
Si vous cherchez à mieux comprendre la détection d'anomalies par machine learning, vous n'êtes pas seul. Vous avez peut-être passé des heures à chercher pourquoi vos coûts cloud se sont envolés le mois dernier, ou vous peinez à distinguer un pic de trafic légitime d'une menace de sécurité potentielle.
Des comportements imprévus dans les environnements cloud peuvent éroder l'efficacité opérationnelle et coûter des milliers d'euros s'ils ne sont pas traités rapidement. Les anomalies prennent plusieurs formes : hausses soudaines des dépenses cloud, comportement système irrégulier qui dégrade les performances ou activité suspecte qui met en péril des données sensibles.
La complexité du cloud ajoute une difficulté supplémentaire. La multiplicité des services et des dépendances complique l'identification de la cause racine. Pour préserver la fiabilité des systèmes et limiter les risques, les équipes doivent pouvoir détecter les valeurs aberrantes et y répondre rapidement et avec précision.
Ce guide explique ce qu'est la détection d'anomalies, les principaux types à surveiller, les techniques et algorithmes de machine learning les plus courants, ainsi que les bonnes pratiques de mise en œuvre.
Qu'est-ce que la détection d'anomalies ?
 Source : DoiT Anomaly Detection
Source : DoiT Anomaly Detection
Sur le fond, la détection d'anomalies identifie les comportements qui s'écartent de ce qui est attendu. Dans les environnements cloud, elle agit comme un système immunitaire : elle surveille en continu, apprend à reconnaître la normalité et signale les déviations significatives.
Les anomalies cloud apparaissent généralement dans deux domaines :
- Anomalies opérationnelles : évolutions des performances, de la fiabilité ou du comportement système (pics de latence, variations du taux d'erreur, schémas d'accès inhabituels).
- Anomalies de coût : hausses inattendues des dépenses, corrélées ou non à des changements de trafic ou de performances.
Les deux se recoupent souvent (un pic de trafic peut faire grimper à la fois les dépenses et la latence), mais les anomalies de coût peuvent aussi survenir sans symptôme opérationnel évident : mauvaise configuration de logging, feature flag activé par erreur ou évolution des prix ou de l'usage.
Les systèmes modernes de détection d'anomalies ne se contentent plus de seuils statiques. Ils s'appuient sur le machine learning pour suivre des baselines dynamiques qui évoluent selon l'heure, le jour ou la saison. Le pic de trafic d'une plateforme e-commerce pendant ses soldes annuelles, par exemple, est attendu, alors que le même pic un mardi banal pourrait trahir une attaque par bots ou un déploiement défaillant.
Les types d'anomalies à surveiller
Dans les environnements cloud, les anomalies relèvent généralement de la sécurité, de l'exploitation ou des coûts. Au sein de ces catégories, elles se présentent le plus souvent sous trois formes :
Anomalies ponctuelles
Un point de donnée unique radicalement différent du reste : un pic d'appels API multiplié par 10 ou une envolée soudaine des coûts de transfert de données. Faciles à repérer, mais le plus difficile reste de déterminer s'ils sont légitimes (un lancement produit) ou suspects (un usage abusif d'identifiants).
Anomalies contextuelles
Un comportement qui n'est anormal que dans un contexte précis : un CPU élevé est normal aux heures de pointe, mais préoccupant à 3 h du matin. Cela exige des modèles capables d'intégrer le temps, la saisonnalité et les cycles métier.
Anomalies collectives
Un ensemble d'événements qui paraissent normaux pris isolément mais deviennent suspects mis bout à bout : des requêtes coordonnées trahissant une attaque DDoS ou une dérive lente des coûts répartie sur plusieurs services.
3 techniques de détection d'anomalies pour repérer les problèmes tôt
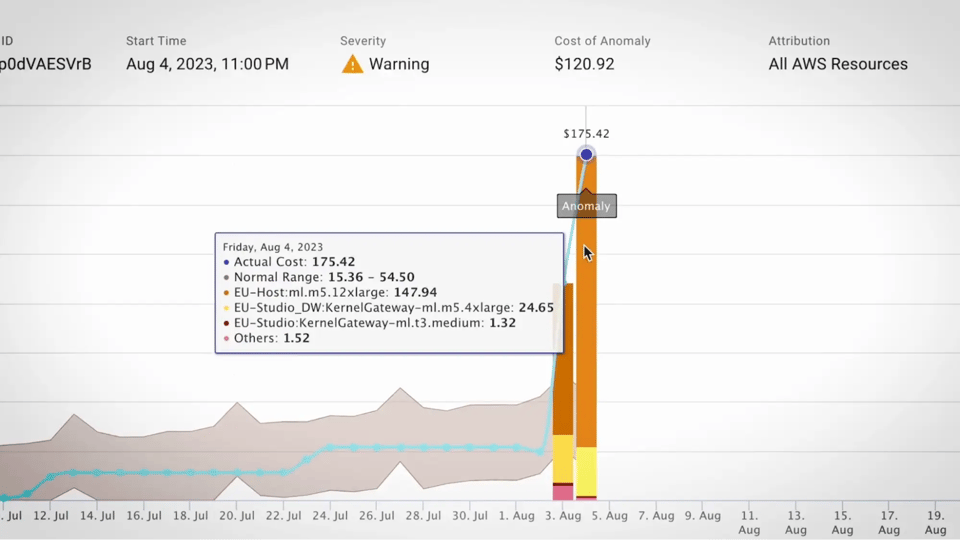 Source : Guide des outils FinOps
Source : Guide des outils FinOps
Les techniques de détection ne se valent pas selon les environnements. En pratique, les équipes cloud les choisissent en fonction des données disponibles, de la vitesse d'évolution des systèmes et des types d'anomalies à détecter.
