












When you run data pipelines in Google Cloud Platform (GCP), you probably use Dataflow. Dataflow is a runner for Apache Beam workloads. When you bring a working data pipeline to production, it is time to make it more cost-efficient. Finding the optimal settings for your pipelines is challenging because there are so many options and parameters, and in this blog post, I’ll help you find that.

Make use of the Streaming Engine
One of the easiest ways to reduce costs is to enable the Streaming Engine. If you do not use the Streaming Engine, the Autoscaler uses the persistence disk as an indicator for the number of workers. Disks will never be removed from a running job. A worker should have at least one persistent disk, and the number of attached disks must be equal among the different workers. So Dataflow can only reduce the number of workers by 50% to ensure equal distribution of disks across workers. When the Streaming Engine is enabled, much work like the shuffle and groupByKey steps will be outsourced to the Streaming Engine service, and Dataflow autoscaling does not rely on the attached disks. For this reason, you could also reduce your disk size to 30GB.
The streaming engine supports Java (SDK => 2.11.0) and Python (SDK => 2.21.0) pipelines.
Java: - enableStreamingEngine Python: enabled by default. Go: Not supported yet.
The number of max workers
Horizontal Autoscaling previously called Autoscaling, automatically selects the number of workers needed for the job. The default maximum number of workers is 1000 for batch jobs and 100 for streaming jobs.
By limiting the maximum amount of workers, you can reduce costs. But when you process a large volume of data with just one single worker, this can take ages before your data is processed. Based on your business requirements and the spikiness of your data, you can select the right amount of workers. Based on my experience, I suggest you choose ten more workers than your job needs 80% of the time. This way, you have a buffer in your worker pool for dealing with the spikes. When your spikes are bigger, and the backlog in Dataflow does not decrease fast enough, you need to select more workers.
When you do not use the Streaming Engine, keep in mind that you deploy a fixed pool of persistent disks equal to the maximum number of workers. You can set the max amount of workers with the following flags:
Java: - maxNumWorkers Python: - max_num_workers Go: - max_num_workers
Parallelization
Dataflow is a managed service developed by Google that can be used for distributed data processing on a large scale. The main cost of Dataflow is the needed computing resources which we need to use the available resources as efficiently as we can. Several pipeline parameters allow us to fine-tune parallelization on the right resources. Dataflow is designed to process a massive amount of data a lot of work will be done in parallel. With Dataflow, you can improve the parallelization in 2 ways: You can add more workers or define more threads per worker. This blog post will refer to parallelization as threads per worker.
Parallelization in a single worker helps you reduce costs because the same worker can process more elements. When you can process more elements in a single worker, Dataflow needs fewer workers for your job.
Machine type and concurrent threads
Most of the Dataflow cost is dedicated to computing resources. Because of that, it is essential to select suitable machine types for the job. Google Cloud Platform offers a wide variety of machine types.
For memory-intensive workloads, choosing the N1 is a bit cheaper than the newer N2.
But when your jobs use a lot of CPU, the more commonly used, newer N2 series is a better choice. In the N2 series, there are three different types to choose from N2-standard, N2 high-mem and the N2 high-CPU. The standard machine type gives you 4GB of Memory per vCPU. The high-mem provides you 8GB of memory per vCPU, and last, but not least the high-CPU provides you 1GB of memory per vCPU. Pricing can be found here.
Dataflow can run your workload in parallel. When running Dataflow in Streaming mode, Dataflow runs one DoFn per thread. Important to know that the parallelization in the python SDK works differently than the Java and Go SDK. Python runs one process and by default, 12 threads per vCPU, where Go and Java run one process and 300 threads per VM. The number of default threads in the Python SDK depends on the number of vCPUs in the chosen machine type. For example, when choosing the n2-standard-2 You have 2 vCPUs and (2x12) 24 threads. When selecting the n2-standard-8 You have 8 vCPUs and (8x12) 96 threads by default.
Dataflow allows you to configure the number of threads per vCPU or VM depending on your SDK. These are called Worker harness threads.
Java: - numberOfWorkerHarnessThreads Python: - number_of_worker_harness_threads
Depending on your needs and, workload you can change the level of parallelism. Because multiple threads run in the same memory space, you should lower the number of threads for jobs that are memory intensive. When your workload isn’t that intensive, you can raise the number of threads so more work will do more work in parallel. The greater the parallelism is, the more elements can be handled by a single worker. When you are trying to do too much in parallel, you can see a variety of issues the most common is Out Of Memory, and Dataflow will retry this work. And keep in mind that if calling 3rd party resources like API's that they can handle the volume of calls
Fusion optimization
When you submit your code to the Dataflow runner, the first step Dataflow does after compiling the code is to create an execution graph based on your code. You can see this graph in the Google Cloud Console. For more information, follow this link. After your graph is created and validated by the Dataflow runner, the Dataflow Service may modify your graph to perform optimizations. One of the optimizations is combining (fusing) separate steps to larger operations so the service doesn’t need to materialize the data in between every step. This will make processing faster as data can be processed with multiple operations in memory but it also forces the execution of all combined steps on the machine it started. While Fusion optimization is an important part of Dataflow’s power, it can also create bottlenecks in your pipeline. Because Fusion optimization is based on the graph created by the code before data flows through the pipeline, Dataflow cannot detect the following use cases that limit parallelization.
