













As more and more companies look to incorporate Large Language Models (LLMs) into their products and services, we’ve fielded many questions around:
- Selecting the right Foundational Model for your use case,
- How to keep unit costs of your GenAI deployment stable, and
- Observability of LLMs post-deployment
...or where to even start with an LLM project.
That’s why we organized a live Q&A for Google Cloud customers from across the GenAI readiness spectrum. Companies ranging from those in an experimental phase with AI, to those already with a deployment in production joined to ask three of DoiT’s AI/ML experts (Eduardo Mota, Jared Burns, Sascha Heyer) any question they had around implementing LLMs on Google Cloud.
We summarized the key insights for you below, covering topics from how to get started with GenAI on Google Cloud to more advanced topics like using your company’s Google Workspace data for Retrieval-Augmented Generation (RAG).
Getting started with GenAI on Google Cloud
Original Question: How should I get started with GenAI as a company on Google Cloud?
To answer this, Eduardo summarized the GenAI Implementation Journey that we take companies through when helping them build customized GenAI solutions through our GenAI Accelerators.
This journey covers the steps from ideation to scaling your deployment in production (and observability throughout).
Specifically, we focused on the ideation, prompt design, and PoC stages.
Ideation of GenAI use cases
When brainstorming LLM-based implementations, it’s important to align what you’re trying to build with business goals.
Some questions you can ask yourself to get the ideas flowing include:
- Classification: “If I could identify ______ in ________, I could ________”
- Ex. “If I could recognize a car’s scratches in images from a surveillance camera, I could improve the check-in and check-out process of our rental cars”
- Personalization: “If I knew which ________ were most likely to _________, I could _______”
- Ex. “If I knew which services were most likely to retain a customer, I could offer personalized retention offers.”
- Expert systems: If I could identify ________ with _________, I could ___________”
- Ex. “If I could identify the customer persona with their individual historic data, I could provide tailored guidance to them”
In general when brainstorming ideas for possible GenAI implementations, we tell companies to think about personalized experiences rather than generic processes.
For example:
- Generic: We want to allow customers to order food online with previous order repurchase, and create up-sells based on marketing personas.
- Personalized: If we could leverage a customer’s individual data and restaurant information, we can create a high quality food order experience for the customer that reduces time to order and adds high customer value up-sells.
If you’re more of a business leader than technical, Google Cloud also provides GenAI Navigator, which asks you a series of questions under three categories (Strategy, Infrastructure, and Skills) in order to provide recommendations on how you might want to get started with GenAI on Google Cloud.
LLM prompt design
Once you have a clear idea of what to pursue, the next step would be to play around with prompts in Vertex AI Studio — you can even get $300 in free credits and even more through initiatives like Google Cloud’s AI Startup program.
However, you shouldn’t experiment for the sake of experimenting. You should have a goal in mind, and follow the key steps Eduardo highlighted in the prompt design process:
- Define a desired output: Clearly articulate what you want your model to produce. This ranges from classification results to personalized recommendations or complex analyses.
- Implement security measures: Set up safeguards to potential risks like prompt injection and incorrect LLM outputs. We covered risks you should be aware of in more detail in a past Cloud Masters podcast episode on LLM security risks and mitigation strategies:
- Identify the required context for the desired output: Ask yourself what information the model needs — data, background information, specific instructions — to generate the desired output
- Create 2-3 prompts with different techniques: Test out techniques like few-shot learning, chain-of-thought reasoning, or multi-prompt approaches. Each technique can give different results, so it's worth experimenting with various methods.
- Evaluate the prompts with different models: You have access to a wide array of models in Vertex AI Studio. Test some of them! This will help you understand how different models respond to your prompts and optimize for performance and accuracy.
GenAI Proof-of-concept (PoC)
Once you've experimented with prompt design, the next step is to develop a proof of concept. Eduardo outlined several key requirements for a successful PoC:
- Define clear success criteria
- Establish a test group of at least 10 users
- Leverage Google managed services such as text-bison, Gemini, Cloud Functions, etc.
- Gather user feedback
- Establish performance metrics
- Set performance benchmarks
As Eduardo described to Data Science Central, the feedback from your initial test group is super important. “You want to get feedback from users, even if the experience was not a positive one. Be sure you have set standard benchmarks, then monitor every input and output produced by your GenAI. By evaluating just these items you can gain insight into workload adjustments needed to take things up a grade.” The purpose of this is to iterate fast through feedback to close any gaps in the customer experience journey.
In a previous Cloud Masters podcast episode, Sascha and Eduardo also covered why it's important to have observability in place for metrics like LLM inputs, outputs, and requests.
