
Se sta cercando di padroneggiare l'anomaly detection con il machine learning, non è il solo. Magari ha passato ore a capire perché i costi cloud sono schizzati il mese scorso, oppure fatica a distinguere i normali picchi di traffico da potenziali minacce alla sicurezza.
Pattern imprevisti negli ambienti cloud possono erodere l'efficienza operativa e costare migliaia di euro se non vengono affrontati in tempi rapidi. Le anomalie si manifestano in molti modi: aumenti improvvisi della spesa cloud, comportamenti irregolari del sistema che penalizzano le prestazioni o attività sospette che mettono a rischio dati sensibili.
La complessità del cloud aggiunge un ulteriore livello di difficoltà. La molteplicità di servizi e dipendenze rende complicato risalire alla causa originaria. Per garantire l'affidabilità dei sistemi e ridurre i rischi, i team hanno bisogno di un metodo per individuare gli outlier e reagire in modo rapido e accurato.
Questa guida illustra cos'è l'anomaly detection, le principali tipologie di anomalie da tenere d'occhio, le tecniche e gli algoritmi di machine learning più diffusi e le best practice per l'implementazione.
Cos'è l'anomaly detection?
 Fonte: DoiT Anomaly Detection
Fonte: DoiT Anomaly Detection
In sostanza, l'anomaly detection individua pattern che si discostano dal comportamento atteso. Negli ambienti cloud agisce come un sistema immunitario: monitora costantemente, impara cosa significa "normale" e segnala le deviazioni rilevanti.
Le anomalie cloud emergono di solito in due ambiti:
- Anomalie operative: variazioni di prestazioni, affidabilità o comportamento del sistema (picchi di latenza, oscillazioni del tasso di errore, pattern di accesso insoliti).
- Anomalie di costo: aumenti imprevisti della spesa, correlati o meno a variazioni di traffico o prestazioni.
Spesso si sovrappongono (un picco di traffico può far salire sia la spesa sia la latenza), ma le anomalie di costo possono comparire anche senza sintomi operativi evidenti: una configurazione errata del logging, un feature flag attivato per sbaglio o un cambio di prezzo o utilizzo.
I sistemi moderni di anomaly detection non si affidano più alle sole soglie statiche. Sfruttano invece il machine learning per adattarsi a baseline dinamiche che variano in base all'ora, al giorno o alla stagione. Per esempio, il picco di traffico di una piattaforma e-commerce durante i saldi annuali è atteso, mentre lo stesso picco in un giorno feriale qualsiasi può segnalare un attacco bot o un deployment difettoso.
Tipologie di anomalie da tenere d'occhio
Negli ambienti cloud le anomalie ricadono di norma in tre categorie: sicurezza, operations e costi. All'interno di queste, tendono a presentarsi secondo tre pattern principali:
Anomalie puntuali
Un singolo data point nettamente diverso dagli altri, come un picco di 10 volte nelle chiamate API o un'impennata improvvisa nei costi di trasferimento dati. Sono in genere facili da individuare; la sfida sta nel capire se siano legittime (un lancio di prodotto) o sospette (uso improprio di credenziali).
Anomalie contestuali
Comportamenti anomali solo in un contesto specifico: per esempio, una CPU elevata è normale nelle ore di punta ma desta preoccupazione alle 3 di notte. Richiedono modelli capaci di interpretare il tempo, la stagionalità e i cicli di business.
Anomalie collettive
Un insieme di eventi che, presi singolarmente, sembrano normali, ma che diventano sospetti se osservati nel loro complesso: per esempio, richieste coordinate che rivelano un pattern DDoS o un lento aumento dei costi distribuito su più servizi.
3 tecniche di anomaly detection per individuare i problemi sul nascere
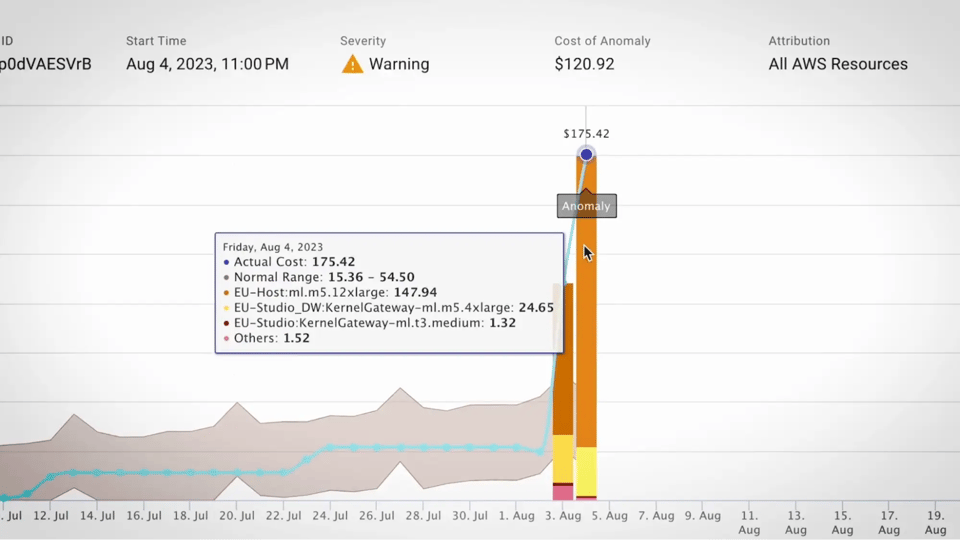 Fonte: Guida ai tool FinOps
Fonte: Guida ai tool FinOps
Tecniche di anomaly detection diverse rendono al meglio in ambienti diversi. In pratica, i team cloud scelgono in base alla disponibilità dei dati, alla rapidità con cui i sistemi cambiano e alle tipologie di anomalie da intercettare.
