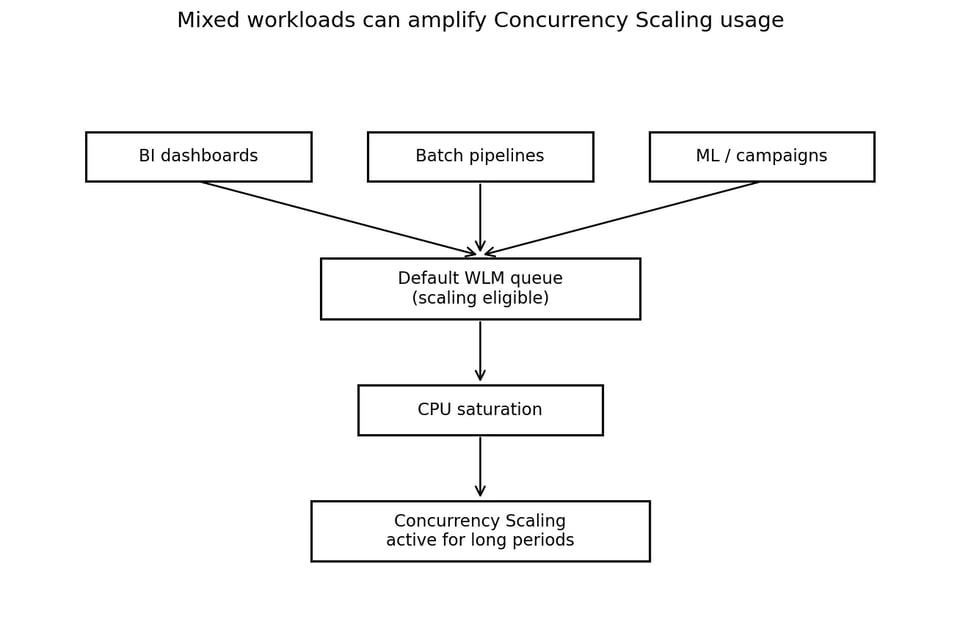
複数のワークロードタイプがスケーリング対象の単一キューを共有すると、同時実行スケーリングはもはやバースト容量ではなくなります。
ステップ3:CloudWatchに語らせる
次のステップは、Redshift向けCloudWatchメトリクスを絞り込んで確認することでした。
狙いはただ1つの問いに答えることです。このクラスターは短時間のバーストを経験しているのか、それとも継続的な負荷を受けているのか?
特に役立ったメトリクスは次のとおりです。
CPUUtilizationConcurrencyScalingActiveClustersConcurrencyScalingSecondsDatabaseConnections- ディスク使用率
パターンはすぐに明らかになりました。
繁忙時間帯:00:00~09:00 UTC
この時間帯が最も強い負荷の兆候を示していました。CPU使用率は最高、データベース接続数も最多、同時実行スケーリングの活動も最も継続的で、複数のワークロードが重なっていました。バッチ、ダッシュボード、アプリケーションの各ワークロードが同じ時間帯に衝突していたことを示唆しています。
業務時間帯:09:00~17:00 UTC
活動水準は引き続き高いものの、早朝の時間帯と比べれば概して低めでした。これはBIやダッシュボードの利用、インタラクティブな分析が主因と考えられます。
低活動時間帯:17:00~23:00 UTC
この時間帯は余力が大きく、CPU使用率は低め、スケーリング活動も減少、接続負荷も低くなっていました。優先度の低いバッチや変換ワークロードを再スケジュールする候補として、自然に浮かび上がってきます。
ステップ4:同時実行スケーリングはバースト容量として機能していなかった
最大の発見は、同時実行スケーリングの利用パターンでした。このクラスターは短時間のスパイク中だけ同時実行スケーリングを使っていたのではなく、ほぼ一日中使っており、しかも複数のスケーリングクラスターが同時にアクティブになることも珍しくありませんでした。観測期間中、同時実行スケーリングは1日あたりおおむね18~20時間稼働していました。
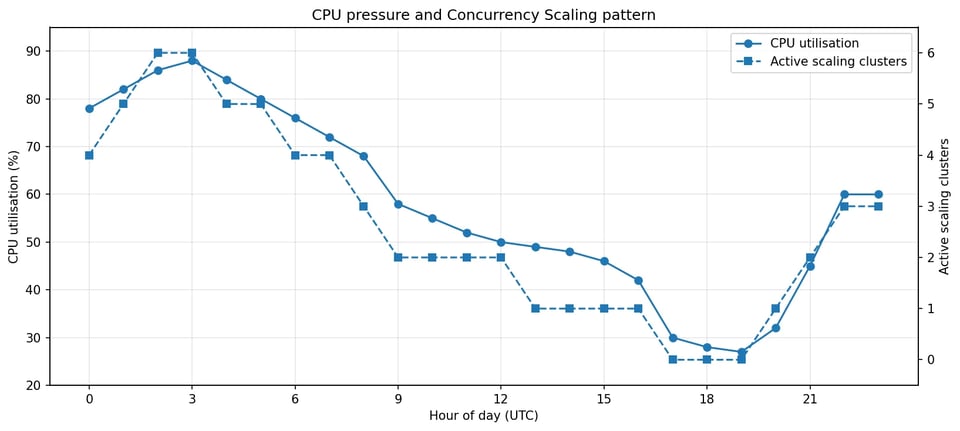
同時実行スケーリングは、スパイク時だけでなく、一日の大半にわたってCPU負荷に追従していました。
これにより、調査の性質が変わりました。問いはもはや「なぜスパイク時にRedshiftがスケールしたのか?」ではなく、「なぜこのクラスターには継続的なオーバーフロー容量が必要なのか?」になったのです。
同時実行スケーリングが長時間にわたって使われ続けているのは、ワークロードがベース容量、ワークロードルーティング、あるいはスケジューリングと噛み合っていない可能性を示すサインです。この時点で調査は「スパイクを探す」から「ワークロードの形を理解する」へとシフトしました。
ステップ5:ボトルネックを特定する
次のステップは、スケーリング負荷の本当の原因を突き止めることです。よくある候補はいくつかあります。
- CPUの飽和
- キュー待機時間
- ディスクの負荷
- I/Oの負荷
- 接続の負荷
- ワークロードのルーティング不良
メトリクスはCPUを強く示唆していました。CPU使用率は高い水準を維持し、同時実行スケーリングがアクティブだったのと同じ時間帯に頻繁にピークを記録していました。ディスク使用率は健全な水準を保ち、I/Oやネットワークのスループットは活発ではあるものの、主要なボトルネックには見えませんでした。
これが重要なのは、CPU飽和への打ち手と、キュー待機やストレージ負荷への打ち手は別物だからです。キュー待機時間はWLMの設定とスロット割り当てを指し示します。ストレージ負荷はテーブル設計、データのライフサイクル、マネージドストレージの利用状況を指し示します。CPU負荷はクエリ効率、ワークロードのスケジューリング、キューの分離、ベースコンピュート容量を指し示します。
今回のケースでは、多数のワークロードがCPUを取り合うなか、クラスターは長時間にわたって大量の処理をこなしていました。
