
Si estás intentando entender la detección de anomalías con machine learning, no eres el único. Quizá pasaste horas tratando de averiguar por qué se dispararon los costos de la nube el mes pasado, o te cuesta diferenciar un pico normal de tráfico de una posible amenaza de seguridad.
Los patrones inesperados en entornos cloud pueden mermar la eficiencia operativa y costar miles de dólares si no se atienden a tiempo. Las anomalías se manifiestan de varias formas: aumentos repentinos del gasto cloud, comportamiento irregular del sistema que afecta el rendimiento o actividad sospechosa que pone en riesgo datos sensibles.
La complejidad de la nube añade otra capa de dificultad. Con tantos servicios y dependencias, dar con la causa raíz puede ser complicado. Para mantener los sistemas confiables y reducir el riesgo, los equipos necesitan una forma de detectar y responder a los outliers de manera rápida y precisa.
Esta guía explica qué es la detección de anomalías, los principales tipos a vigilar, las técnicas y algoritmos de machine learning más habituales y buenas prácticas concretas para implementarla.
¿Qué es la detección de anomalías?
 Fuente: DoiT Anomaly Detection
Fuente: DoiT Anomaly Detection
En esencia, la detección de anomalías identifica patrones que no encajan con el comportamiento esperado. En entornos cloud funciona como un sistema inmunológico: monitorea de forma constante, aprende cómo luce lo "normal" y marca las desviaciones relevantes.
Las anomalías en la nube suelen aparecer en dos áreas:
- Anomalías operativas: cambios en el rendimiento, la confiabilidad o el comportamiento del sistema (picos de latencia, variaciones en la tasa de error, patrones de acceso inusuales).
- Anomalías de costos: aumentos inesperados del gasto que pueden o no estar ligados a cambios de tráfico o rendimiento.
Suelen solaparse (un pico de tráfico puede elevar tanto el gasto como la latencia), pero las anomalías de costos también pueden producirse sin síntomas operativos evidentes: una mala configuración de logs, un feature flag activado por error o un cambio en precios o uso.
Los sistemas modernos de detección de anomalías evitan depender solo de umbrales estáticos. En su lugar, recurren al machine learning para adaptarse a líneas base dinámicas que cambian por hora, día o temporada. Por ejemplo, el pico de tráfico de un ecommerce durante una venta anual es algo esperado, pero ese mismo pico un martes cualquiera podría indicar un ataque de bots o un despliegue defectuoso.
Tipos de anomalías a vigilar
En entornos cloud, las anomalías suelen agruparse en categorías de seguridad, operaciones y costos. Dentro de ellas, tienden a manifestarse en tres tipos de patrones:
Anomalías puntuales
Un único punto de datos drásticamente distinto del resto, como un pico de 10x en llamadas a la API o un aumento súbito de los costos de transferencia de datos. Pueden ser fáciles de detectar; lo difícil es determinar si son legítimas (un lanzamiento de producto) o sospechosas (uso indebido de credenciales).
Anomalías contextuales
Comportamientos que solo son anómalos en un contexto específico, como un uso alto de CPU normal en horas pico, pero preocupante a las 3 a.m. Requieren modelos que entiendan el tiempo, la estacionalidad y los ciclos de negocio.
Anomalías colectivas
Un conjunto de eventos que parecen normales por separado, pero resultan sospechosos al verlos en conjunto, como solicitudes coordinadas que revelan un patrón de DDoS o un crecimiento gradual de costos repartido entre varios servicios.
3 técnicas de detección de anomalías para detectar problemas a tiempo
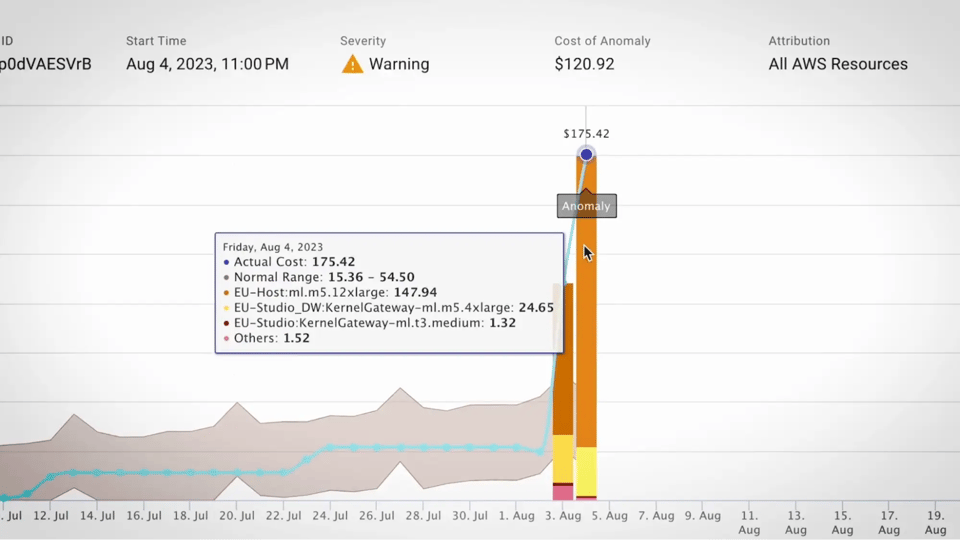 Fuente: Guía de herramientas FinOps
Fuente: Guía de herramientas FinOps
Cada técnica de detección de anomalías rinde mejor en distintos entornos. En la práctica, los equipos cloud eligen según la disponibilidad de datos, la velocidad con la que cambian los sistemas y los tipos de anomalías que necesitan capturar.