1) Rilevamento supervisionato
Il rilevamento supervisionato addestra i modelli con esempi etichettati di comportamento normale e di anomalie note. Può essere molto accurato sui problemi già conosciuti, ma fatica con eventi nuovi o rari di cui non si hanno esempi.
2) Rilevamento non supervisionato
Il rilevamento non supervisionato è spesso la scelta predefinita per gli ambienti cloud, perché non richiede dati di anomalia etichettati. Apprende cosa significa "normale" osservando i pattern nel tempo, per poi segnalare gli eventi rari o significativamente diversi.
È un approccio particolarmente utile quando i sistemi sono nuovi (nessuno storico etichettato) o in continua evoluzione. Man mano che l'ambiente cambia, i metodi non supervisionati continuano ad adattarsi alle nuove baseline.
3) Rilevamento semi-supervisionato
Il rilevamento semi-supervisionato utilizza una piccola quantità di dati etichettati per migliorare l'accuratezza, mantenendo la flessibilità necessaria per intercettare problemi mai visti prima. Si usa spesso quando si dispone di esempi affidabili di "normale", ma di pochi label di anomalia.
Nella realtà, molti sistemi cloud di anomaly detection si appoggiano in larga misura ai metodi non supervisionati, perché aspettare di raccogliere ed etichettare un numero sufficiente di anomalie non è praticabile. I sistemi migliori iniziano a proteggere fin da subito e continuano ad apprendere mentre i pattern evolvono.
Algoritmi più diffusi per l'anomaly detection
I sistemi di anomaly detection ricorrono a un ventaglio di approcci statistici, di machine learning e di deep learning, ciascuno adatto a forme di dati ed esigenze operative diverse.
Metodi statistici e basati su regole
Tecniche come l'analisi Z-score, l'intervallo interquartile (IQR) e il semplice thresholding funzionano bene per deviazioni evidenti su dataset stabili. Sono rapide e facili da implementare, il che le rende utili per il rilevamento in tempo reale su distribuzioni semplici.
Metodi di machine learning
Per dati più complessi, gli approcci ML aggiungono il riconoscimento di pattern. I metodi basati su alberi (incluse le isolation forest) sono molto utilizzati perché le anomalie tendono a essere rare e più facili da isolare rispetto ai punti normali, risultando efficienti su dataset di grandi dimensioni.
Metodi di deep learning
Gli approcci di deep learning, in particolare gli autoencoder, eccellono sui dati ad alta dimensionalità in cui il comportamento "normale" è complesso. Apprendono una rappresentazione compressa dei pattern normali e segnalano le deviazioni quando l'errore di ricostruzione è elevato.
Metodi di forecasting su serie temporali
Quando i dati dipendono dal tempo, il forecasting aiuta a definire gli intervalli attesi. ARIMA e Prophet sono spesso impiegati per pattern stagionali e trend irregolari. Questi approcci consentono di rilevare anomalie confrontando i valori reali con le baseline previste.