If you’re looking to get your hands dirty quickly with GenAI, but aren’t at the point yet with developing a PoC using your own data, Google Cloud provides Jump Start solutions.
These are one-click, open-source deployments that:
- Provide a ready-to-use infrastructure as code in a GitHub repository
- Allow for easy deployment in your own project
- Offer a comprehensive end-to-end architecture that you can explore and modify
For example, the diagram below shows the architecture of the application infrastructure for a GenAI Knowledge Base solution from Google Cloud’s corresponding Jump Start:

Generating JSON outputs with Vertex AI
Original question: How do I get LLM responses in JSON with format clearly defined?
LLM outputs are often unstructured, and while this flexibility can be useful for creative or conversational tasks, it becomes problematic when building production applications that need to process and act on these outputs programmatically
Imagine trying to build an e-commerce product recommendation system where each suggestion needs specific attributes like price, category, and availability with unstructured data. Or creating a customer support system that needs to extract ticket details, priority levels, and suggested actions in a consistent format.
In these scenarios, getting responses in a structured JSON format is essential. Without structured outputs, you'd need complex parsing logic that could break when the LLM's response format varies even slightly.
At the time this question was asked, Google Cloud had just released Controlled generation in private preview, which allows developers to specify exact output formats for their LLM responses. Since September 5, 2024, Gemini 1.5 Pro and Flash fully support Controlled generation.
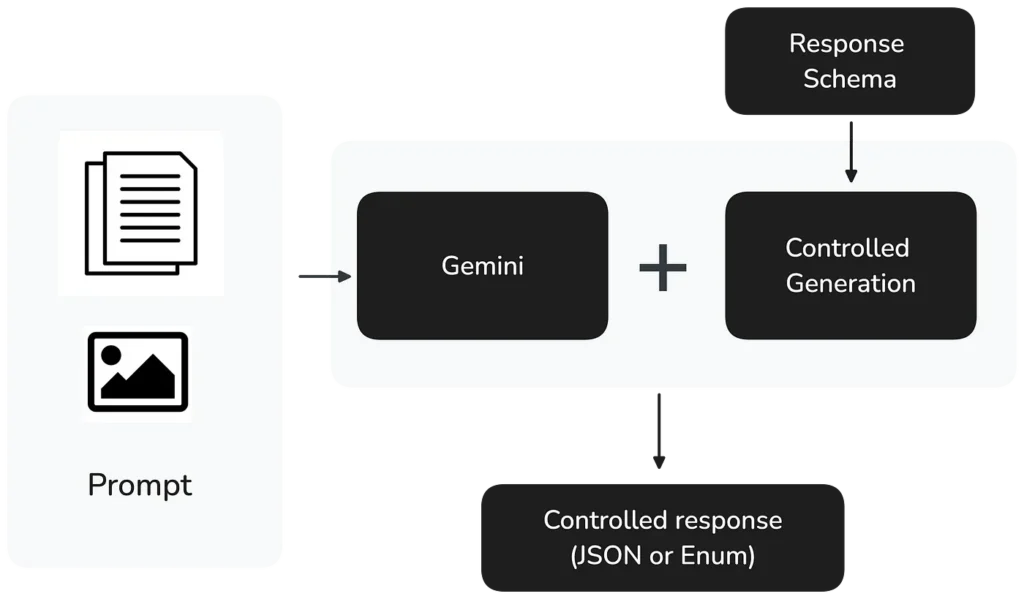
Implementation is straightforward — developers can specify:
- A response MIME type to ensure valid JSON or Enum output
- A response schema to define the exact structure needed
Sascha covers Controlled generation in greater detail in his blog post, so if you’re looking to dive into a Google Colab notebook and start experimenting with code, check his article out.
Implementing RAG with Google Workspace Data
Original question: Is there any way to train Google Cloud LLMs on subsets of our Google Workspace data? For example, how can I train an LLM based on My Drive or a Shared Drive or Folder and then query for information contained in the dataset? I want to avoid copying all the data into GCS for training.
Retrieval Augmented Generation (RAG) is a technique that allows you to enhance LLM responses by incorporating information from outside the model’s training data. Instead of relying solely on the model's training data, RAG retrieves relevant information from documents and data you provide and uses it to generate more accurate, contextual responses.
One useful application of RAG for companies is integrating it with their Google Workspace data (Docs, Sheets, Drive, etc.). This can be used in situations like:
- Creating an AI-powered knowledge base from internal documentation
- Building customer support systems that draw from product documentation stored in Drive
- Developing internal search tools that can understand and summarize content across multiple Workspace documents
For example, a sales team could use RAG to quickly find and summarize relevant case studies from their Drive, or HR could build a system that answers employee questions using their internal policy documents.