1) Détection supervisée
La détection supervisée entraîne les modèles à partir d'exemples étiquetés de comportements normaux et d'anomalies connues. Très précise sur les problèmes familiers, elle peine en revanche face à des événements nouveaux ou rares pour lesquels aucun exemple n'existe.
2) Détection non supervisée
La détection non supervisée est souvent l'option par défaut dans le cloud, car elle ne nécessite pas de données d'anomalies étiquetées. Elle apprend ce qui est normal en observant les comportements dans la durée, puis signale les événements rares ou nettement différents.
Cette approche est particulièrement utile pour des systèmes récents (sans historique étiqueté) ou en évolution constante. À mesure que votre environnement change, les méthodes non supervisées continuent de s'adapter aux nouvelles baselines.
3) Détection semi-supervisée
La détection semi-supervisée s'appuie sur une petite quantité de données étiquetées pour gagner en précision tout en restant suffisamment souple pour repérer des problèmes inédits. On l'utilise souvent quand on dispose d'exemples fiables de normalité, mais de peu d'anomalies étiquetées.
En réalité, beaucoup de systèmes de détection d'anomalies cloud reposent majoritairement sur les méthodes non supervisées, car attendre de collecter et d'étiqueter suffisamment d'anomalies n'est pas réaliste. Les meilleurs systèmes commencent à protéger l'environnement immédiatement et continuent d'apprendre à mesure que les comportements évoluent.
Les algorithmes courants de détection d'anomalies
Les systèmes de détection d'anomalies s'appuient sur tout un éventail d'approches statistiques, de machine learning et de deep learning, chacune adaptée à des formes de données et à des besoins opérationnels différents.
Méthodes statistiques et basées sur des règles
Des méthodes comme l'analyse du Z-score, l'écart interquartile (IQR) ou le simple seuillage fonctionnent bien pour des écarts nets dans des jeux de données stables. Rapides et simples à mettre en œuvre, elles sont utiles pour la détection en temps réel sur des distributions claires.
Méthodes de machine learning
Pour des données plus complexes, les approches ML apportent la reconnaissance de motifs. Les méthodes basées sur des arbres (notamment les isolation forests) sont fréquemment utilisées : les anomalies étant rares, elles sont plus faciles à isoler que les points normaux, ce qui rend ces méthodes efficaces sur de gros volumes.
Méthodes de deep learning
Les approches de deep learning, et en particulier les autoencodeurs, excellent sur des données à haute dimension où la normalité est complexe. Elles apprennent une représentation compressée des comportements normaux et signalent les déviations lorsque l'erreur de reconstruction est élevée.
Méthodes de prévision de séries temporelles
Quand les données dépendent du temps, la prévision permet de définir des plages attendues. ARIMA et Prophet sont souvent utilisés pour les comportements saisonniers et les tendances irrégulières. Ces approches détectent les anomalies en comparant les valeurs réelles aux baselines prédites.
