
Wenn Sie sich gerade in das Thema Anomalieerkennung mit Machine Learning einarbeiten, geht es Ihnen wie vielen anderen. Vielleicht haben Sie schon Stunden damit verbracht herauszufinden, warum Ihre Cloud-Kosten letzten Monat in die Höhe geschossen sind – oder Sie tun sich schwer, normale Traffic-Spitzen von potenziellen Sicherheitsbedrohungen zu unterscheiden.
Unerwartete Muster in Cloud-Umgebungen können die operative Effizienz untergraben und schnell vierstellige Beträge kosten, wenn niemand zügig gegensteuert. Anomalien zeigen sich auf vielfältige Weise: plötzlich steigende Cloud-Ausgaben, unregelmäßiges Systemverhalten, das die Performance ausbremst, oder verdächtige Aktivitäten, die sensible Daten gefährden.
Die Komplexität der Cloud erschwert das Ganze zusätzlich. Zahlreiche Services und Abhängigkeiten machen es oft schwierig, die Ursache präzise einzugrenzen. Damit Systeme zuverlässig bleiben und Risiken sinken, brauchen Teams einen Weg, Ausreißer schnell und treffsicher zu erkennen und gezielt zu reagieren.
Dieser Leitfaden erklärt, was Anomalieerkennung ist, welche Anomalietypen Sie im Blick behalten sollten, welche Machine-Learning-Techniken und Algorithmen sich etabliert haben und welche Best Practices sich in der Praxis bewähren.
Was ist Anomalieerkennung?
 Quelle: DoiT Anomaly Detection
Quelle: DoiT Anomaly Detection
Im Kern erkennt die Anomalieerkennung Muster, die vom erwarteten Verhalten abweichen. In Cloud-Umgebungen wirkt sie wie ein Immunsystem: Sie überwacht laufend, lernt, wie "normal" aussieht, und meldet relevante Abweichungen.
Cloud-Anomalien zeigen sich typischerweise in zwei Bereichen:
- Operative Anomalien: Veränderungen bei Performance, Zuverlässigkeit oder Systemverhalten (Latenzspitzen, Veränderungen bei Fehlerraten, ungewöhnliche Zugriffsmuster).
- Kostenanomalien: unerwartete Ausgabenanstiege, die mit Traffic- oder Performance-Veränderungen einhergehen können – aber nicht müssen.
Beide Bereiche überschneiden sich häufig (eine Traffic-Welle treibt sowohl Kosten als auch Latenz nach oben), Kostenanomalien können aber auch ohne offensichtliche operative Symptome auftreten – etwa durch eine fehlerhafte Logging-Konfiguration, ein versehentlich aktiviertes Feature-Flag oder eine Preis- bzw. Nutzungsänderung.
Moderne Systeme zur Anomalieerkennung verlassen sich nicht ausschließlich auf statische Schwellenwerte. Stattdessen passen sie sich per Machine Learning an dynamische Baselines an, die sich nach Stunde, Tag oder Saison verändern. Beispiel: Eine Traffic-Spitze auf einer E-Commerce-Plattform während des jährlichen Sales ist erwartbar – derselbe Anstieg an einem beliebigen Wochentag kann hingegen auf einen Bot-Angriff oder ein fehlerhaftes Deployment hindeuten.
Anomalietypen, die Sie im Blick behalten sollten
In Cloud-Umgebungen lassen sich Anomalien meist den Kategorien Sicherheit, Betrieb und Kosten zuordnen. Quer durch diese Kategorien zeigen sie sich in drei typischen Mustern:
Punktuelle Anomalien
Ein einzelner Datenpunkt, der drastisch vom Rest abweicht – zum Beispiel eine Verzehnfachung der API-Aufrufe oder ein plötzlicher Anstieg der Datenübertragungskosten. Solche Ausreißer sind oft leicht zu erkennen; die eigentliche Herausforderung besteht darin, einzuschätzen, ob sie legitim (Produkt-Launch) oder verdächtig (Missbrauch von Zugangsdaten) sind.
Kontextuelle Anomalien
Verhalten, das nur in einem bestimmten Kontext anomal ist – etwa eine hohe CPU-Auslastung, die zu Stoßzeiten normal, um 3 Uhr nachts aber bedenklich ist. Hier braucht es Modelle, die Tageszeit, Saisonalität und Geschäftszyklen verstehen.