1) Detección supervisada
La detección supervisada entrena modelos con ejemplos etiquetados de comportamiento normal y anomalías conocidas. Puede ser muy precisa con problemas conocidos, pero se queda corta frente a eventos nuevos o poco frecuentes para los que no hay ejemplos.
2) Detección no supervisada
La detección no supervisada suele ser la opción por defecto en entornos cloud porque no requiere datos de anomalías etiquetados. Aprende cómo luce lo "normal" observando patrones a lo largo del tiempo y luego marca los eventos raros o significativamente distintos.
Este enfoque resulta especialmente útil cuando los sistemas son nuevos (sin historial etiquetado) o cambian constantemente. A medida que tu entorno evoluciona, los métodos no supervisados pueden seguir adaptándose a las nuevas líneas base.
3) Detección semisupervisada
La detección semisupervisada usa una pequeña cantidad de datos etiquetados para mejorar la precisión, pero conserva la flexibilidad necesaria para detectar problemas inéditos. Suele utilizarse cuando hay ejemplos confiables de lo "normal", pero pocas etiquetas de anomalías.
En la realidad, muchos sistemas de detección de anomalías en la nube se apoyan sobre todo en métodos no supervisados, porque esperar a recolectar y etiquetar suficientes anomalías no es viable. Los mejores sistemas empiezan a proteger desde el primer momento y siguen aprendiendo a medida que cambian los patrones.
Algoritmos comunes para la detección de anomalías
Los sistemas de detección de anomalías combinan enfoques estadísticos, de machine learning y de deep learning, cada uno adecuado para distintas formas de datos y necesidades operativas.
Métodos estadísticos y basados en reglas
Métodos como el análisis de Z-score, el rango intercuartílico (IQR) y el uso de umbrales simples funcionan bien con desviaciones claras en conjuntos de datos estables. Son rápidos y fáciles de implementar, lo que los hace útiles para la detección en tiempo real con distribuciones sencillas.
Métodos de machine learning
Para datos más complejos, los enfoques de ML aportan reconocimiento de patrones. Los métodos basados en árboles (incluidos los isolation forests) se usan con frecuencia, ya que las anomalías suelen ser raras y más fáciles de aislar que los puntos normales, lo que los vuelve eficientes para grandes conjuntos de datos.
Métodos de deep learning
Los enfoques de deep learning, en especial los autoencoders, destacan en datos de alta dimensión donde el comportamiento "normal" es complejo. Aprenden una representación comprimida de los patrones normales y marcan desviaciones cuando el error de reconstrucción es alto.
Métodos de pronóstico de series temporales
Cuando los datos dependen del tiempo, el pronóstico ayuda a definir rangos esperados. ARIMA y Prophet se usan a menudo para patrones estacionales y tendencias irregulares. Estos enfoques permiten detectar anomalías comparando los valores reales con líneas base predichas.
