No one likes surprises in their bill. Catch cost spikes early with Anomaly Detection to minimize their impact and the variability of your spend.

Imagine you receive your monthly cloud bill and see a whopping 30% increase from the previous month. How could this happen? You had no major product releases or significant changes to infrastructure in the last month. What gives?
With so many moving parts in the cloud, it can be difficult to monitor for and detect unanticipated cost spikes. Many companies are too limited on engineering resources to manually monitor for cost spikes — and then identify the source and scope of issues if they occur.
In this post, we’ll go over:
- How you can set up your own anomaly detection system
- How out-of-the-box solutions like Anomaly Detection in DoiT Cloud Intelligence™ help you autonomously monitor for cost spikes so you can focus on more important activities.
Why you need to set up anomaly monitoring
Unintended cost spikes come in many forms: a Terraform repository error, a crypto mining incident, servers spun up and forgotten about — the list is endless.
Cost anomalies crush confidence in your budgets and forecasts, impact your burn rate, and make it more difficult to understand your cloud spending patterns overall.
But despite the impact that this can have on your bottom line, many companies wait until their monthly bill arrives before reacting. If you can detect and address anomalies early on, you’ll nip the issue in the bud before it materially impacts your cloud bill, in turn making your cloud spend more predictable.
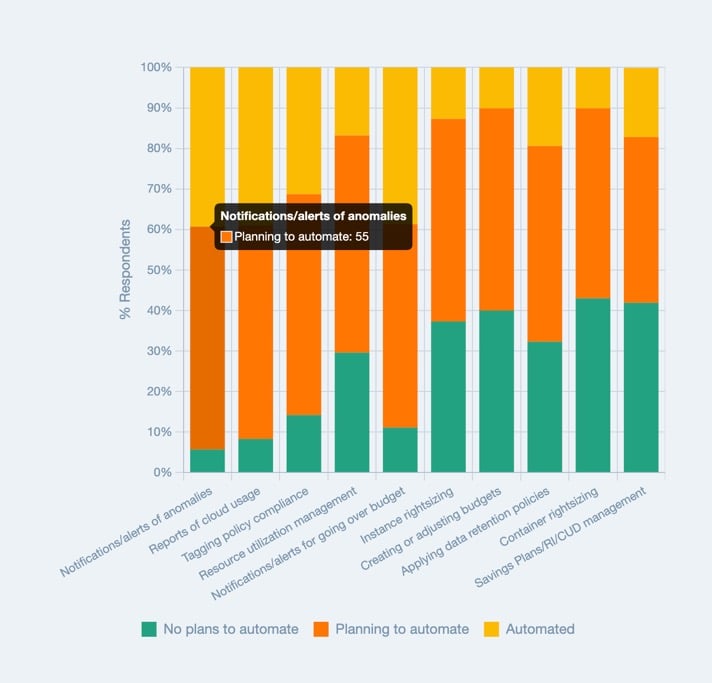
The challenge is automating the detection and alerting of cost spikes, because as mentioned above, many companies can’t afford to devote resources towards manually detecting anomalies. Many companies are still looking to automate anomaly alerting, according to the FinOps Foundation’s “State of FinOps 2023” survey.
How to build your own anomaly detection system
Before considering using a 3rd-party tool, you might ask yourself, "Hmmm, how much work can building and maintaining our own anomaly monitoring system be?".
The general work required to set up and maintain your own anomaly detection system can be broken down into four steps:
- Create a sample definition group
- Data sample preparation
- Begin analysis and set up feedback loop
- Set up a reporting strategy
Create a sample definition group
Before you begin any analysis, you’ll need to define what you’re monitoring for. This includes defining the scope of what you’re monitoring — whether you’re monitoring cost or usage, and at what granularity, whether SKU, service or a grouping of services. Then you’ll need to set the observation frequency (hourly, daily, weekly, monthly).
Finally, you’ll need to define the total period over which an evaluation is done. This determines the size of the data set. A shorter period will tend to emphasize subtle volatility at the risk of overestimating the significance of local maxima, while a longer period will provide more context and better capture normal fluctuations or seasonality, at the risk of being insufficiently sensitive.
Data sample preparation
Having defined the composition of your data points, a system has to be created to transform your cloud usage data into an appropriate structure, by aggregating the source data according to the scope and observation frequency that you selected.
Begin analysis and set up feedback loop
A combination of methods can be used to analyze your data points, including rules, statistics and modeling. The purpose of the evaluation is ultimately to quantify or stratify the probability that each sample is anomalous. In addition, the impact and duration of an anomaly can be determined. Determining the accuracy of the system is not trivial, since it is contingent on various considerations and preferences particular to each organization. Thus a feedback loop to inform continuous refinements is essential.
Set up a reporting strategy
Determine a reporting strategy that gets your attention when needed while avoiding alert fatigue. An overly sensitive system may not miss an anomaly, but if accompanied by a significant number of false positives, it will not achieve the desired results.
Anomaly Detection Reference Architectures
Google Cloud and AWS have both shared reference architectures for how you might build an anomaly detection system on their platforms. But even after you build it, the work isn’t finished. You’ll need to constantly maintain and tweak the system afterward.