As Jared covered in the clip below, Google Cloud offers several options for implementing RAG within Vertex AI:
- Vertex AI Search: Generates and stores embeddings for document retrieval
- Custom retrievers: Build your own retrieval system
- LlamaIndex: An open-source tool adopted by Google as its managed RAG solution
Jared then walked through implementing RAG with Google Drive data using LlamaIndex. Specifically he:
- Created a RAG corpus to store the document data
- Imported files from a Google Drive folder containing Alphabet's Q1 2024 earnings statement, among other files.
- Verified the import by checking the count of imported files
- Tested the retriever functionality by asking: "What was Alphabet's revenue for Q1 2024?"
- Generated a response using Gemini 1.0, which accurately reported Alphabet's Q1 2024 revenue — information pulled directly from the uploaded statement.
Mocking API Responses for LLM Testing
Original question: In Vertex AI Agent Builder, is it possible to mock a tool call for testing purposes? For instance if the API we’ll use hasn’t been developed yet.
While testing is important in general with software development and APIs, it’s particularly critical when working with LLM-based applications due to their probabilistic nature. The same prompt can generate different responses each time, which makes it important to have controlled testing environments that can validate consistent agent behavior.
At the same time, when developing applications with LLM-based custom agents, testing isn’t straightforward. While these agents frequently need to interact with external APIs, relying on live API calls during testing introduces costs, latency, and potential reliability issues due to rate limits and service disruptions. Additionally, external APIs might return varying responses based on real-time data, making it difficult to test specific scenarios or edge cases consistently.
Implementing mock API responses allows you / your developers to test agent behavior in a controlled environment, ensuring reliable and efficient testing cycles.
Eduardo outlined a straightforward approach to mocking API responses with Google Cloud Functions, discussing two implementation options:
Separate Mock Function
- Create a dedicated Cloud Function that serves as the mock API
- Configure the agent to call this mock function during testing
Inline Mocking
- Implement the mock response directly within the existing Cloud Function
- Return predefined responses instead of making real API calls
Since you have full control over the function's implementation, you can define custom mock responses that match real API structure, control when to return mock vs real responses, and maintain consistent response formats for agent processing.
The main thing to look out for is that your mock responses maintain the same structure and format that your agent expects from the real API.
By implementing proper API mocking, you can develop and test your LLM-based agents more efficiently while maintaining control over their testing environment.
Passing parameters between agents with Vertex AI Agent Builder
Original question: Using Agent Builder, how can I reliably pass parameters between agents?
Imagine you're building an AI system where different specialized agents need to work together. Maybe one agent handles customer inquiries, another manages inventory information, and a third processes orders. These agents need to share information with each other smoothly and reliably. That's where parameter passing comes in.
For example, when a customer asks about ordering a product, the customer service agent might need to pass the product ID to the inventory agent to check availability, and then pass both the product ID and quantity to the order processing agent. Getting this information flow right is crucial for building effective AI systems.
However, while AI agents are generally good at understanding and sharing information, their probabilistic nature means they might occasionally mishandle these information handoffs. In a business context where accuracy is crucial, we need ways to ensure these handoffs are 100% reliable.
Eduardo demo’d how to pass parameters between agents with Vertex AI Agent Builder, and discusses coding validation throughout your flow to ensure the right parameters are being passed.
While Vertex AI’s Agent Builder makes it easy to create AI agents that can work together, adding proper parameter validation ensures your system runs reliably in real-world conditions. By implementing an orchestrator to manage parameter passing and enhancing your agents with good examples, you can build robust AI systems that handle information sharing dependably.
Remember to implement comprehensive validation logic and maintain detailed logs of parameter passing operations. This upfront investment in reliable parameter handling will save considerable time and effort as your AI applications grow and become more complex.
Conclusion
We covered just over half of the questions asked during our live Q&A on implementing LLMs on Google Cloud. Whether you're just starting with GenAI or looking to optimize your existing implementation, this should provide you with a solid foundation.
For the complete set of insights, including topics like document processing, LLM best practices for iOS-native apps, and transcript structuring, check out our full YouTube playlist of the Q&A session.
Implementing LLMs on Google Cloud involves a blend of technology and human expertise. As GenAI is relatively new technology, having experienced guidance can help avoid common pitfalls and accelerate your path to production.
If you'd like support with your GenAI implementation on Google Cloud, get in touch with our team of AI/ML experts about our GenAI Accelerator for Google Cloud, where we can help you build and scale your LLM-based applications efficiently.