Aplicaciones reales de la detección de anomalías
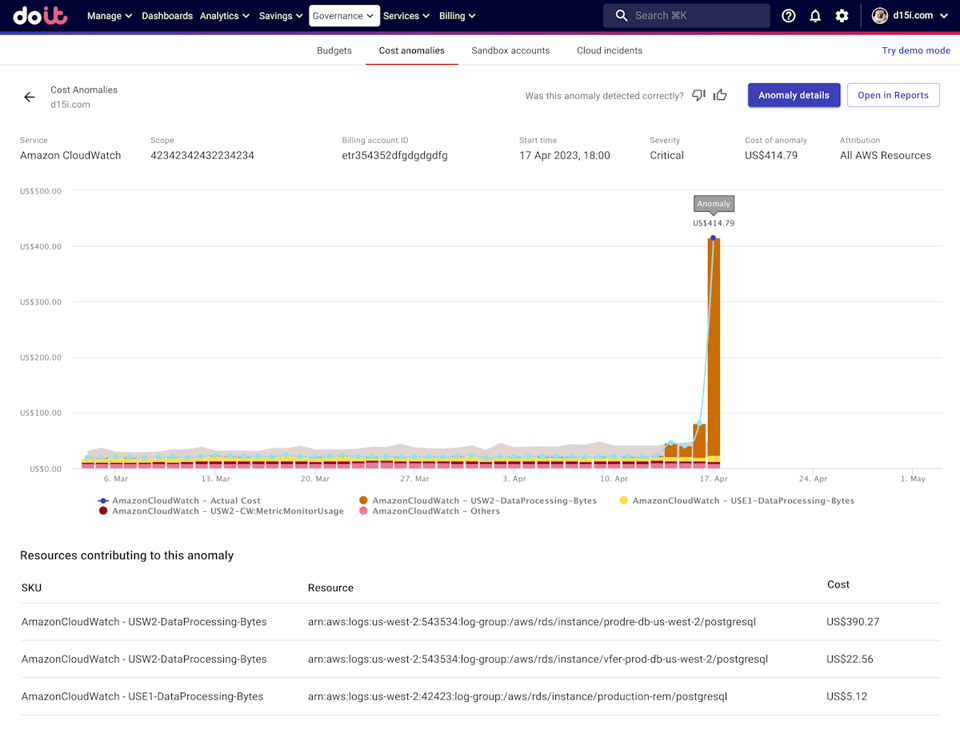 Fuente: Changelog de DoiT
Fuente: Changelog de DoiT
La detección de anomalías en entornos cloud va mucho más allá del monitoreo básico. Algunas aplicaciones habituales son:
Gestión de costos cloud
En la gestión de costos cloud, la detección de anomalías identifica patrones de gasto inusuales a tiempo, para que los equipos investiguen y corrijan antes de que llegue la factura de fin de mes. Por ejemplo, Moralis se asoció con DoiT y logró un ahorro del 10 % tras la implementación. Un enfoque proactivo también ayuda a reducir las sorpresas en la factura cloud.
Monitoreo de infraestructura
En el monitoreo de infraestructura, la detección de anomalías detecta desviaciones sutiles en métricas de rendimiento y ayuda a anticipar problemas antes de que se conviertan en caídas, pasando de operaciones reactivas a una prevención proactiva.
Monitoreo de seguridad
Los equipos de seguridad usan la detección de anomalías para descubrir patrones de acceso inusuales, comportamientos sospechosos y posibles brechas, sobre todo cuando los ataques intentan camuflarse con actividad de apariencia "normal".
Desafíos en la detección de anomalías
La detección de anomalías puede aportar mucho valor, pero las implementaciones reales se topan con obstáculos previsibles. Conocerlos de antemano ayuda a los equipos a evitar los errores más comunes.
El dilema de la calidad de los datos
Las líneas base confiables requieren suficientes datos limpios y relevantes. Los datos de baja calidad o incompletos dificultan distinguir la variación normal de las anomalías reales, lo que se traduce en alertas imprecisas.
El problema de los falsos positivos
Muchos sistemas tienen problemas con los falsos positivos. El exceso de alertas genera fatiga, los equipos empiezan a ignorar las notificaciones y aumenta el riesgo de pasar por alto problemas reales. Ajustar la sensibilidad y trabajar con líneas base con contexto es clave.
El factor costo
Procesar grandes volúmenes de datos (facturación, logs, métricas) y entrenar modelos puede demandar mucho cómputo. Para muchas organizaciones, hacerlo internamente añade overhead y complejidad operativa.
Complejidad del entorno cloud
Los patrones de uso en la nube cambian con frecuencia. Los servicios son interdependientes y el consumo de recursos varía según la demanda. Las líneas base deben adaptarse continuamente, sin volverse tan laxas que dejen pasar anomalías reales.
Integración y alineación con los flujos de trabajo
La detección solo importa si se integra con la forma en que trabajan los equipos. Las alertas deben llegar a los responsables correctos, incluir contexto accionable e integrarse con los flujos de incidentes y FinOps. Sin alineación ni capacitación, hasta los mejores sistemas de detección rinden por debajo de su potencial.
