
機械学習による異常検知をきちんと理解したい——そう考えているのはあなただけではありません。先月のクラウドコスト急増の原因を何時間もかけて追いかけた経験があるかもしれませんし、通常のトラフィック増加とセキュリティ上の脅威をどう見分けるかに頭を悩ませている方もいるでしょう。
クラウド環境で発生する想定外のパターンは、放置すれば運用効率を蝕み、数千ドル単位のコストにつながりかねません。異常の現れ方はさまざまです。クラウド支出の急増、パフォーマンスを損なう不規則なシステム挙動、機密データを脅かす不審なアクティビティなどが挙げられます。
クラウドの複雑さがさらに難易度を高めます。複数のサービスや依存関係が絡み合い、根本原因の特定を難しくしているからです。システムの信頼性を保ちリスクを抑えるには、外れ値を素早く正確に検知し、対応できる仕組みが欠かせません。
本ガイドでは、異常検知とは何か、注意すべき主な異常のタイプ、代表的な機械学習の手法とアルゴリズム、そして実装時のベストプラクティスを解説します。
異常検知とは
 出典:
出典:異常検知とは、想定される挙動から外れたパターンを見つけ出す仕組みです。クラウド環境では免疫システムのような役割を果たし、常時監視を続けながら「正常」を学習し、意味のある逸脱を検出します。
クラウドにおける異常は、主に2つの領域に現れます。
- 運用上の異常: パフォーマンス、信頼性、システム挙動の変化(レイテンシのスパイク、エラー率の変化、通常と異なるアクセスパターンなど)。
- コストの異常: トラフィックやパフォーマンスの変化と連動する場合もしない場合もある、想定外の支出増加。
両者はしばしば重なります(トラフィックの急増は支出とレイテンシの双方を押し上げます)が、コストの異常は明確な運用上の兆候を伴わずに発生することもあります。たとえばロギングの設定ミス、誤って有効化されたフィーチャーフラグ、料金体系や利用形態の変化などです。
近年の異常検知システムは、静的なしきい値のみに依存しません。代わりに機械学習を活用し、時間帯・曜日・季節によって変化する動的なベースラインに適応します。たとえばECプラットフォームの年次セール期間中のトラフィック急増は想定内ですが、何でもない平日に同じ急増が起これば、ボット攻撃やデプロイ不具合の兆候かもしれません。
注意すべき異常のタイプ
クラウド環境における異常は、一般的にセキュリティ、運用、コストの3カテゴリに分かれます。そのいずれにおいても、異常は次の3つのパターンで現れる傾向があります。
ポイント異常
他のデータと際立って異なる単一のデータポイントです。APIコール数が10倍に跳ね上がる、データ転送コストが急増するといったケースが該当します。発見そのものは比較的容易ですが、それが正当なもの(製品ローンチなど)か、不審なもの(認証情報の不正利用など)かを見極めるのが難しいところです。
コンテキスト異常
特定の文脈においてのみ異常となる挙動です。たとえばピーク時間帯のCPU高負荷は通常ですが、午前3時に同じ状況が発生すれば要警戒です。こうしたケースには、時間・季節性・ビジネスサイクルを理解できるモデルが求められます。
