In the world of cloud engineering, velocity is everything. Teams are under constant pressure to ship features faster, scale systems more efficiently, and deliver business value without delay.
Given those overarching goals, it probably shouldn’t be too surprising that routine cloud maintenance tasks often fall by the wayside. Even with the savings that cost optimization maintenance can provide (the amount of which, to be fair, isn’t always clear), engineers’ time is simply too valuable to devote several hours every week to getting it done.
Yet in the long run, neglecting these small tasks can quietly accumulate into significant cost inefficiencies, along with operational risk.
The cost of unrealized cloud optimizations
Every organization has cloud inefficiencies hiding in plain sight. Some are obvious, like overprovisioned instances or zombie workloads. Others are more subtle, like buckets of incomplete, multipart uploads in S3 slowly accruing storage charges.
Most cloud teams know these problems exist. The issue isn't awareness – it's priority. When engineers are measured by product velocity, it’s hard to justify spending cycles combing through S3 buckets or checking for missing cleanup rules.
And yet, these unrealized optimizations often have a measurable financial impact. They're the kind of tasks that are just annoying enough to ignore, but just costly enough to matter over time.
Why maintenance tasks get overlooked
Ask any cloud engineer where their time goes, and you’ll hear variations on the same theme: building new features, responding to incidents, supporting developer productivity, keeping up with new services and APIs – the tasks are seemingly endless.
Meanwhile cloud hygiene, like auditing IAM policies, configuring auto-delete on unattached volumes, or setting lifecycle rules for incomplete S3 uploads, gets lumped into a category best described as: “We’ll get to it later.”
The problem is, “later” rarely comes.
Case in point: S3 multipart upload cleanup
Take the specific case of Amazon S3 multipart uploads. When an upload is initiated but never completed (which happens more than you'd think), AWS continues storing the uploaded parts—charging you for the storage, even if the object itself was never finalized.
The fix is simple: configure a lifecycle rule to abort incomplete multipart uploads after a set number of days (typically 7). But in practice, many S3 buckets are missing this rule.
Why? Because to do this in the AWS console, here’s what it entails:
Manual Process for Managing S3 Multipart Upload Cleanup via the AWS Console
1. Log into the AWS Console
- Navigate to the AWS Management Console
- Go to the S3 service dashboard
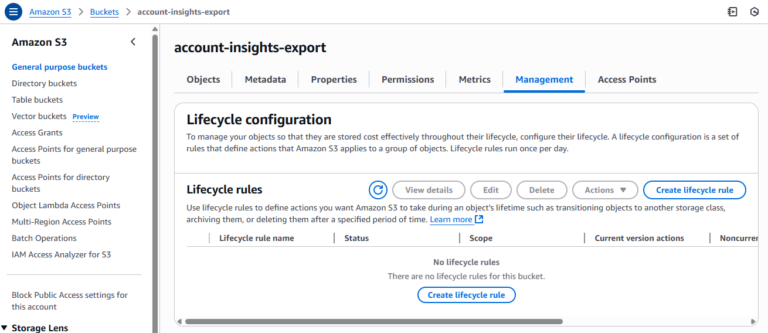
2. Review Lifecycle Rules for Each Bucket
This is where things become inefficient, because there is no native way in the AWS Console to filter or search across buckets for lifecycle configurations or missing rules. Instead, the user must:
- Manually open each bucket
- Go to Management → Lifecycle rules.
- If rules exist, inspect them to confirm whether one handles “Incomplete multipart uploads”
- If such a rule exists (typically named “Abort incomplete multipart uploads after X days”), no further action is needed
- If no rule exists, proceed to add one
3. Add Multipart Cleanup Rule
For each bucket that lacks the rule:
- Click “Create lifecycle rule”
- Enter a rule name (e.g., abort-multipart-uploads)
- Choose the rule scope (e.g., apply to all objects in the bucket)
- Under Lifecycle rule actions, check “Delete expired object delete markers or incomplete multipart upload”
- Under Incomplete multipart uploads, check “Delete incomplete multipart uploads”
- Set the number of days after initiation (AWS recommends 7 or fewer)
- Review and save the rule
- Repeat this for each bucket needing the rule
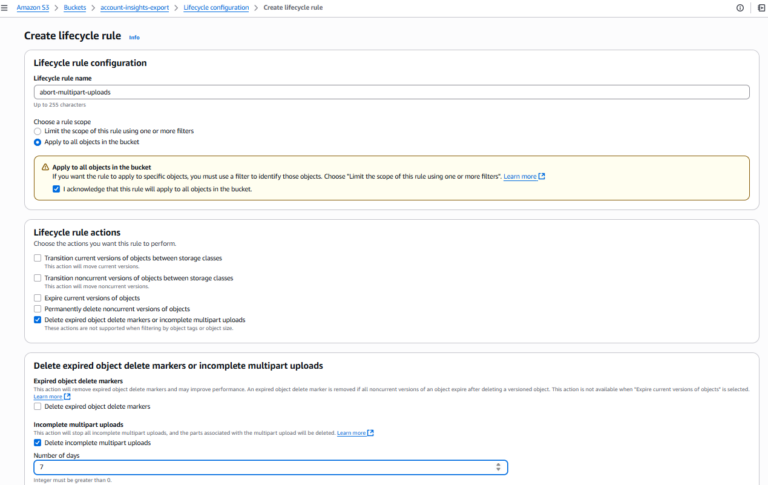
As you can see, finding and fixing the issue across tens, hundreds, or even thousands of buckets means this whole repetitive, slow, and error-prone process simply doesn’t get done.