Applicazioni concrete dell'anomaly detection
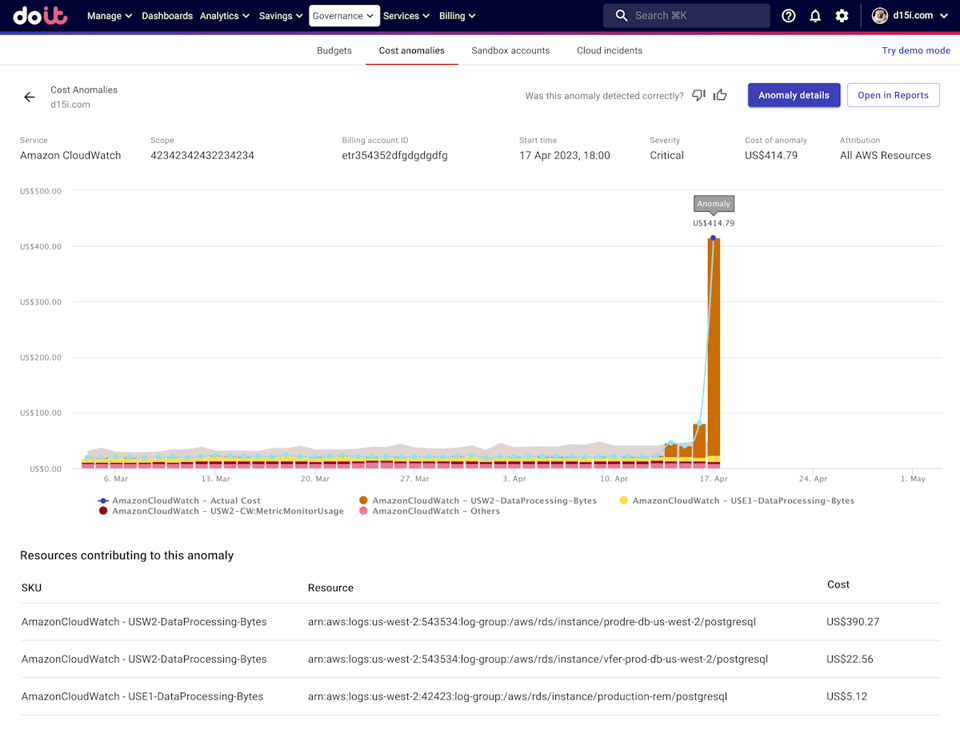 Fonte: Changelog DoiT
Fonte: Changelog DoiT
Negli ambienti cloud l'anomaly detection va ben oltre il monitoraggio di base. Tra le applicazioni più diffuse ci sono:
Gestione dei costi cloud
Nella gestione dei costi cloud, l'anomaly detection individua pattern di spesa anomali con tempestività, così i team possono indagare e intervenire prima dell'arrivo della fattura di fine mese. Moralis, per esempio, ha collaborato con DoiT ottenendo un risparmio del 10% sui costi dopo l'implementazione. Un approccio proattivo aiuta anche a ridurre le sorprese in fattura cloud.
Monitoraggio dell'infrastruttura
Nel monitoraggio dell'infrastruttura, l'anomaly detection può individuare deviazioni sottili nelle metriche di prestazione e aiutare a prevedere i problemi prima che diventino disservizi, spostando le operations dalla gestione reattiva delle emergenze alla prevenzione proattiva.
Monitoraggio della sicurezza
I team di sicurezza sfruttano l'anomaly detection per portare alla luce pattern di accesso insoliti, comportamenti sospetti e potenziali violazioni, soprattutto quando gli attacchi cercano di mimetizzarsi tra le attività "apparentemente normali".
Le sfide dell'anomaly detection
L'anomaly detection può generare un valore enorme, ma le implementazioni reali si scontrano con ostacoli ricorrenti. Conoscerli in anticipo aiuta i team a evitare i tipici punti di fallimento.
Il dilemma della qualità dei dati
Baseline affidabili richiedono una quantità sufficiente di dati puliti e pertinenti. Dati di scarsa qualità o incompleti rendono più difficile distinguere la normale variabilità dalle vere anomalie, generando alert imprecisi.
Il problema dei falsi positivi
Molti sistemi soffrono di falsi positivi. Troppi alert generano stanchezza e i team iniziano a ignorare le notifiche, aumentando il rischio di lasciarsi sfuggire problemi reali. Tuning della sensibilità e baseline contestualizzate sono indispensabili.
Il fattore costo
Elaborare grandi volumi di dati (billing, log, metriche) e addestrare i modelli può essere oneroso in termini di calcolo. Per molte organizzazioni, gestire tutto in casa significa overhead e complessità operativa aggiuntivi.
Complessità degli ambienti cloud
I pattern di utilizzo del cloud cambiano di frequente. I servizi sono interdipendenti e il consumo di risorse varia con la domanda. Le baseline devono adattarsi in modo continuo senza diventare così permissive da non rilevare più le anomalie reali.
Integrazione e allineamento dei workflow
Il rilevamento ha senso solo se si integra con il modo in cui lavorano i team. Gli alert devono raggiungere i responsabili giusti, includere un contesto azionabile e integrarsi con i workflow di incident management e FinOps. Senza allineamento e formazione, anche i migliori sistemi di rilevamento rendono meno del previsto.