集合異常
個別に見れば正常でも、まとめて見ると不審に映る一連のイベントです。DDoS攻撃を示す協調的なリクエストや、複数サービスにまたがってじわじわ進行するコスト増加などが代表例です。
問題を早期に発見する3つの異常検知手法
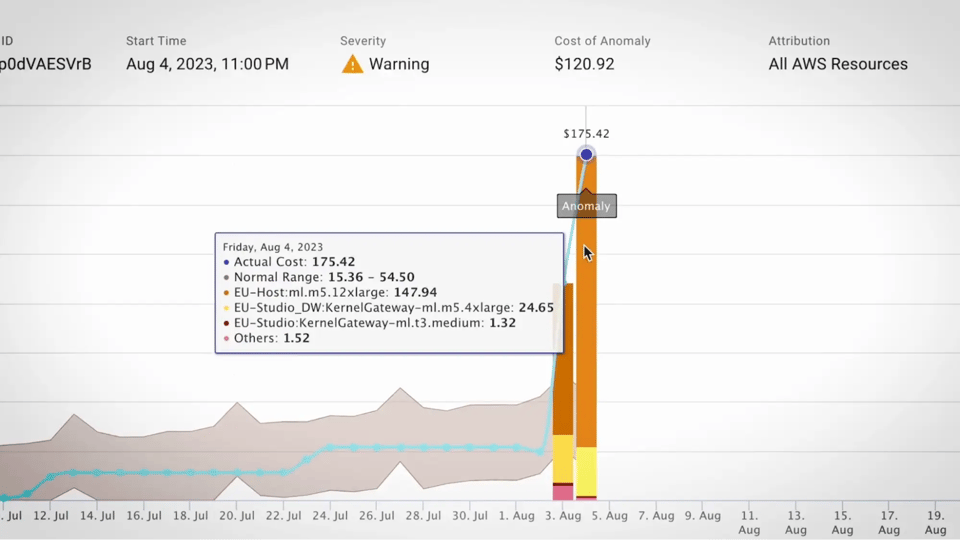 出典:
出典:異常検知の手法は、環境ごとに最適解が異なります。実務ではクラウドチームは、データの入手しやすさ、システム変化のスピード、捉えるべき異常の種類に応じて手法を選んでいます。
1)教師あり検知
教師あり検知は、正常な挙動と既知の異常のラベル付きサンプルを使ってモデルを学習させる手法です。既知の問題には高い精度を発揮しますが、サンプルがない新規の事象や稀な事象への対応は苦手です。
2)教師なし検知
教師なし検知は、ラベル付きの異常データを必要としないため、クラウド環境ではデフォルトの選択肢になることが多い手法です。時系列でパターンを観察して「正常」を学習し、稀あるいは大きく外れたイベントを検出します。
このアプローチは、システムが新しく(ラベル付きの履歴がない)絶えず変化している状況で特に有効です。環境が進化しても、教師なし手法は新しいベースラインに適応し続けられます。
3)半教師あり検知
半教師あり検知は、少量のラベル付きデータで精度を高めつつ、未知の問題も検出できる柔軟性を備えた手法です。「正常」の信頼できるサンプルはあるが、異常のラベルが限られているケースで重宝します。
実際には、十分な数の異常を集めてラベル付けするのを待つのは現実的ではないため、多くのクラウド異常検知システムは教師なし手法に大きく依存しています。優れたシステムは、すぐに保護を始め、パターンの変化に合わせて学習を続けます。
異常検知でよく使われるアルゴリズム
異常検知システムでは、統計的手法、機械学習、ディープラーニングなど多様なアプローチが使われます。それぞれデータの形状や運用上の要件によって向き不向きがあります。
統計的手法・ルールベース手法
Zスコア分析、四分位範囲(IQR)、シンプルなしきい値判定などは、安定したデータセットで明確な逸脱を捉えるのに向いています。高速かつ実装が容易なため、単純な分布のリアルタイム検知に役立ちます。
機械学習手法
より複雑なデータには、機械学習によるパターン認識が威力を発揮します。木構造ベースの手法(Isolation Forestなど)が広く使われているのは、異常は稀で正常データよりも分離しやすく、大規模データセットでも効率的に処理できるからです。
ディープラーニング手法
ディープラーニング、特にオートエンコーダは、「正常」の挙動が複雑な高次元データで真価を発揮します。正常パターンの圧縮表現を学習し、再構成誤差が大きいときに逸脱として検出します。
時系列予測手法
データが時間に依存する場合、予測によって想定される範囲を定義できます。ARIMAやProphetは、季節性パターンや不規則なトレンドの分析でよく使われます。これらは実測値と予測ベースラインを比較することで異常を検知します。
