












By Vadim Solovey, Google Developer Expert.
Recently, I came across an interesting benchmark of BigData systems based on “A Comparison of Approaches to Large-Scale Data Analysis” by Pavlo et al. (SIGMOD 2009). Based on the benchmark methodology, the APMLab guys from Berkeley University developed an open-source software that allows anyone to run this benchmark using public cloud (AWS in this case).
This benchmark measures response time on a handful of relational queries: scans, aggregations, and joins across different data sizes. They have an impressive website with benchmark results, comparing Amazon Redshift, Hive, Shark, Impala and Stinger/Tez.
Since a lot of my time is devoted to working with Google BigQuery, I was intrigued how BigQuery would stand being compared to other solutions based on exactly the same dataset. Clearly, BigQuery has a very different nature since it’s shared service and not dedicated, customer-deployed (and maintained) solution.
Despite this nature of Google BigQuery, the results are extremely surprising (in my humble opinion).
The Dataset
The benchmark allows 3 different sizes of datasets — tiny, 1node and 5nodes. The largest dataset is 5nodes which has ‘rankings’ table with 90 million records and ‘uservisits’ table with 775 million records. The data is generated using Intel’s Hadoop benchmark tools. The data itself are available at s3://big-data-benchmark/pavlo/[text|text-deflate|sequence|sequence-snappy]/[suffix]. I used text version of the data which is in CSV format, thus making its very easy to load into BigQuery.
In general, there are two tables with the following schemas:
Ranking table schema:
(Lists websites and their page rank)
- pageURL (STRING)
- pageRank (INTEGER)
- avgDuration (INTEGER)
Uservisits table schema:
(Stores server logs for each web page)
- sourceIP (STRING)
- destURL (STRING)
- visitDate (STRING)
- adRevenue FLOAT
- userAgent (STRING)
- countryCode (STRING)
- languageCode (STRING)
- searchWord (STRING)
- duration (INTEGER)
The Workload
So, once again, the benchmark measures response time on a handful of relational queries: scans, aggregations and joins. Some of the query results are larger than 128MB and violate the quota policy. To overcome this, I was using a destination table to store the query results with setting allowLargeResults to true.
Another note would be on use of EACH modifier for GROUP BY and JOIN operators. This is required when the dataset is big and there is a high cardinality aggregation or join.
1. Scan Query
This query has 3 permutations, when X is 1000, X is 100 and then X is 10:
SELECT pageURL, pageRank FROM [benchmark.rankings] WHERE pageRank > X
2. Aggregation Query
This query has 3 permutations, when X is 8, X is 10 and then X is 12:
SELECT SUBSTR(sourceIP, 1, X) AS srcIP, SUM(adRevenue) FROM [benchmark.uservisits] GROUP EACH BY srcIP
3. Join Query
Like other queries earlier, this one also has 3 permutations: X is ’1980–04–01’, X is ’1983–01–01’ and X is ’2010–01–01’:
SELECT sourceIP, sum(adRevenue) AS totalRevenue, avg(pageRank) AS pageRank FROM [benchmark.rankings] R JOIN EACH(SELECT sourceIP, destURL, adRevenue FROM [benchmark.uservisits] UV WHERE UV.visitDate > "1980-01-01" AND UV.visitDate < X) NUV ON (R.pageURL = NUV.destURL) GROUP EACH BY sourceIP ORDER BY totalRevenue DESC LIMIT 1
4. External Script Query
The original benchmark also measuring performance of UDF (user defined functions). As of today, BigQuery doesn’t support UDF but that can change soon and when it does, I am going to update the benchmark with the UDF performance results.
The Results
Occasional query latency spikes are expected with BigQuery due to its shared nature, so I executed each query 10 times (once per hour) and the results are median response time (in seconds)
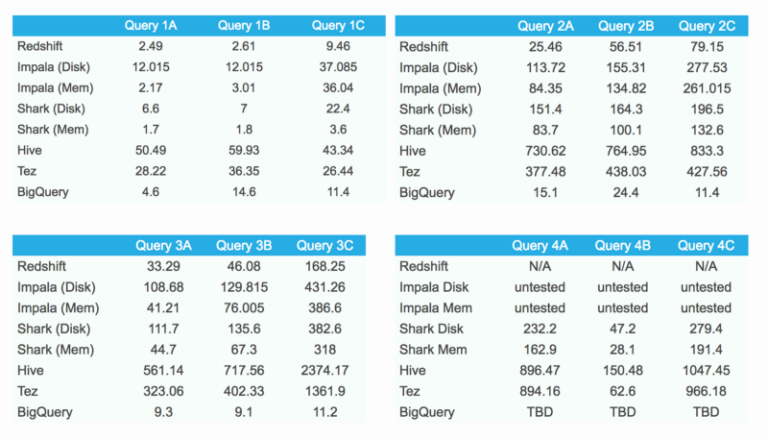
Looking on the results, it’s clear that BigQuery really shines with aggregations (queries 2A, 2B and 2C) and joins (queries 3A, 3B and 3C). In these two queries BigQuery is taking the 1st place among its rivals.
The first query is pretty fast as well, however due the result size limitation and thus the need to store the query results in temporary table, the performance is not as good as it can be.
Nevertheless, BigQuery is no-maintenance, no-setup and pay-as-you-go BigData solution with awesome performance. I recommend you take a look at that and consider it for your next big data challenge.
Originally published at www.doit.com on June 9, 2015.