Best practice per implementare l'anomaly detection
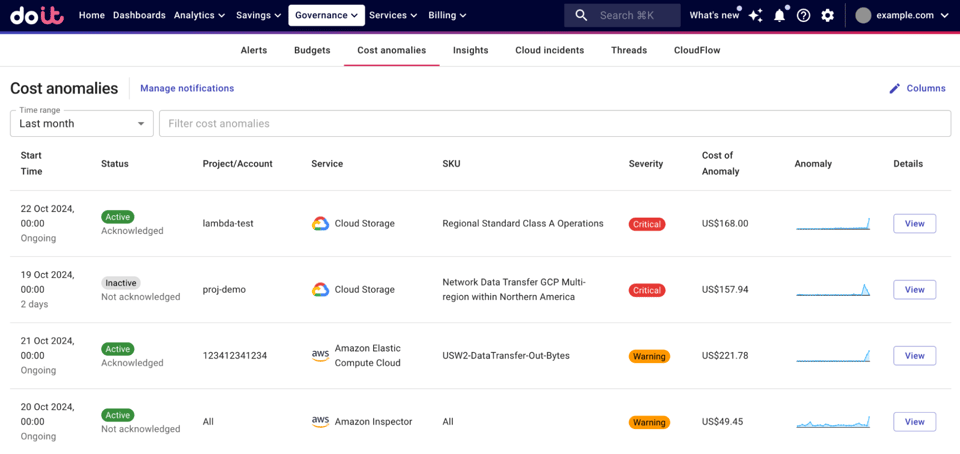 Fonte: Centro assistenza DoiT
Fonte: Centro assistenza DoiT
Definisca cosa significa "anomalia" nel suo ambiente
Parta da obiettivi chiari. Decida quali anomalie sono rilevanti (costo, affidabilità, sicurezza) e definisca metriche di successo come velocità di rilevamento, tasso di falsi positivi e tempo di triage.
Privilegi alert azionabili, non più alert
Progetti gli alert intorno ai workflow. La gravità deve corrispondere alla risposta: chi viene notificato, con quale tempestività e quali passi compie successivamente.
Pianifichi in anticipo i meccanismi di risposta
Il rilevamento è solo il primo passo. Sviluppi capacità di risposta come:
- Soglie dinamiche che si adattano alle baseline.
- Remediation automatizzata per le correzioni a basso rischio.
- Guardrail di scaling per evitare consumi fuori controllo.
- Routing delle notifiche basato su gravità e responsabilità.
Ottimizzi il sistema in modo continuativo
Gli ambienti cloud evolvono e l'anomaly detection deve evolvere con loro. Riaddestri i modelli, affini le baseline, regoli le soglie e monitori le prestazioni nel tempo per mantenere alta la qualità del segnale.
Documenti i percorsi di escalation e automatizzi le azioni ripetibili
Crei playbook chiari per le tipologie di anomalie più comuni. Automatizzi le risposte sicure e ripetibili, così il team può concentrarsi sull'indagine e sull'analisi delle cause originarie, non su attività manuali ripetitive.
FAQ: anomaly detection con il machine learning
Cos'è l'anomaly detection nel machine learning?
L'anomaly detection è un metodo per identificare data point o pattern che si discostano in modo significativo dal comportamento atteso. Nel machine learning si avvale spesso di modelli che apprendono il comportamento normale dai pattern storici e segnalano gli eventi rari o insoliti.
Qual è la differenza tra anomaly detection supervisionata e non supervisionata?
Il rilevamento supervisionato apprende da esempi etichettati di comportamento normale e anomalo. Quello non supervisionato non richiede etichette: apprende i pattern normali dai dati e segnala gli outlier. Negli ambienti cloud è più diffuso quello non supervisionato, perché le anomalie etichettate sono rare.
Perché l'anomaly detection è importante per la gestione dei costi cloud?
L'anomaly detection può individuare in anticipo variazioni di spesa impreviste, prima dell'arrivo della fattura mensile, così i team possono indagare su misconfigurazioni, utilizzi anomali o sprechi e ridurre le sorprese di budget.
Come si riducono i falsi positivi nell'anomaly detection?
Utilizzi baseline contestualizzate (ora del giorno, giorno della settimana, stagionalità), affini le soglie di sensibilità e indirizzi gli alert in base a gravità e responsabilità. Affiancare agli alert il contesto sulla causa originaria contribuisce a ridurre il rumore.
Una spesa cloud più prevedibile con DoiT
Anomaly Detection in DoiT Cloud Intelligence monitora la spesa cloud e segnala i pattern insoliti, così può intervenire prima che le sorprese mettano sotto pressione il budget.
Il nostro approccio combina machine learning ed expertise sul cloud per offrire alert azionabili e calibrati sul suo ambiente. Scopra come DoiT abilita un'anomaly detection più precisa, allineata ai suoi pattern di utilizzo e alle sue esigenze operative.
Se desidera approfondire la piattaforma, può consultare le opzioni di prodotto e i piani di prezzo di DoiT per rendere la spesa cloud più prevedibile ed efficiente.