Figure 1: Optimized Execution Graph for Wordcount Example, This Java WordCount example
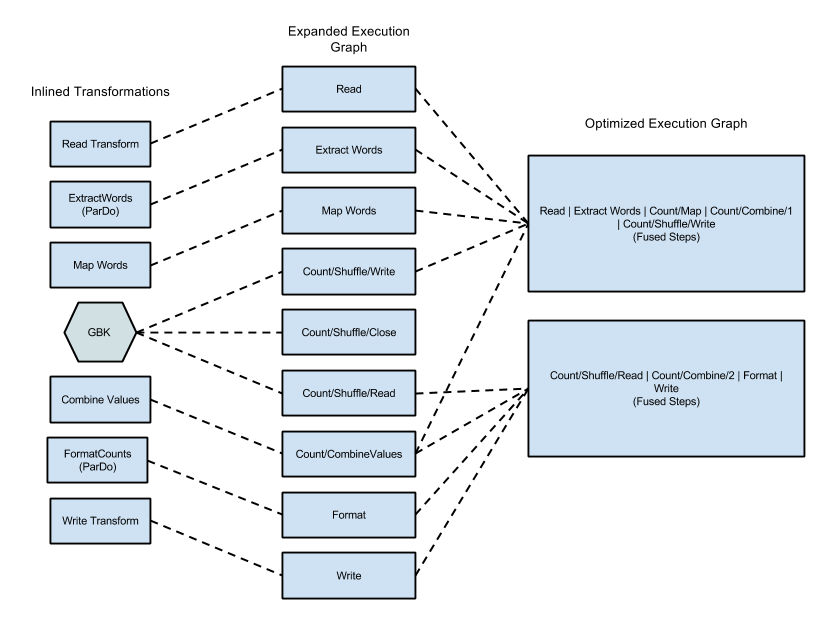
the Dataflow documentation shows how the graph will be when you run the example with the Dataflow runner.
High Fanout
When one of your ParDos outputs much more elements than it got as the input, you should consider reshuffling your data. An example is when you process a file as input and the output is individual lines. After this ParDo, Dataflow has many more items to process on the same worker than expected. Dataflow then uses the expected number of input items to determine how many instances the fusion step needs. After breaking the fusion, Dataflow can rebalance the workload and process more items in parallel.
Data not well balanced across machines
If you have a job that consumes files as input and those files vary in size, then it is very likely that the volume of data running through your pipeline is out of balance. Some workers have a lot more to process than other workers. If you do not reshuffle your data, some machines will be idle while others will run at full capacity.
You can break the fusion in three ways:
- GroupByKey (Dataflow never fuses aggregation steps). Dataflow never fuses aggregation steps.
- Add your intermediate PCollection as side input. A Side input is always materialized because of that it doesn’t make sense to fuse those steps.
- Add a reshuffle step (Reshuffle is supported by Dataflow even though it is marked deprecated in the Apache Beam documentation). With Reshuffle the data will be redistributed among the different workers
Preemptible workers with FlexRS
To reduce cost for batch jobs, you can start using the FlexRS feature, though this is only suitable for non-time-critical workloads like daily or monthly tasks. FlexRS uses a combination of regular VM instances and preemptible VM instances. Dataflow FlexRS tries to prevent process loss when preemptible machines stop working. You can only use FlexRS when using the Dataflow Shuffle service.
When you want to enable FlexRS, you can choose between cost or speed optimization.
Java: - flexRSGoal=COST_OPTIMIZED Python: - flexrs_goal=COST_OPTIMIZED Go: - flexrs_goal=COST_OPTIMIZED
Note that as FlexRS is built on a choice of inexpensive instances when auto-scaling, you cannot set the auto-scaling algorithm to NONE when using FlexRS
BigQuery write storage API
In 2021, Google launched a new BigQuery API for batch and streaming workloads. This new endpoint ensures that the data added is idempotent in the same stream. The default throughput quota of the new write API is three times higher than the legacy API.
Most important is that the cost for the new API is 50% lower per GB compared with the legacy API. When your pipeline streams a lot of data to BigQuery, this can be a huge cost-saver. For the exact number, see the pricing page.
Unfortunately, at the moment of writing (January 2023), only the Java SDK supports the new write storage API.
You only need a small code change in Java to use the Storage Write API. Add Method.STORAGE_WRITE_API as a parameter to .withMethod() as follows.
WriteResult writeResult = rows.apply("Save Rows to BigQuery",
BigQueryIO.writeTableRows()
.to(options.getFullyQualifiedTableName())
.withWriteDisposition(WriteDisposition.WRITE_APPEND)
.withCreateDisposition(CreateDisposition.CREATE_NEVER)
.withMethod(Method.STORAGE_WRITE_API)
);
More information about the implementation can be found in the BigQueryIO documentation.
Summary
Dataflow cost optimization depends on a lot of different factors. You need to make a tradeoff between performance/velocity and cost for most of the recommendations.
Making use of the newest BigQuery API saves you a lot of costs as well. Other optimization can be done in the code by following the Dataflow/Apache Beam best practices. You can make use of common pipeline patterns. My personal favorite is the BigQuery dead-letter pattern. This is a great post to learn more about the Streaming engine.