Kollektive Anomalien
Eine Reihe von Ereignissen, die einzeln betrachtet normal wirken, in der Summe aber verdächtig werden – etwa koordinierte Anfragen, die ein DDoS-Muster offenbaren, oder ein schleichender Kostenanstieg, der sich über mehrere Services verteilt.
3 Techniken, mit denen Sie Anomalien früh erkennen
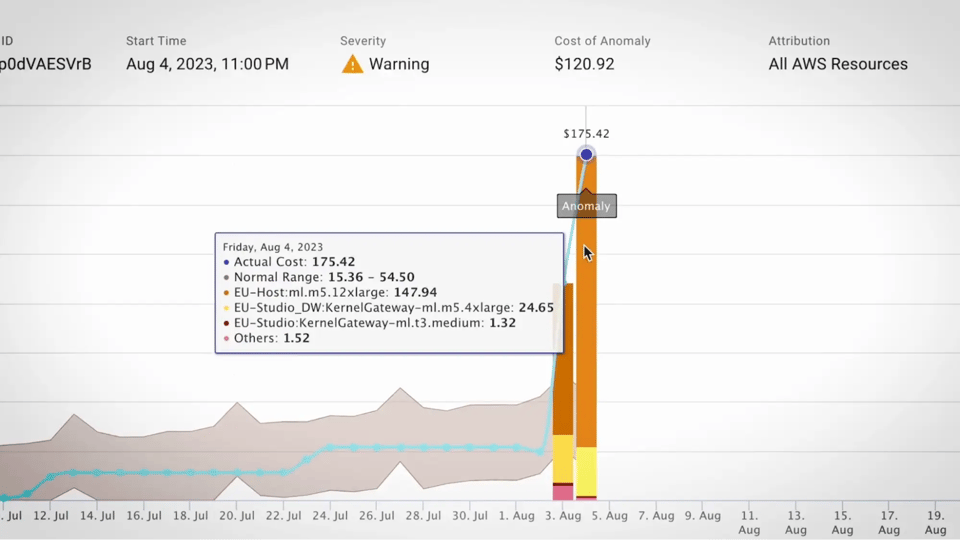 Quelle: FinOps tools guide
Quelle: FinOps tools guide
Welche Technik zur Anomalieerkennung am besten passt, hängt von der Umgebung ab. In der Praxis entscheiden Cloud-Teams nach verfügbaren Daten, Veränderungstempo der Systeme und den Anomalietypen, die sie erkennen müssen.
1) Überwachte Erkennung
Die überwachte Erkennung trainiert Modelle mit gelabelten Beispielen für normales Verhalten und bekannte Anomalien. Bei vertrauten Problemen liefert sie sehr präzise Ergebnisse, scheitert aber bei neuen oder seltenen Ereignissen, für die keine Beispiele vorliegen.
2) Unüberwachte Erkennung
Die unüberwachte Erkennung ist in Cloud-Umgebungen häufig die Standardwahl, weil sie keine gelabelten Anomaliedaten benötigt. Sie lernt anhand der Muster im Zeitverlauf, wie "normal" aussieht, und meldet anschließend Ereignisse, die selten oder deutlich abweichend sind.
Dieser Ansatz bewährt sich besonders, wenn Systeme neu sind (keine gelabelte Historie) oder sich permanent verändern. Während sich Ihre Umgebung weiterentwickelt, passen sich unüberwachte Verfahren laufend an neue Baselines an.
3) Halbüberwachte Erkennung
Die halbüberwachte Erkennung nutzt eine kleine Menge gelabelter Daten, um die Genauigkeit zu erhöhen, bleibt aber flexibel genug, um auch bisher unbekannte Probleme zu entdecken. Sie kommt häufig zum Einsatz, wenn zuverlässige Beispiele für "normal" vorliegen, aber nur wenige Anomalie-Labels.
In der Praxis setzen viele Systeme zur Cloud-Anomalieerkennung stark auf unüberwachte Verfahren, weil es schlicht nicht praktikabel ist, lange auf ausreichend gelabelte Anomalien zu warten. Die besten Systeme schützen sofort und lernen kontinuierlich weiter, während sich die Muster verändern.
Gängige Algorithmen für die Anomalieerkennung
Systeme zur Anomalieerkennung greifen auf eine Reihe statistischer, Machine-Learning- und Deep-Learning-Ansätze zurück – jeweils zugeschnitten auf unterschiedliche Datenstrukturen und betriebliche Anforderungen.
