
Se você está tentando dominar a detecção de anomalias com machine learning, saiba que não está sozinho. Talvez já tenha gastado horas para entender por que o custo de nuvem disparou no mês passado — ou esteja com dificuldade para diferenciar picos normais de tráfego de possíveis ameaças à segurança.
Padrões inesperados em ambientes de nuvem podem comprometer a eficiência operacional e custar milhares se não forem tratados a tempo. As anomalias surgem de várias formas: aumentos repentinos no gasto com nuvem, comportamento irregular do sistema que afeta a performance ou atividades suspeitas que colocam dados sensíveis em risco.
A complexidade da nuvem acrescenta mais uma camada de dificuldade. Com tantos serviços e dependências, identificar a causa raiz nem sempre é simples. Para manter os sistemas confiáveis e reduzir riscos, os times precisam de uma forma de detectar e responder a outliers com agilidade e precisão.
Este guia explica o que é detecção de anomalias, os principais tipos para ficar de olho, as técnicas e algoritmos de machine learning mais comuns e boas práticas de implementação.
O que é detecção de anomalias?
 Fonte: DoiT Anomaly Detection
Fonte: DoiT Anomaly Detection
Em essência, a detecção de anomalias identifica padrões que fogem do comportamento esperado. Em ambientes de nuvem, ela funciona como um sistema imunológico: monitora o tempo todo, aprende como é o "normal" e sinaliza desvios relevantes.
As anomalias na nuvem costumam aparecer em duas frentes:
- Anomalias operacionais: mudanças de performance, confiabilidade ou comportamento do sistema (picos de latência, alterações na taxa de erros, padrões incomuns de acesso).
- Anomalias de custo: aumentos inesperados de gasto que podem ou não ter relação com mudanças de tráfego ou desempenho.
Esses tipos costumam se sobrepor (um pico de tráfego pode elevar tanto o gasto quanto a latência), mas anomalias de custo também podem ocorrer sem sintomas operacionais óbvios — uma configuração equivocada de logging, uma feature flag acionada por engano ou uma mudança de preço/uso, por exemplo.
Os sistemas modernos de detecção de anomalias evitam depender só de limites estáticos. Em vez disso, usam machine learning para se adaptar a baselines dinâmicos, que mudam por hora, dia ou estação do ano. Por exemplo: um pico de tráfego em uma plataforma de e-commerce durante a promoção anual é esperado — mas o mesmo pico em um dia de semana qualquer pode indicar um ataque de bots ou um deploy quebrado.
Tipos de anomalias para ficar de olho
Em ambientes de nuvem, as anomalias geralmente se dividem em segurança, operações e custo. Dentro dessas categorias, costumam aparecer em três tipos de padrão:
Anomalias pontuais
Um único ponto de dado drasticamente diferente dos demais — como um pico de 10x em chamadas de API ou um aumento repentino nos custos de transferência de dados. São fáceis de identificar, mas o difícil é determinar se são legítimas (um lançamento de produto) ou suspeitas (uso indevido de credenciais).
Anomalias contextuais
Comportamento que só é anômalo em um contexto específico — como uso alto de CPU, normal em horário de pico, mas preocupante às 3h da manhã. Esse tipo exige modelos que entendam tempo, sazonalidade e ciclos de negócio.
Anomalias coletivas
Um conjunto de eventos que parece normal isoladamente, mas se torna suspeito quando visto em conjunto — como requisições coordenadas que revelam um padrão de DDoS ou um aumento gradual de custo espalhado por vários serviços.
3 técnicas de detecção de anomalias para identificar problemas cedo
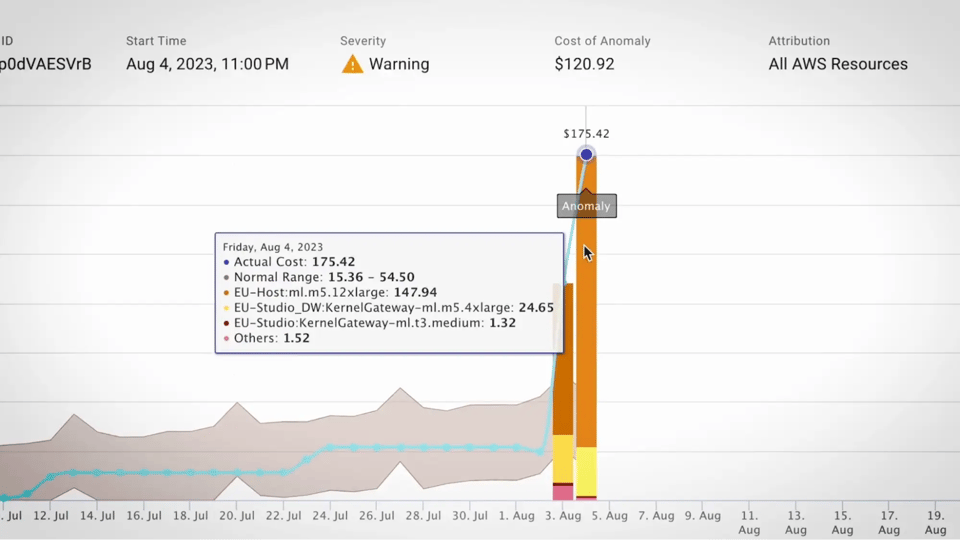 Fonte: Guia de ferramentas de FinOps
Fonte: Guia de ferramentas de FinOps
Cada técnica de detecção de anomalias funciona melhor em um cenário diferente. Na prática, os times de nuvem escolhem com base na disponibilidade de dados, na velocidade de mudança dos sistemas e nos tipos de anomalia que precisam capturar.