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
ステップ6:コストを増幅させていたのはWLMキューだった
次の発見はWorkload Managementにありました。設定上は複数のキューが定義されていましたが、同時実行スケーリングはDefault Auto WLMキューで有効化されており、そのキューは明示的に他へルーティングされていないワークロードの受け皿としても機能していました。
これは、シンプルながら高コストなパターンを生んでいました。
分類されていない、あるいは混在したワークロード vDefault Auto WLMキュー(スケーリング有効) vCPU負荷 v同時実行スケーリング vコンピュートコストの増加問題はAuto WLMや同時実行スケーリングが「間違っている」ことではありません。どちらもRedshiftの有用な機能です。問題は、スケーリング容量にアクセスできる唯一のキューに、あまりに多くの混在ワークロードが流れ込んでいたことです。
WLMのルーティングはユーザーグループ、クエリグループ、関連する分類ルールに基づいて行えるため、ワークロード分離の重要な制御点となります。BIダッシュボード、バッチジョブ、MLワークロード、アプリケーションクエリがすべて同じスケーリング有効キューに流入すると、同時実行スケーリングは狙いを定めたツールではなく、広範な逃げ道になってしまいます。
こうしてコストは静かに膨らんでいくのです。
ステップ7:接続数とアクティブな同時実行は別物
もう1つ有用だったのが、データベース接続に関する観察結果です。このクラスターは接続数の定期的なスパイクを示しており、繁忙時間帯には高水準に達することもありました。一見すると、接続数の上限に達している可能性があるようにも見えました。
しかし、データベース接続は実際に動いているクエリと同じではありません。Redshiftクラスターは多数の接続が確立された状態でも、実際に実行されるのはその一部だけで、その量はワークロード管理、メモリ、CPU、キューの設定によって決まります。接続数の多さは依然として有用なシグナルで、ダッシュボードの更新、アプリケーションのファンアウト、ジョブのバーストを示すことがよくあります。ただし、それ自体がアクティブなクエリの同時実行を示す証拠になるわけではありません。
今回の調査では、接続のスパイクがCPU負荷および同時実行スケーリングの利用と時間的に一致していたため、有用な手がかりとなりました。これによって接続のスパイクはストーリーの一部に位置づけられましたが、それ自体が根本原因ではありませんでした。
より妥当な結論はこうです。多くのクライアントが予測可能な時間帯に接続して処理を投入しており、そのワークロードの組み合わせに対して、クラスターには十分なコンピュートの余力がなかった、というものです。
ステップ8:クエリの可視性はデータベース権限に依存する
クエリの挙動を調査するうえで、Redshiftのシステムテーブルとビューは欠かせません。混乱しやすいポイントの1つが、クエリの可視性です。Redshiftのシステムビューでは、スーパーユーザーはすべての行を参照できますが、一般ユーザーは通常、自分のデータしか見られません。AWSはSYS_QUERY_HISTORY、STL_WLM_QUERY、STL_QUERY_METRICS、および関連する監視ビューについて、この可視性ルールを明示しています。
クラスター全体のワークロード分析を行うには、クエリを実行する担当者が適切なデータベース権限を持っている必要があります。
答えるべき有用な問いには、たとえば次のようなものがあります。
- 実行時間を最も消費しているユーザーは誰か?
- 繁忙時間帯に実行されているクエリは何か?
- 同時実行スケーリングを使っているワークロードは何か?
- 処理の大半を受けているキューはどれか?
- 最適化に値するほど頻繁に繰り返されるクエリは何か?