Buenas prácticas para implementar la detección de anomalías
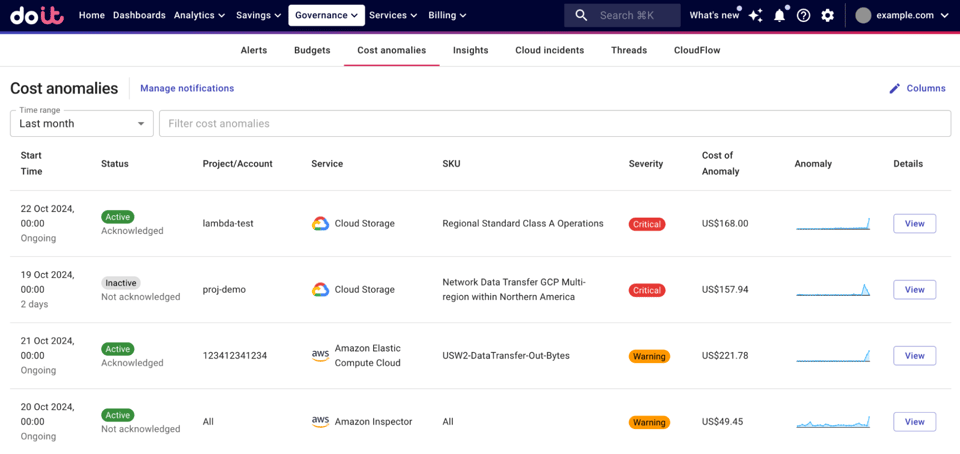 Fuente: Centro de ayuda de DoiT
Fuente: Centro de ayuda de DoiT
Define qué significa "anomalía" en tu entorno
Empieza con objetivos claros. Decide qué anomalías importan (costo, confiabilidad, seguridad) y define métricas de éxito como la velocidad de detección, la tasa de falsos positivos y el tiempo de triage.
Prioriza alertas accionables, no más alertas
Diseña las alertas en torno a los flujos de trabajo. La gravedad debe corresponderse con la respuesta: a quién se le notifica, con qué rapidez y qué pasos sigue después.
Planifica los mecanismos de respuesta con anticipación
La detección es solo el primer paso. Construye capacidades de respuesta como:
- Umbrales dinámicos que se adapten a las líneas base.
- Remediación automática para correcciones de bajo riesgo.
- Guardrails de escalado para evitar usos descontrolados.
- Enrutamiento de notificaciones según gravedad y responsabilidad.
Ajusta el sistema de forma continua
Los entornos cloud evolucionan; la detección de anomalías debe evolucionar con ellos. Reentrena los modelos, refina las líneas base, ajusta los umbrales y mide el rendimiento en el tiempo para mantener la calidad de la señal.
Documenta las rutas de escalamiento y automatiza las acciones repetibles
Crea playbooks claros para los tipos de anomalías más comunes. Automatiza respuestas seguras y repetibles para que el equipo dedique su tiempo a la investigación y a la causa raíz, no a tareas manuales.
FAQ: Detección de anomalías con machine learning
¿Qué es la detección de anomalías en machine learning?
La detección de anomalías es un método para identificar puntos de datos o patrones que se desvían significativamente del comportamiento esperado. En machine learning suele apoyarse en modelos que aprenden el comportamiento normal a partir de patrones históricos y marcan eventos raros o inusuales.
¿Cuál es la diferencia entre la detección supervisada y la no supervisada?
La detección supervisada aprende a partir de ejemplos etiquetados de comportamiento normal y anómalo. La no supervisada no requiere etiquetas: aprende los patrones normales a partir de los datos y marca los outliers. En entornos cloud, la no supervisada es habitual porque las anomalías etiquetadas son escasas.
¿Por qué es importante la detección de anomalías para la gestión de costos cloud?
Permite detectar cambios inesperados en el gasto a tiempo, antes de que llegue la factura mensual, para que los equipos investiguen malas configuraciones, usos inesperados o pérdida y reduzcan las sorpresas en el presupuesto.
¿Cómo se reducen los falsos positivos en la detección de anomalías?
Con líneas base con contexto (hora del día, día de la semana, estacionalidad), ajustando los umbrales de sensibilidad y enrutando las alertas según gravedad y responsabilidad. Acompañar las alertas con contexto de causa raíz también reduce el ruido.
Haz más predecible tu gasto cloud con DoiT
Anomaly Detection en DoiT Cloud Intelligence monitorea el gasto cloud y marca patrones inusuales para que puedas investigar antes de que las sorpresas afecten tu presupuesto.
Nuestro enfoque combina machine learning con experiencia cloud para entregar alertas accionables, adaptadas a tu entorno. Descubre cómo DoiT impulsa una detección de anomalías más precisa, alineada con tus patrones de uso y necesidades operativas.
Si quieres explorar la plataforma, revisa las opciones de producto y Precios de DoiT para hacer tu gasto cloud más predecible y eficiente.