1) Detecção supervisionada
A detecção supervisionada treina modelos com exemplos rotulados de comportamento normal e anomalias conhecidas. Pode ser bastante precisa para problemas familiares, mas patina com eventos novos ou raros, para os quais não há exemplos.
2) Detecção não supervisionada
A detecção não supervisionada costuma ser a opção padrão em ambientes de nuvem porque dispensa dados de anomalia rotulados. Ela aprende como é o "normal" observando padrões ao longo do tempo e, então, sinaliza eventos raros ou significativamente diferentes.
Essa abordagem é especialmente útil quando os sistemas são novos (sem histórico rotulado) ou estão em constante mudança. À medida que o ambiente evolui, os métodos não supervisionados continuam se adaptando aos novos baselines.
3) Detecção semissupervisionada
A detecção semissupervisionada usa uma pequena quantidade de dados rotulados para ganhar precisão, mantendo a flexibilidade necessária para identificar problemas inéditos. É comum quando você tem exemplos confiáveis de "normal", mas poucos rótulos de anomalias.
Na prática, muitos sistemas de detecção de anomalias na nuvem se apoiam fortemente em métodos não supervisionados, porque esperar para coletar e rotular anomalias suficientes não é viável. Os melhores sistemas começam a proteger desde o primeiro momento e seguem aprendendo conforme os padrões mudam.
Algoritmos comuns para detecção de anomalias
Os sistemas de detecção de anomalias usam um leque de abordagens estatísticas, de machine learning e de deep learning — cada uma adequada a diferentes formatos de dados e necessidades operacionais.
Métodos estatísticos e baseados em regras
Métodos como análise de Z-score, intervalo interquartil (IQR) e thresholds simples funcionam bem para desvios claros em conjuntos de dados estáveis. São rápidos e fáceis de implementar, o que os torna úteis para detecção em tempo real em distribuições mais simples.
Métodos de machine learning
Para dados mais complexos, abordagens de ML acrescentam reconhecimento de padrões. Métodos baseados em árvore (incluindo isolation forests) são bastante usados porque anomalias tendem a ser raras e mais fáceis de isolar do que pontos normais, o que os torna eficientes para grandes volumes de dados.
Métodos de deep learning
Abordagens de deep learning — em especial os autoencoders — se destacam em dados de alta dimensionalidade nos quais o comportamento "normal" é complexo. Eles aprendem uma representação compactada dos padrões normais e sinalizam desvios quando o erro de reconstrução é alto.
Métodos de previsão de séries temporais
Quando os dados dependem do tempo, a previsão ajuda a definir as faixas esperadas. ARIMA e Prophet são bastante usados em padrões sazonais e tendências irregulares. Essas abordagens detectam anomalias comparando os valores reais com os baselines previstos.