利用可能であれば、AWSは新しいSYS監視ビューを推奨しています。フォーマットが整っていて使いやすく、理解しやすいためです。古いSTLやSVLのビューも引き続き広く使われており、調査には有用ですが、必要な情報をカバーできるならSYSビューの方がよりすっきりとした出発点になります。
実行時間順のトップクエリ
SELECT h.user_id, u.usename AS user_name, h.query_id, h.query_type, h.status, h.start_time, h.end_time, h.elapsed_time / 1000000.0 AS elapsed_seconds, h.execution_time / 1000000.0 AS execution_seconds, h.queue_time / 1000000.0 AS queue_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY h.execution_time DESCLIMIT 50;総実行時間順のトップユーザー
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, COUNT(*) AS query_count, SUM(h.execution_time) / 1000000.0 AS total_execution_seconds, SUM(h.queue_time) / 1000000.0 AS total_queue_secondsFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)GROUP BY h.user_id, u.usenameORDER BY total_execution_seconds DESC;CPU時間順のトップクエリ
ここではSVL_QUERY_METRICS_SUMMARYが役立ちます。完了したクエリのquery_cpu_time、query_blocks_readなどの関連メトリクスを含んでいるためです。AWSはquery_cpu_timeを、クエリが消費したCPU時間(秒単位)として定義しています。
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.service_class_name, h.compute_type, m.query_cpu_time, m.query_execution_time, m.query_blocks_read, m.query_temp_blocks_to_disk, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hJOIN svl_query_metrics_summary m ON h.query_id = m.queryLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date)ORDER BY m.query_cpu_time DESCLIMIT 50;WLMキューの使用状況
SELECT service_class_name, compute_type, COUNT(*) AS query_count, SUM(queue_time) / 1000000.0 AS total_queue_seconds, SUM(execution_time) / 1000000.0 AS total_execution_seconds, AVG(queue_time) / 1000000.0 AS avg_queue_seconds, AVG(execution_time) / 1000000.0 AS avg_execution_secondsFROM sys_query_historyWHERE start_time >= dateadd(day, -7, current_date)GROUP BY service_class_name, compute_typeORDER BY total_execution_seconds DESC;同時実行スケーリング上で実行されたクエリ