Statistische und regelbasierte Verfahren
Methoden wie Z-Score-Analyse, Interquartilsabstand (IQR) und einfache Schwellenwerte eignen sich gut für klare Abweichungen in stabilen Datensätzen. Sie sind schnell und leicht umzusetzen – und damit attraktiv für die Echtzeit-Erkennung bei einfachen Verteilungen.
Machine-Learning-Verfahren
Bei komplexeren Daten kommt mit ML-Ansätzen Mustererkennung ins Spiel. Baumbasierte Verfahren (darunter Isolation Forests) sind weit verbreitet, weil Anomalien typischerweise selten sind und sich leichter isolieren lassen als normale Datenpunkte – das macht sie für große Datensätze effizient.
Deep-Learning-Verfahren
Deep-Learning-Ansätze – insbesondere Autoencoder – spielen ihre Stärken bei hochdimensionalen Daten aus, in denen "normales" Verhalten komplex ist. Sie lernen eine komprimierte Repräsentation normaler Muster und schlagen Alarm, sobald der Rekonstruktionsfehler hoch ausfällt.
Zeitreihen-Forecasting-Verfahren
Bei zeitabhängigen Daten hilft Forecasting dabei, erwartbare Wertebereiche zu definieren. ARIMA und Prophet werden häufig bei saisonalen Mustern und unregelmäßigen Trends eingesetzt. Sie erkennen Anomalien, indem sie tatsächliche Werte mit prognostizierten Baselines abgleichen.
Anomalieerkennung in der Praxis
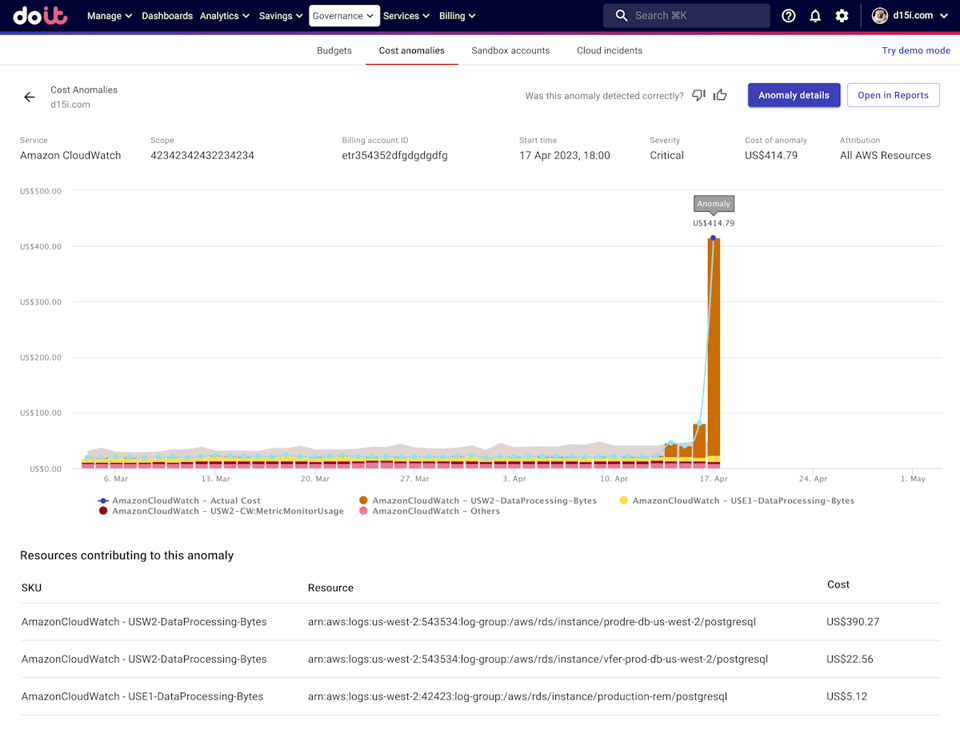 Quelle: DoiT changelog
Quelle: DoiT changelog
Anomalieerkennung in Cloud-Umgebungen geht weit über klassisches Monitoring hinaus. Typische Anwendungsfälle sind:
Cloud-Kostenmanagement
Im Cloud-Kostenmanagement deckt die Anomalieerkennung ungewöhnliche Ausgabenmuster frühzeitig auf, sodass Teams nachfassen und gegensteuern können, bevor die Monatsrechnung eintrifft. Beispiel: Moralis hat sich für DoiT entschieden und nach der Implementierung 10 % Kosteneinsparungen erzielt. Ein proaktiver Ansatz hilft zudem, böse Überraschungen bei der Cloud-Rechnung zu vermeiden.