異常検知の実用的な活用事例
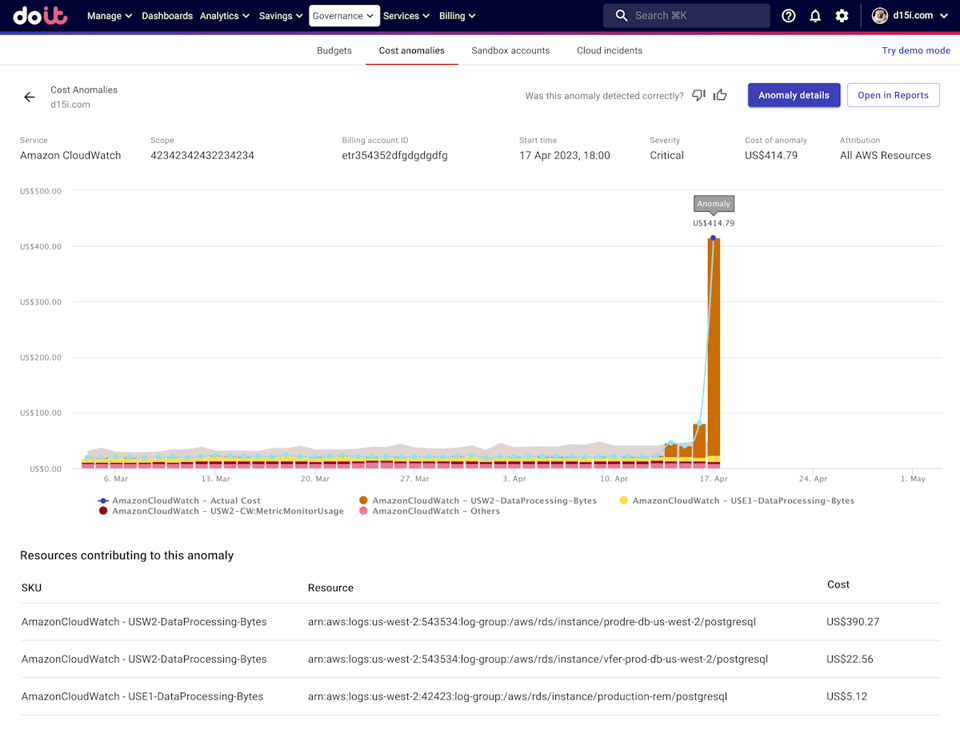 出典:
出典:クラウド環境における異常検知は、単なる監視を超えた価値をもたらします。代表的な活用例を紹介します。
クラウドコスト管理
クラウドコスト管理では、異常検知によって想定外の支出パターンを早期に発見でき、月末の請求書が届く前に調査・是正できます。たとえばMoralisはDoiTと連携し、導入後にコストを10%削減しました。先回りのアプローチはクラウド請求の想定外を減らすうえでも有効です。
インフラ監視
インフラ監視では、異常検知によってパフォーマンス指標の微妙な逸脱を捉え、障害化する前に予兆を察知できます。これにより、運用は事後対応型の消火活動から、予防型の取り組みへと変わります。
セキュリティ監視
セキュリティチームは、通常と異なるアクセスパターン、不審な挙動、潜在的な侵害を異常検知で可視化します。攻撃者が「いかにも正常そうな」アクティビティに紛れ込もうとするケースで特に役立ちます。
異常検知における課題
異常検知は大きな価値を生みますが、実運用では決まったハードルにぶつかります。事前に把握しておくことで、よくある失敗を避けやすくなります。
データ品質のジレンマ
信頼できるベースラインを作るには、十分にクリーンで関連性の高いデータが必要です。品質が低かったり欠損があったりするデータでは、通常の変動と真の異常を見分けにくくなり、不正確なアラートにつながります。
誤検知の問題
多くのシステムが誤検知に悩まされています。アラートが多すぎるとチームは疲弊し、通知を無視するようになり、本当に重要な問題を見落とすリスクが高まります。感度のチューニングと文脈を踏まえたベースライン設計が欠かせません。
コスト要因
大量のデータ(請求情報、ログ、メトリクス)の処理やモデルの学習には、相応の計算リソースが必要です。多くの組織にとって、これを社内で運用することは管理負荷と運用上の複雑さを増やす要因になります。
クラウド環境の複雑さ
クラウドの利用パターンは頻繁に変化します。サービスは互いに依存し、リソース消費は需要に応じて変動します。ベースラインは継続的に適応する必要がある一方で、緩めすぎて本当の異常を見逃さないようバランスが求められます。
統合とワークフローの整合
検知は、チームの働き方に組み込まれてはじめて意味を持ちます。アラートは適切な担当者に届き、対応に役立つ文脈情報を含み、インシデント対応やFinOpsのワークフローに統合されている必要があります。整合とトレーニングがなければ、優れた検知システムも本来の力を発揮できません。
異常検知を実装する際のベストプラクティス
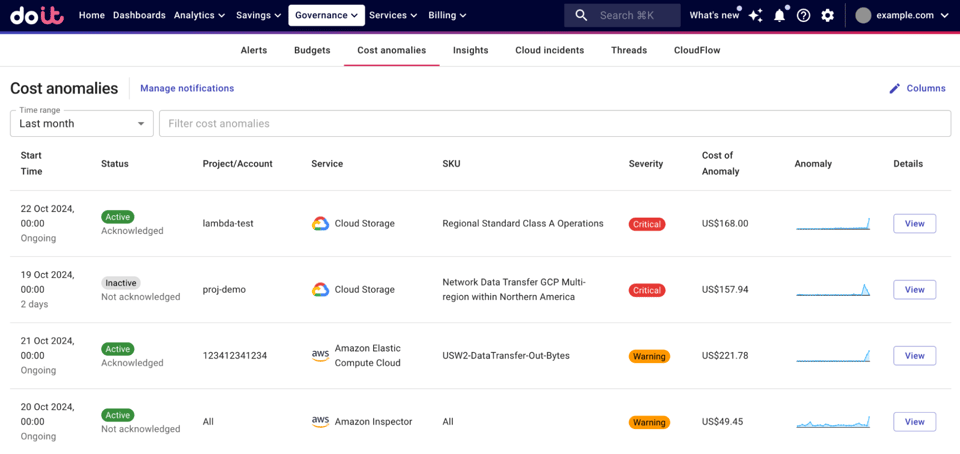 出典:
出典:自社環境における「異常」の定義を明確にする
まずは目的を明確にしましょう。重視する異常(コスト、信頼性、セキュリティ)を決め、検知スピード、誤検知率、トリアージ完了までの時間など、成功指標を定義します。