SYS_QUERY_HISTORYでは、compute_type列を見ることで、プロビジョン済みのRedshiftクラスターについて、クエリがメインクラスターで実行されたか、同時実行スケーリングクラスターで実行されたかを判別できます。AWSはprimary-scaleを、同時実行クラスターで実行されたクエリのコンピュートタイプとして定義しています。
SELECT h.user_id, COALESCE(u.usename, 'unknown') AS user_name, h.query_id, h.start_time, h.end_time, h.execution_time / 1000000.0 AS execution_seconds, h.service_class_name, h.compute_type, LEFT(h.query_text, 500) AS query_text_sampleFROM sys_query_history hLEFT JOIN pg_user u ON h.user_id = u.usesysidWHERE h.start_time >= dateadd(day, -7, current_date) AND h.compute_type = 'primary-scale'ORDER BY h.start_time DESCLIMIT 100;これらのクエリは最適化のゴールではなく、優先順位付けのスタート地点です。要は、推測をやめ、どのワークロードを分離・再スケジュール・チューニング・スケーリング許容のいずれにすべきかを見極めるためのものです。
ステップ9:推奨される改善計画
パターンが見えれば、改善計画はシンプルになります。狙いは同時実行スケーリングを手当たり次第にオフにすることではありません。それでもコストは下がるかもしれませんが、キュー待機が増え、重要なワークロードが遅くなる可能性もあります。
より安全なアプローチは、リスクの低いルーティング変更から始めて、後戻りのコストが高い意思決定へと進む段階的なやり方です。
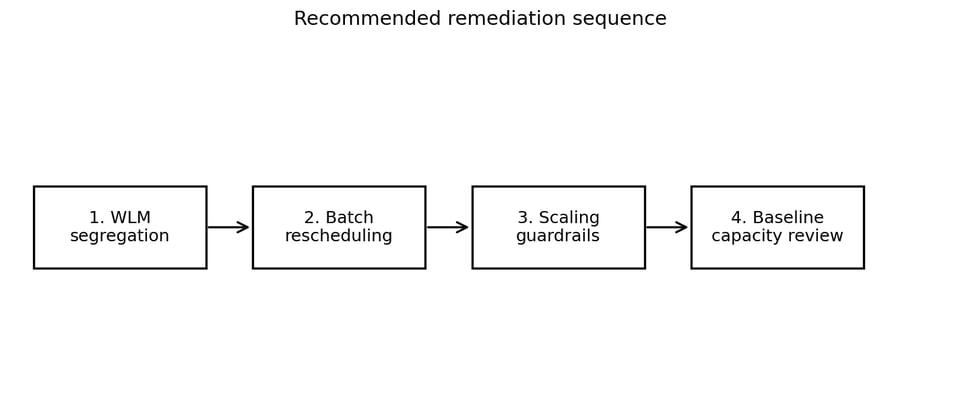
段階的な順序を踏むことで、初期のステップを安価かつ可逆的に保てます。
1. WLMでワークロードを分離する
WLMはワークロードの優先度を反映させるべきです。たとえば、次のように整理します。
| ワークロードの種類 | 想定される扱い |
|---|---|
| BIダッシュボード | 高優先度、スケーリングアクセスを制限 |
| 重要なアプリケーションクエリ | 高優先度、保護されたキュー |
| バッチジョブ | 専用キュー、多くの場合スケーリング無効 |
| MLや変換ワークロード | 専用キュー、可能ならスケジューリング |
| アドホック分析 | 低優先度、またはスケーリングを制限 |
これによって、優先度の低いバッチ処理が、インタラクティブやビジネス上重要なクエリと同じスケーリングプールを消費するのを防げます。ルーティング変更なので、キューの境界設定が誤っていてもすぐに元に戻せます。
2. バッチジョブを低活動時間帯に動かす
メトリクスは、一日の遅い時間帯に明確な低活動時間帯があることを示しており、これは即座に使える運用上のレバーになります。
すべてのバッチジョブが最も忙しい時間帯に動く必要はありません。優先度の低い変換、ML、レポーティングのジョブを静かな時間帯に移すことで、クラスターサイズを変えずにピーク時のCPU負荷を下げられます。アーキテクチャではなくタイミングを変える施策のため、最も実践的なコストレバーの1つとなることがよくあります。
3. 同時実行スケーリングのガードレールを設ける
ワークロードを適切にルーティングし、実行タイミングを整えたら、次のステップは同時実行スケーリング自体に上限を設けることです。広範にスケールできる状態のままだと、パフォーマンスは守れても、コストが予測しにくくなります。
最初の一手として妥当なのは、許容するスケーリングクラスターの最大数を制御された水準に減らし、その影響を観察することです。これによって次のことが分かります。
- 待機が発生し始めるワークロードはどれか?