Cas d'usage concrets de la détection d'anomalies
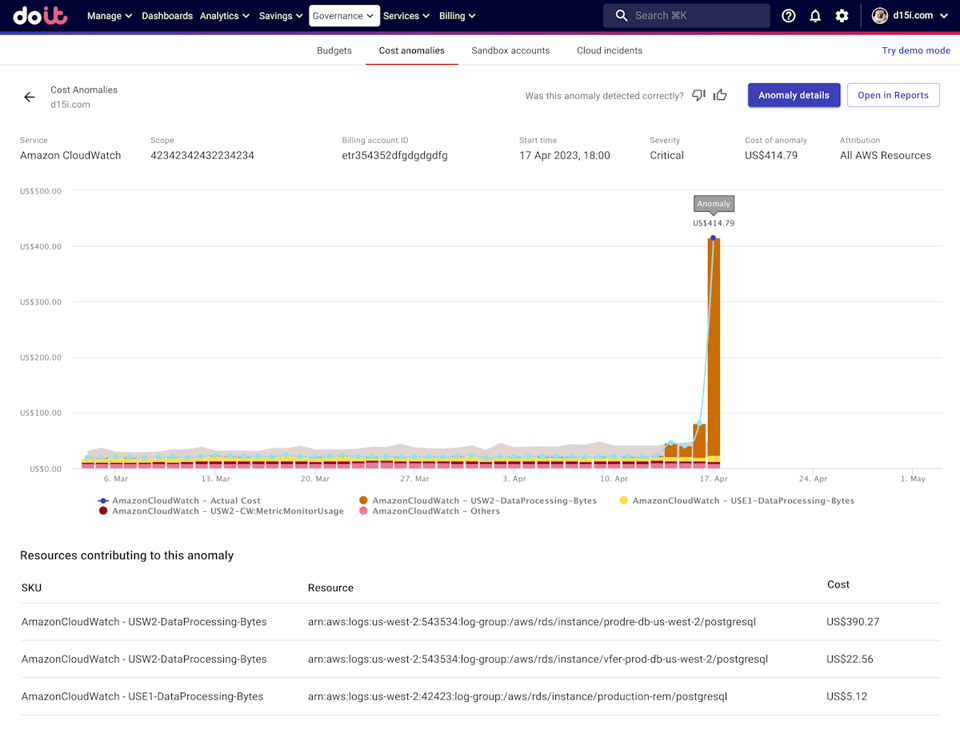 Source : Changelog DoiT
Source : Changelog DoiT
Dans le cloud, la détection d'anomalies va bien au-delà du simple monitoring. Parmi les applications courantes :
Gestion des coûts cloud
En gestion des coûts cloud, la détection d'anomalies repère tôt les schémas de dépenses inhabituels et permet aux équipes d'enquêter et de corriger avant l'arrivée de la facture de fin de mois. Moralis, par exemple, s'est associé à DoiT et a réalisé 10 % d'économies après mise en œuvre. Une approche proactive aide aussi à éviter les mauvaises surprises sur la facture cloud.
Monitoring de l'infrastructure
En monitoring d'infrastructure, la détection d'anomalies repère des écarts subtils dans les métriques de performance et permet d'anticiper les incidents avant qu'ils ne dégénèrent en pannes, faisant passer l'exploitation d'un mode pompier à une logique de prévention.
Monitoring de sécurité
Les équipes sécurité utilisent la détection d'anomalies pour faire émerger des schémas d'accès inhabituels, des comportements suspects et des compromissions potentielles, en particulier lorsque les attaques cherchent à se fondre dans une activité d'apparence normale.
Les défis de la détection d'anomalies
La détection d'anomalies peut apporter une valeur considérable, mais les déploiements concrets se heurtent à des écueils prévisibles. Les connaître à l'avance aide les équipes à éviter les pièges les plus courants.
Le dilemme de la qualité des données
Des baselines fiables exigent des données propres, pertinentes et en quantité suffisante. Des données incomplètes ou de mauvaise qualité rendent plus difficile la distinction entre variation normale et véritable anomalie, d'où des alertes peu fiables.
Le problème des faux positifs
Beaucoup de systèmes pèchent par faux positifs. Trop d'alertes provoquent une lassitude : les équipes finissent par ignorer les notifications, ce qui augmente le risque de passer à côté de vrais incidents. Le réglage de la sensibilité et des baselines tenant compte du contexte sont indispensables.
Le facteur coût
Traiter de gros volumes de données (facturation, logs, métriques) et entraîner des modèles peut être très gourmand en compute. Pour beaucoup d'organisations, gérer cela en interne ajoute une charge et une complexité opérationnelle.
Complexité de l'environnement cloud
Les usages du cloud changent fréquemment. Les services sont interdépendants et la consommation de ressources varie avec la demande. Les baselines doivent s'adapter en continu, sans devenir si tolérantes qu'elles passent à côté de vraies anomalies.
Intégration et alignement avec les workflows
La détection n'a de valeur que si elle s'intègre à la manière dont les équipes travaillent. Les alertes doivent être routées vers les bons interlocuteurs, embarquer un contexte exploitable et s'intégrer aux workflows d'incident et FinOps. Sans alignement ni accompagnement, même les meilleurs systèmes de détection sous-performent.