Infrastruktur-Monitoring
Im Infrastruktur-Monitoring spürt die Anomalieerkennung subtile Abweichungen in Performance-Metriken auf und hilft, Probleme früh zu erkennen, bevor daraus Ausfälle werden – der Betrieb wechselt vom reaktiven Krisenmodus in eine proaktive Vorsorge.
Security-Monitoring
Security-Teams nutzen Anomalieerkennung, um auffällige Zugriffsmuster, verdächtiges Verhalten und potenzielle Sicherheitsvorfälle aufzudecken – besonders dann, wenn Angriffe versuchen, sich in "normal aussehender" Aktivität zu tarnen.
Herausforderungen bei der Anomalieerkennung
Anomalieerkennung kann enormen Mehrwert liefern – in der Praxis stoßen Implementierungen jedoch auf wiederkehrende Hürden. Wer sie kennt, vermeidet typische Stolperfallen.
Das Datenqualitäts-Dilemma
Verlässliche Baselines brauchen ausreichend saubere und relevante Daten. Mangelhafte oder unvollständige Daten erschweren die Unterscheidung zwischen normaler Schwankung und echter Anomalie – das Ergebnis sind ungenaue Alarme.
Das Problem der False Positives
Viele Systeme kämpfen mit False Positives. Zu viele Alarme führen zu Alert-Fatigue, Teams beginnen, Benachrichtigungen zu ignorieren – und übersehen so echte Probleme. Sensitivitäts-Tuning und kontextbewusste Baselines sind hier unverzichtbar.
Der Kostenfaktor
Die Verarbeitung großer Datenmengen (Billing, Logs, Metriken) und das Training der Modelle kann sehr rechenintensiv sein. Für viele Organisationen bedeutet ein Inhouse-Betrieb zusätzlichen Overhead und operative Komplexität.
Komplexität der Cloud-Umgebung
Cloud-Nutzungsmuster verändern sich häufig. Services hängen voneinander ab, der Ressourcenverbrauch schwankt mit der Nachfrage. Baselines müssen sich kontinuierlich anpassen – ohne so weich zu werden, dass echte Anomalien durchrutschen.
Integration und Workflow-Abstimmung
Erkennung bringt nur dann etwas, wenn sie zur Arbeitsweise der Teams passt. Alarme müssen die richtigen Verantwortlichen erreichen, umsetzbaren Kontext liefern und sich in Incident- und FinOps-Workflows einfügen. Ohne Abstimmung und Schulung bleiben selbst starke Erkennungssysteme hinter ihren Möglichkeiten zurück.
Best Practices für die Einführung der Anomalieerkennung
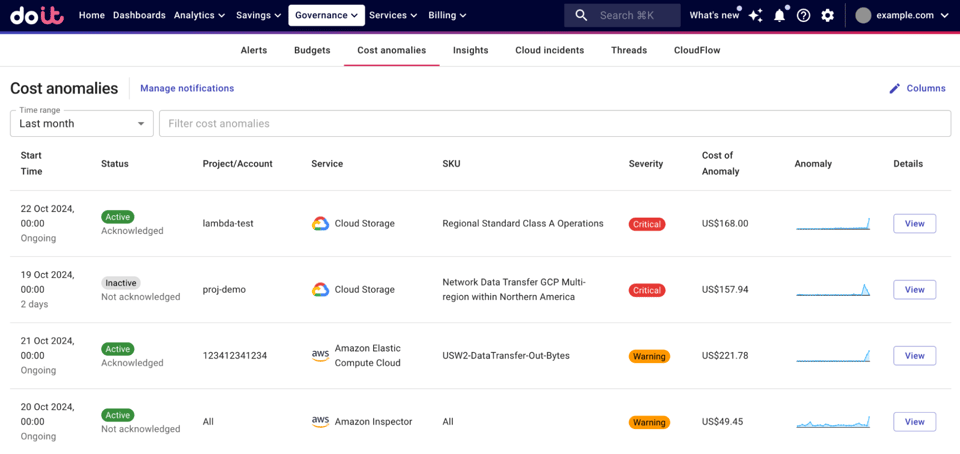 Quelle: DoiT Help Center
Quelle: DoiT Help Center
Definieren Sie, was "Anomalie" in Ihrer Umgebung bedeutet
Beginnen Sie mit klaren Zielen. Legen Sie fest, welche Anomalien wirklich relevant sind (Kosten, Zuverlässigkeit, Sicherheit), und definieren Sie Erfolgsmetriken wie Erkennungsgeschwindigkeit, False-Positive-Rate und Time-to-Triage.