- 本当にレイテンシーに敏感なジョブはどれか?
- ビジネス上の理由なくスケーリング容量に依存していたワークロードはどれか?
狙いはパフォーマンスを下げることではなく、スケーリングを「無制限のデフォルト」ではなく「意図して使うリソース」へと位置付けることです。
4. ベース容量を見直す
WLMとスケジューリングを改善した後も同時実行スケーリングが長時間アクティブなままであれば、ベースとなるクラスターがそもそもワークロードに対して小さすぎる可能性があります。その場合、ベース容量を増やすほうが、オーバーフロー容量に頼り続けるよりも安く済むこともあります。
直感に反するように思えますが、よくある話です。継続的な同時実行スケーリングの利用が大幅に減るのであれば、ベース容量を増やすことでトータルコストを下げられます。
ポイントは、この判断をワークロード分離とスケジューリングの改善の後で行うことです。さもないと、非効率なワークロードのルーティングがスケーリング容量を消費し続けるなか、ノードだけを追加してしまうリスクがあります。
5. 根拠に基づいてクエリをチューニングする
クエリ最適化は、最も重要なワークロードに焦点を当てるべきです。
- 総実行時間が長い
- CPU消費が大きい
- 頻繁に繰り返し実行される
- 繁忙時間帯に実行される
- スケーリング有効キューに入るクエリ
ここでこそ、システムテーブルの分析が活きてきます。見た目が悪いだけのクエリではなく、コストとパフォーマンスに実質的な影響を与えるクエリを最適化しましょう。
主なポイント
今回の調査では、Redshiftにまつわる実践的な教訓がいくつか改めて浮かび上がりました。
同時実行スケーリングをベース容量にしてはいけません。 一日の大半でアクティブになっているなら、それはもはやバースト容量として機能していません。定常的なコンピュートモデルの一部になっており、それ自体がコストのシグナルです。
CPU負荷とキュー負荷は別の問題です。 同時実行スケーリングの利用が多いからといって、自動的にWLMのキュー待機が根本原因だとは限りません。CPU、キュー待機時間、ディスク、I/O、接続のパターンを併せて確認しましょう。
デフォルトキューへのルーティングは高くつきます。 同時実行スケーリングが有効な受け皿キューは、静かに最大のコスト増幅要因になり得ます。WLMのルーティングは、ワークロードの優先度に沿わせるべきです。
ワークロードのタイミングは重要です。 バッチジョブ、ダッシュボード、MLワークロード、アプリケーション分析が重なれば、スケーリング負荷は増します。重要度の低いバッチを静かな時間帯にずらせば、機能を変えずにコストを下げられます。
クエリチューニングは原因の特定後に行うべきです。 チューニングに着手する前に、どのユーザー、ワークロード、キューがリソース消費を牽引しているかを特定しましょう。当てずっぽうは、たいてい時間の無駄になります。
おわりに
Redshiftのコスト最適化は、たった1つの設定で片付くことはほとんどありません。今回のケースでも、問題は壊れたクラスターや1つの悪いクエリではなく、混在するワークロード、予測可能なタイミングの衝突、CPUの飽和、そしてデフォルトのWLM経路を通じて同時実行スケーリングへ広くアクセスできてしまうこと——これらの組み合わせが原因でした。
調査で最も有用だったのは、個々のメトリクスそのものではなく、それらをつなぎ合わせたことです。
- コストレポートでクラスターを特定する
- CloudWatchで継続的なスケーリングとCPU負荷を可視化する
- WLMの構成からスケーリングが広く利用可能になっている理由を説明する
- システムテーブルで優先すべきユーザーとクエリを特定する
Redshiftの請求額が膨らみ続け、同時実行スケーリングがバーストからベースへと静かに姿を変えているなら、悩んでいるのはあなただけではありません。DoiTは、こうしたコスト調査をAWSのお客様と毎週実施しています。100名を超えるクラウドエキスパートからなるチームが、要因の特定、ワークロードの分離、そして同時実行スケーリングを本来の役割へ戻すお手伝いをします。お気軽にご相談ください。