Aplicações reais da detecção de anomalias
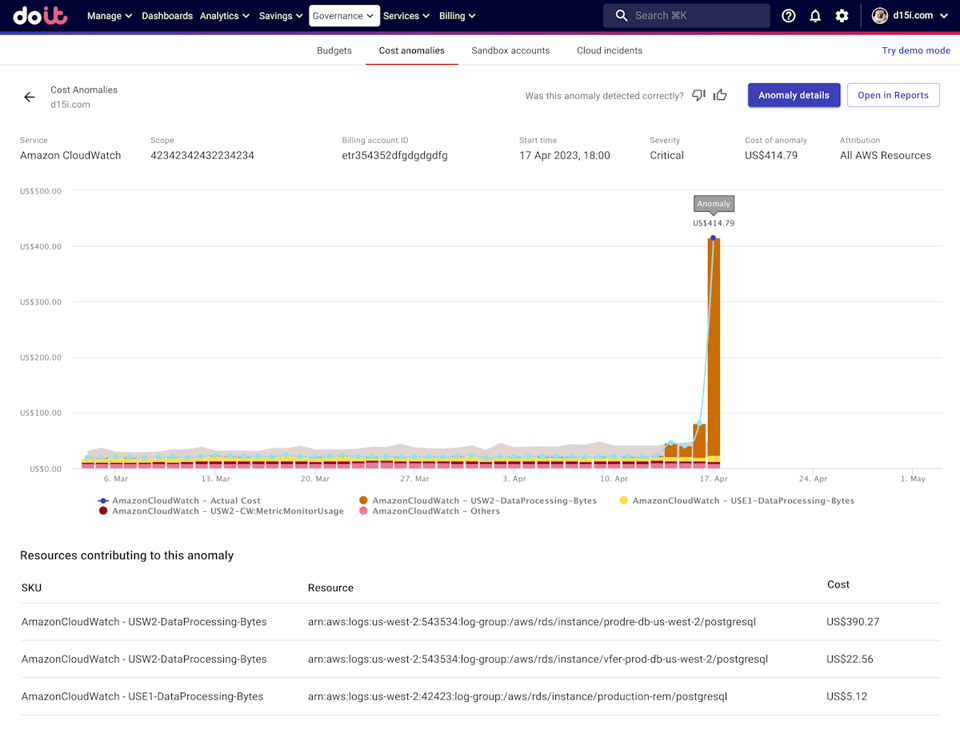 Fonte: Changelog DoiT
Fonte: Changelog DoiT
A detecção de anomalias em ambientes de nuvem vai muito além do monitoramento básico. Entre as aplicações mais comuns estão:
Gestão de custos de nuvem
Na gestão de custos de nuvem, a detecção de anomalias identifica padrões incomuns de gasto cedo, para que os times investiguem e corrijam antes do fechamento da fatura mensal. A Moralis, por exemplo, fechou parceria com a DoiT e obteve 10% de economia após a implementação. Uma postura proativa também ajuda a evitar surpresas na fatura da nuvem.
Monitoramento de infraestrutura
No monitoramento de infraestrutura, a detecção de anomalias identifica desvios sutis nas métricas de desempenho e ajuda a antecipar problemas antes que virem indisponibilidade — tirando a operação do modo "apaga incêndio" e levando-a à prevenção proativa.
Monitoramento de segurança
Os times de segurança usam a detecção de anomalias para identificar padrões incomuns de acesso, comportamentos suspeitos e possíveis violações — sobretudo quando os ataques tentam se camuflar em meio à atividade "aparentemente normal".
Desafios da detecção de anomalias
A detecção de anomalias entrega muito valor, mas implementações no mundo real esbarram em obstáculos previsíveis. Conhecê-los desde o início ajuda os times a evitar os tropeços mais comuns.
O dilema da qualidade dos dados
Baselines confiáveis exigem volume suficiente de dados limpos e relevantes. Dados ruins ou incompletos dificultam separar a variação normal das anomalias reais — o que gera alertas imprecisos.
O problema dos falsos positivos
Muitos sistemas patinam em falsos positivos. Excesso de alerta gera fadiga, e o time começa a ignorar as notificações — o que aumenta o risco de deixar passar problemas reais. Ajustar a sensibilidade e usar baselines com contexto é essencial.
O fator custo
Processar grandes volumes de dados (faturamento, logs, métricas) e treinar modelos pode pesar no poder computacional. Para muitas empresas, fazer isso internamente acrescenta overhead e complexidade operacional.
Complexidade do ambiente de nuvem
Os padrões de uso da nuvem mudam o tempo todo. Os serviços são interdependentes, e o consumo de recursos varia conforme a demanda. Os baselines precisam se adaptar continuamente, sem ficarem tão frouxos a ponto de deixar passar anomalias reais.
Integração e alinhamento de workflow
A detecção só importa se conversar com a forma como os times trabalham. Os alertas precisam chegar aos responsáveis certos, trazer contexto acionável e se integrar aos workflows de incidentes e de FinOps. Sem alinhamento e capacitação, mesmo sistemas robustos de detecção entregam abaixo do esperado.