Lieber wenige umsetzbare Alarme als viele
Gestalten Sie Alarme entlang Ihrer Workflows. Der Schweregrad sollte die Reaktion vorgeben: Wer wird wann benachrichtigt – und welche Schritte folgen?
Reaktionsmechanismen vorab planen
Erkennung ist nur der erste Schritt. Bauen Sie Reaktionsfähigkeiten auf, etwa:
- dynamische Schwellenwerte, die sich an Baselines anpassen.
- automatisierte Behebung für risikoarme Korrekturen.
- Skalierungs-Guardrails, die ausufernde Nutzung verhindern.
- Benachrichtigungs-Routing nach Schweregrad und Verantwortlichkeit.
Das System kontinuierlich nachjustieren
Cloud-Umgebungen entwickeln sich weiter – die Anomalieerkennung muss mitziehen. Trainieren Sie Modelle nach, verfeinern Sie Baselines, justieren Sie Schwellenwerte und beobachten Sie die Performance über die Zeit, um die Signalqualität hochzuhalten.
Eskalationspfade dokumentieren und wiederkehrende Schritte automatisieren
Erstellen Sie klare Playbooks für gängige Anomalietypen. Automatisieren Sie sichere, wiederholbare Reaktionen, damit Ihr Team Zeit für Analyse und Ursachenforschung hat – und nicht für manuelle Routinearbeit.
FAQ: Anomalieerkennung mit Machine Learning
Was ist Anomalieerkennung im Machine Learning?
Anomalieerkennung ist eine Methode, um Datenpunkte oder Muster zu identifizieren, die deutlich vom erwarteten Verhalten abweichen. Im Machine Learning kommen dabei oft Modelle zum Einsatz, die normales Verhalten aus historischen Mustern lernen und seltene oder ungewöhnliche Ereignisse markieren.
Was ist der Unterschied zwischen überwachter und unüberwachter Anomalieerkennung?
Die überwachte Erkennung lernt anhand gelabelter Beispiele für normales und anomales Verhalten. Die unüberwachte Erkennung benötigt keine Labels: Sie lernt normale Muster aus den Daten und meldet Ausreißer. In Cloud-Umgebungen ist der unüberwachte Ansatz verbreitet, weil gelabelte Anomalien selten vorliegen.
Warum ist Anomalieerkennung für das Cloud-Kostenmanagement wichtig?
Anomalieerkennung kann unerwartete Ausgabenveränderungen frühzeitig aufspüren – noch bevor die Monatsrechnung eintrifft. So können Teams Fehlkonfigurationen, unerwartete Nutzung oder Waste untersuchen und Budgetüberraschungen reduzieren.
Wie reduziert man False Positives bei der Anomalieerkennung?
Nutzen Sie kontextbewusste Baselines (Tageszeit, Wochentag, Saisonalität), justieren Sie Sensitivitätsschwellen und routen Sie Alarme nach Schweregrad und Verantwortlichkeit. Wer Alarme zusätzlich mit Ursachen-Kontext anreichert, reduziert das Rauschen weiter.
Cloud-Ausgaben mit DoiT planbarer machen
Anomaly Detection in DoiT Cloud Intelligence überwacht Ihre Cloud-Ausgaben und meldet ungewöhnliche Muster, damit Sie reagieren können, bevor Überraschungen Ihr Budget treffen.
Unser Ansatz verbindet Machine Learning mit Cloud-Expertise und liefert umsetzbare Alarme, die genau zu Ihrer Umgebung passen. Erfahren Sie, wie DoiT eine präzisere Anomalieerkennung ermöglicht – abgestimmt auf Ihre Nutzungsmuster und betrieblichen Anforderungen.
Wenn Sie die Plattform näher kennenlernen möchten, werfen Sie einen Blick auf die Produkt- und Preisoptionen von DoiT – damit Cloud-Ausgaben planbarer und kosteneffizienter werden.