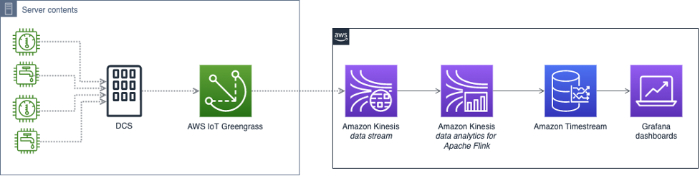
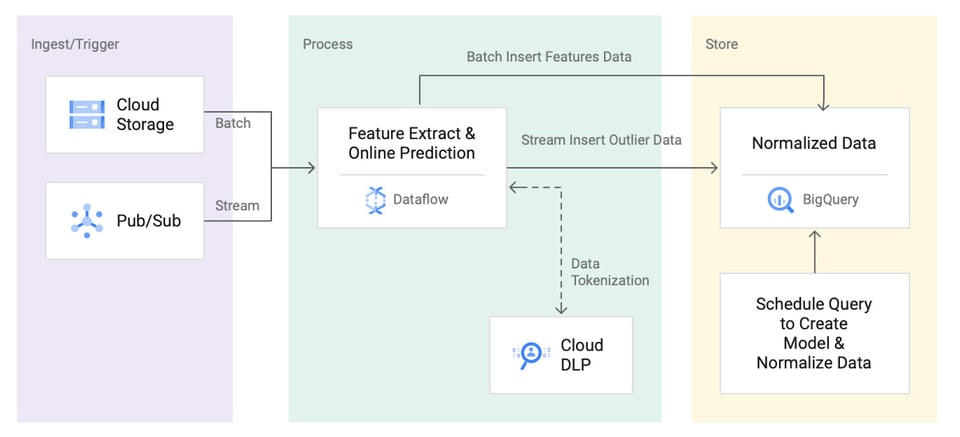
If you don't have the resources to build and maintain your own anomaly detection system, pre-built solutions like Anomaly Detection in DoiT Cloud Intelligence exist to help you automatically catch cost spikes without having to use your limited engineering resources.
Autonomously monitor for cloud cost spikes with DoiT Anomaly Detection
Anomaly Detection in DoiT Cloud Intelligence works by continuously monitoring your billing data and analyzing spend trends per-service and per-GCP Project/AWS Account.
From this analysis, it defines billing patterns — its own definition of what “normal behavior” is for your cloud usage.
You’re then alerted on any spend that doesn’t align with Anomaly Detection’s forecasted spending behavior.
The best part? You don’t have to configure or maintain anything.
Using a number of parameters, Anomaly Detection iteratively updates its thresholds as your spending behavior changes.
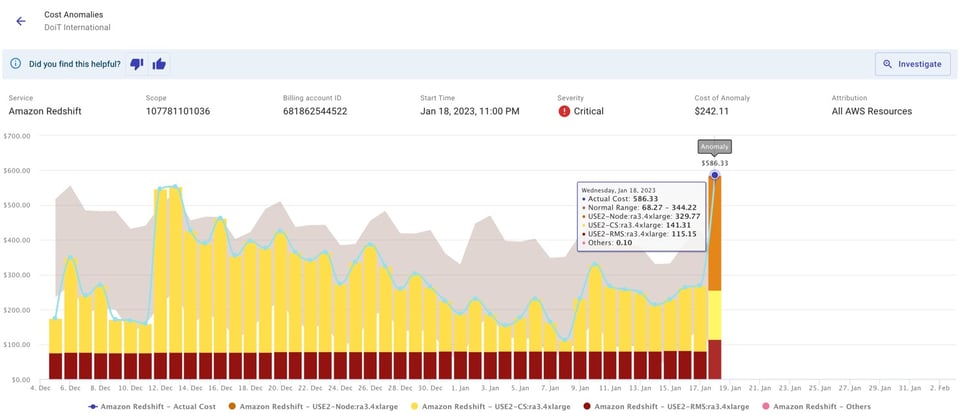
You can set up notifications to be sent via email or to a team Slack channel, as shown below.
This fosters internal conversations between you and your team that’ll increase a sense of ownership and awareness over your share of the cloud bill. For example, perhaps a cost spike was due to tests your team was running. You might not have been aware of these tests before, but due to this alert, now you are. Even if an alert isn’t actually an unanticipated spike, you can still learn something new about what your team is doing.
By automating the detection and alerting of anomalies, your team can instead focus on fixing the underlying issue(s) that caused them. You can click on “Investigate” in the alert, which will open a pre-configured report in DoiT Cloud Intelligence, making for a great starting point for a quick root-cause analysis and resolution.
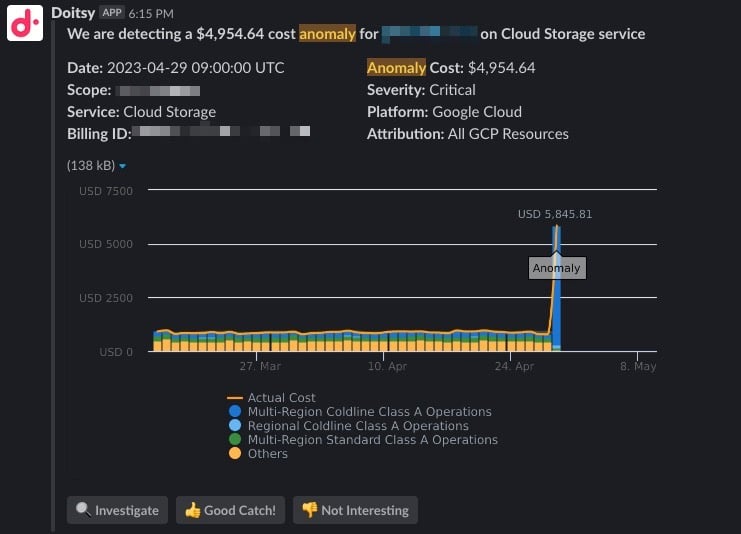
If you’re a DoiT customer, Anomaly Detection is available out-of-the-box in DoiT Cloud Intelligence. From the moment you become a customer, it starts analyzing your billing data and generating alerts once an abnormal cost spike is detected.
Not a DoiT customer? Take an interactive tour of Anomaly Detection or get in touch with us about leveraging Anomaly Detection and the rest of our products to better manage your cloud.