Solving the problem with workflow automation
These kinds of tasks are ideal candidates for automation – not because they're technically complex, but because they’re operationally boring. And boring tasks are the ones that drain productivity if done manually, and quietly damage efficiency if ignored.
But with CloudFlow, the no-code workflow automation solution within DoiT Cloud Intelligence™, a cloud engineer could simply configure the workflow they want done and have the system do the work in seconds.
In this instance, a corresponding CloudFlow could look like this, which each step in the flow replacing one or more manual steps that you’d otherwise have to do in the AWS console:
- Set a scheduled trigger for the time and cadence you want the CloudFlow to run
- Using CloudFlow’s API functionality, first get the full list of S3 buckets in your AWS account(s) (“ListBuckets”)
- From the buckets listed, fetch their lifecycle configuration rules (“GetBucketLifecycleConfiguration”)
- Create a filter node to find all buckets that are missing the required rule (“Filter for missing policy”)
- Use another AWS API to apply the new rule to all filtered buckets (“PutBucketLifecycleCongifuration”)
- Create a notification step to document the change and keep all stakeholders informed
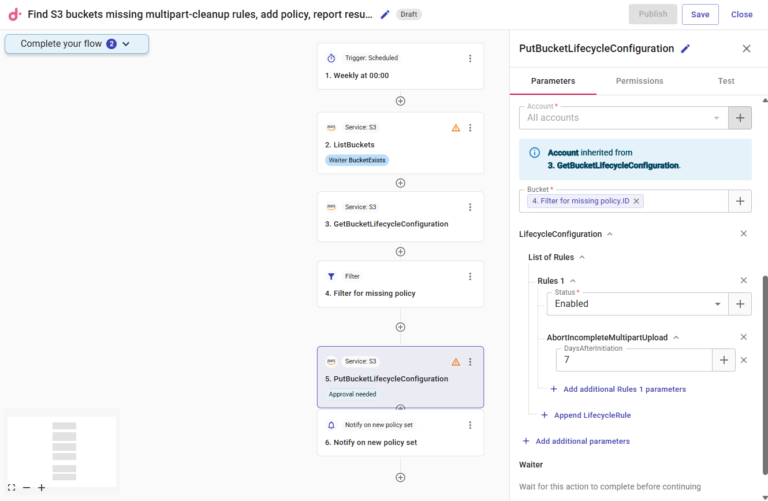
To maintain compliance, you can also apply an approval to any step in the process to ensure that no buckets are modified without an account admin’s permission:
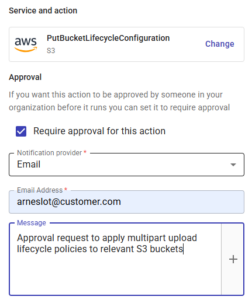
Not only does this CloudFlow replace the tedious and time-consuming process of clearing up ALL of the S3 buckets within the accounts specified, but it can also be run on a weekly basis to ensure that any new buckets that get created without the lifecycle rule can be caught and correctly modified to include the rule.
This kind of shift doesn’t just save time, it changes the way teams work. Rather than devoting hours to the initial cleanup and then regularly performing the same maintenance over and over again, CloudFlow puts the process on autopilot and allows cloud engineers to focus on work that not only has a greater impact on the company’s long-term goals, but also spares them from mind-numbingly dull tasks.
And S3 lifecycle management is just one potential use case for CloudFlow; it can also be used to autonomously apply tags or labels to resources, turn instances on and off, rightsize workloads, or really do anything else that can be accomplished with AWS or Google Cloud APIs.
To learn more about how CloudFlow can impact the way your team works, check out this guided tour, or contact a DoiT expert.