Bonnes pratiques pour mettre en place la détection d'anomalies
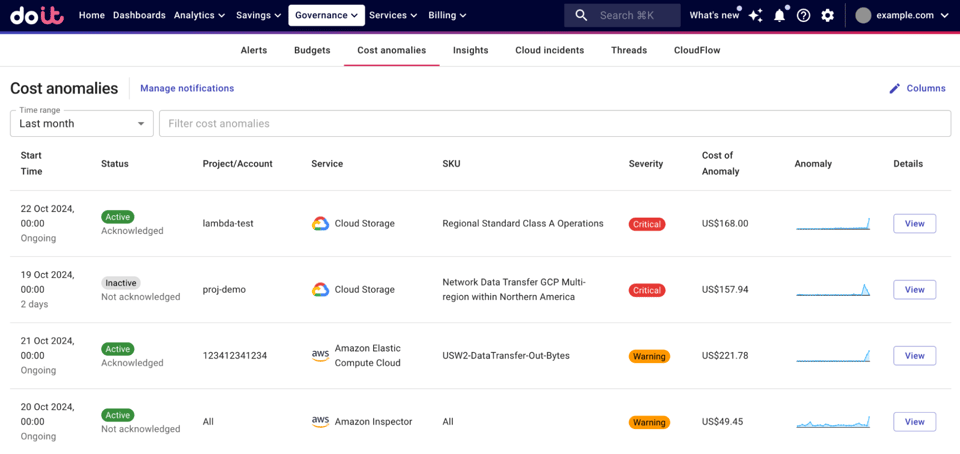 Source : Centre d'aide DoiT
Source : Centre d'aide DoiT
Définissez ce qu'est une anomalie dans votre environnement
Commencez par des objectifs clairs. Décidez quelles anomalies comptent vraiment (coût, fiabilité, sécurité) et fixez des indicateurs de succès : rapidité de détection, taux de faux positifs, délai de triage.
Privilégiez des alertes exploitables plutôt que nombreuses
Concevez les alertes autour des workflows. La sévérité doit dicter la réponse : qui est notifié, dans quel délai et quelles étapes suivent.
Préparez les mécanismes de réponse en amont
La détection n'est qu'une première étape. Construisez les capacités de réponse qui vont avec, par exemple :
- Des seuils dynamiques qui s'adaptent aux baselines.
- Une remédiation automatisée pour les correctifs à faible risque.
- Des garde-fous de scaling pour éviter les dérives d'usage.
- Un routage des notifications selon la sévérité et la responsabilité.
Affinez le système en continu
Les environnements cloud évoluent ; la détection d'anomalies doit suivre. Réentraînez les modèles, affinez les baselines, ajustez les seuils et suivez la performance dans la durée pour préserver la qualité du signal.
Documentez les chemins d'escalade et automatisez les actions répétables
Créez des playbooks clairs pour les types d'anomalies courants. Automatisez les réponses sûres et répétables pour que l'équipe consacre son temps à l'investigation et à la cause racine, plutôt qu'à des tâches manuelles répétitives.
FAQ : la détection d'anomalies par machine learning
Qu'est-ce que la détection d'anomalies en machine learning ?
La détection d'anomalies est une méthode qui consiste à identifier des points de données ou des comportements qui s'écartent significativement de ce qui est attendu. En machine learning, elle s'appuie souvent sur des modèles qui apprennent le comportement normal à partir de données historiques et signalent les événements rares ou inhabituels.
Quelle différence entre détection supervisée et non supervisée ?
La détection supervisée apprend à partir d'exemples étiquetés de comportements normaux et anormaux. La détection non supervisée n'a pas besoin d'étiquettes : elle apprend les comportements normaux à partir des données et signale les valeurs aberrantes. Dans le cloud, la non supervisée est courante car les anomalies étiquetées sont rares.
Pourquoi la détection d'anomalies est-elle importante pour la gestion des coûts cloud ?
Elle permet de repérer tôt les variations de dépenses inattendues, avant l'arrivée de la facture mensuelle, afin que les équipes puissent enquêter sur les mauvaises configurations, les usages imprévus ou le gaspillage, et limiter les surprises budgétaires.
Comment réduire les faux positifs en détection d'anomalies ?
Utilisez des baselines tenant compte du contexte (heure de la journée, jour de la semaine, saisonnalité), ajustez les seuils de sensibilité et routez les alertes selon la sévérité et la responsabilité. Associer aux alertes un contexte de cause racine permet aussi de réduire le bruit.
Rendre vos dépenses cloud plus prévisibles avec DoiT
Anomaly Detection, intégré à DoiT Cloud Intelligence, surveille vos dépenses cloud et signale les schémas inhabituels pour que vous puissiez enquêter avant que les surprises n'impactent votre budget.
Notre approche combine machine learning et expertise cloud pour fournir des alertes exploitables et adaptées à votre environnement. Découvrez comment DoiT permet une détection d'anomalies plus précise, alignée sur vos usages et vos besoins opérationnels.
Pour explorer la plateforme, consultez les options produit et tarifaires de DoiT et rendez vos dépenses cloud plus prévisibles et plus efficientes.