Boas práticas para implementar a detecção de anomalias
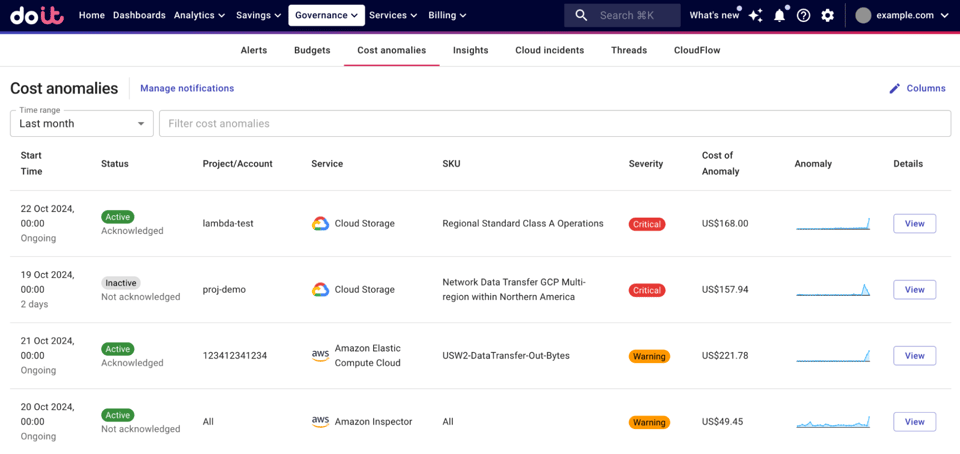 Fonte: Central de Ajuda DoiT
Fonte: Central de Ajuda DoiT
Defina o que "anomalia" significa para o seu ambiente
Comece com objetivos claros. Decida quais anomalias importam (custo, confiabilidade, segurança) e defina métricas de sucesso, como velocidade de detecção, taxa de falsos positivos e tempo de triagem.
Priorize alertas acionáveis em vez de mais alertas
Desenhe os alertas a partir dos workflows. A severidade deve guiar a resposta: quem é notificado, com que rapidez e quais os próximos passos.
Planeje os mecanismos de resposta com antecedência
Detectar é só o primeiro passo. Construa também a capacidade de resposta, com itens como:
- Limites dinâmicos que se adaptam aos baselines.
- Remediação automatizada para correções de baixo risco.
- Guardrails de scaling para evitar consumo descontrolado.
- Roteamento de notificações por severidade e responsabilidade.
Ajuste o sistema continuamente
Ambientes de nuvem evoluem; a detecção de anomalias precisa evoluir junto. Retreine os modelos, refine os baselines, ajuste os limites e acompanhe o desempenho ao longo do tempo para manter a qualidade do sinal.
Documente caminhos de escalonamento e automatize ações repetitivas
Crie playbooks claros para os tipos mais comuns de anomalia. Automatize respostas seguras e repetíveis, para que o time invista tempo em investigação e causa raiz — e não em trabalho manual repetitivo.
FAQ: Detecção de anomalias com machine learning
O que é detecção de anomalias em machine learning?
Detecção de anomalias é um método para identificar pontos de dados ou padrões que se desviam significativamente do comportamento esperado. Em machine learning, normalmente se usam modelos que aprendem o comportamento normal a partir de padrões históricos e sinalizam eventos raros ou incomuns.
Qual é a diferença entre detecção supervisionada e não supervisionada?
A detecção supervisionada aprende a partir de exemplos rotulados de comportamento normal e anômalo. A não supervisionada não exige rótulos: aprende padrões normais a partir dos dados e sinaliza outliers. Em ambientes de nuvem, a abordagem não supervisionada é a mais comum, porque anomalias rotuladas são raras.
Por que a detecção de anomalias é importante para a gestão de custos de nuvem?
A detecção de anomalias identifica mudanças inesperadas de gasto cedo — antes da fatura mensal chegar — para que os times investiguem configurações equivocadas, uso inesperado ou desperdício e reduzam surpresas no orçamento.
Como reduzir falsos positivos na detecção de anomalias?
Use baselines com contexto (hora do dia, dia da semana, sazonalidade), ajuste os limites de sensibilidade e roteie os alertas por severidade e responsabilidade. Combinar os alertas com contexto de causa raiz também reduz o ruído.
Mais previsibilidade no gasto com nuvem com a DoiT
O Anomaly Detection da DoiT Cloud Intelligence monitora o gasto com nuvem e sinaliza padrões incomuns para que você investigue antes que surpresas afetem seu orçamento.
Nossa abordagem une machine learning à expertise em nuvem para entregar alertas acionáveis, sob medida para o seu ambiente. Veja como a DoiT viabiliza uma detecção de anomalias mais precisa, alinhada aos seus padrões de uso e às suas necessidades operacionais.
Se quiser conhecer a plataforma a fundo, confira as opções de produto e preços da DoiT para tornar o gasto com nuvem mais previsível e eficiente.