アラート数より、対応につながるアラートを優先する
アラートはワークフローを軸に設計します。重大度は対応に直結させ、誰に・どれだけ早く通知し・次に何をするかを明確にしましょう。
対応の仕組みを事前に設計する
検知は最初の一歩にすぎません。次のような対応の仕組みを整えましょう。
- ベースラインに追従する動的しきい値。
- 低リスクの修正に対する自動是正。
- 暴走的な利用を防ぐスケーリングのガードレール。
- 重大度と担当者に応じた通知ルーティング。
システムを継続的にチューニングする
クラウド環境は進化します。異常検知も同じく進化させなければなりません。モデルを再学習させ、ベースラインを精緻化し、しきい値を調整し、長期的にパフォーマンスを追跡してシグナルの質を保ちましょう。
エスカレーション経路を文書化し、繰り返し可能なアクションを自動化する
よくある異常タイプごとに明確なプレイブックを用意しましょう。安全で繰り返せる対応を自動化することで、チームは手作業ではなく調査や根本原因分析に時間を使えるようになります。
FAQ:機械学習による異常検知
機械学習における異常検知とは何ですか?
異常検知とは、想定される挙動から大きく逸脱したデータポイントやパターンを特定する手法です。機械学習では、過去のパターンから正常な挙動を学習し、稀あるいは通常と異なるイベントを検出するモデルがよく用いられます。
教師あり異常検知と教師なし異常検知の違いは何ですか?
教師あり検知は、正常および異常な挙動のラベル付きサンプルから学習します。教師なし検知はラベルを必要とせず、データから正常パターンを学習して外れ値を検出します。クラウド環境では異常のラベルが乏しいため、教師なし検知が一般的です。
クラウドコスト管理において異常検知が重要なのはなぜですか?
異常検知を使えば、月次の請求書が届く前に想定外の支出変化を早期にキャッチできます。設定ミスや想定外の利用、無駄を調査でき、予算面のサプライズを減らすのに役立ちます。
異常検知の誤検知を減らすにはどうすればよいですか?
文脈を踏まえたベースライン(時間帯、曜日、季節性)を活用し、感度のしきい値を調整し、重大度と担当者に応じてアラートをルーティングしましょう。アラートに根本原因の文脈を添えることでもノイズを減らせます。
DoiTでクラウド支出をより予測可能に
DoiT Cloud IntelligenceのAnomaly Detectionは、クラウド支出を継続的にモニタリングし、通常と異なるパターンを検出します。予算に影響が出る前に調査に着手できます。
機械学習とクラウドの専門知見を組み合わせ、お客様の環境に最適化された実行可能なアラートをお届けします。利用パターンや運用ニーズに沿ったより精緻な異常検知をDoiTがどう支援するかをご覧ください。
プラットフォームをさらに知りたい方は、DoiTの製品・料金プランをご確認のうえ、クラウド支出をより予測可能でコスト効率の高いものへと進化させましょう。