Presenting a new tool to measure throughput and latency across regions
The cloud sometimes seems like an extradimensional space, where any amount of data can flow in near-zero time. But the fundamental limits of space-time and the TCP protocol mean that simple physical distance makes a big difference. If you are having trouble getting massive amounts of data off one cloud into another, you need to put the destination as close as possible to the source.
In this article, we look at throughput and latency, two very different but correlated networking metrics for measuring dataflows, and present a new tool for measuring them across regions.
Latency impacts throughput
Latency, the route trip time, measures the milliseconds from the moment a request is sent until a response is received. Throughput means the number of bits per second that are transmitted.
You can have high throughput without low latency and vice versa. Like the MIssissippi River, data can flow in very large quantities per second and take a long time to get from point A to point B or move like fast-flowing rapids — only a few bytes might flow each second — yet move to their destination lightning-quick.
Still, in practice, latency directly affects throughput in the most common protocol, TCP. This is a connection-oriented protocol which requires acknowledgements for each packet; it re-sends where necessary. The TCP send buffer contains all data that has been sent but not yet acknowledged by the remote host; this allows retransmission of unacknowledged packets. Yet the buffer has a limited size, and so transmission will pause if enough messages remain unacknowledged within this window. For example, with round-trip time of 80 ms and typical TCP window of 64 KByte, maximum throughput is only up to 66 Mbit/sec ( see this calculator). This is far less than the gigabytes per second that you see advertised in the cloud.
That last metric is bandwidth, the maximum number of bits per second that you might get, given the channel that you paid for. Throughput can be far lower than bandwidth when bottlenecks like the TCP window impose limits.
Maximizing throughput when you have high latency
If you want masses of data to flow through a high-latency TCP channel, you will need to do something different.
- Send multiple streams at once, up to the bandwidth limit. But this is often limited by the way that a given API expects to be used, for example if it expects to send massive data within a single response or imposes rate-limits on invocations.
- Use a connection-less protocol like UDP and handle retransmission yourself. This is only possible when you have control over the whole stack. In particular, most versions of HTTP(S), which is commonly used for APIs today, run over TCP. (Note that some protocols over UDP, like the recent HTTP 3/QUIC, still provide retransmission, and so have the same basic problem of transmission buffers.)
- Change TCP parameters such as window size on the operating-system level. However, in the cloud you often work with serverless services that do not give you such control.
- That means the only variable left is minimizing distance. This is particularly important when you transition between clouds because a given cloud provider in most cases has private networks connecting the regions.
In the cloud, the network layer is usually reliable and provides high bandwidth – because the major cloud providers can invest in the best. Traffic inside a given cloud is extremely fast, and, even between cloud providers, it is still far better than in homes, offices and even on-premise data centers.
The speed of light is finite
Apart from congestion on the public internet, distance and the speed of light are the biggest limits on latency. The farthest you can send is between two antipodal points – where the round-trip is the full circumference of the earth – is 130 light-milliseconds, and other cross-continental routes are a good fraction of that. Together with delays from processing en-route, even with the highly optimized routers in use today, this means that sending data thousands of kilometers and back will take a significant number of milliseconds. And that latency fundamentally limits the throughput of TCP transmission.
A note on cost
This article is mostly about throughput and latency, but don’t forget the other metric: cost. Clouds charge for data transfer, in decreasing order of cost: Data egress out of their service, between regions in their cloud and between zones.
Throughput measurement in the cloud: A new tool
I wrote an open-source tool to measure throughput and latency across regions, both within each cloud and between the clouds. It supports AWS and Google Cloud Platform.
As far as I know, this is one of the first to do this. Existing metrics focus on latency rather than throughput, and most focus on the network within a cloud, rather than across clouds.
How it works
Throughput and latency
The Intercloud Latency tool works by launching small virtual machines in various regions. It then runs a test with iperf, a throughput-measurement tool, and with ping, to measure latency.
Run performance_test.py --help for documentation.
Inter-region tests
Tests are run from one region to another. By default, it does not do intra-region tests, because metrics inside a region are too good to be comparable to inter-region tests.
Including all the GCP regions and all the default-enabled AWS regions, that is 46 regions and n * (n - 1) (namely, 2070) test pairs.
Distances
The distances are based on data center locations gathered from various open sources. Though the cloud providers don’t publicize the exact locations, they are not a secret.
Yet the locations should not be taken as exact. Each region is spread across multiple (availability) zones, which in some cases are separated from each other by tens of kilometers, for robustness. (See Wikileaks map here, which clearly illustrates that.) City-center coordinates are used as an approximation. Yet given the speeds measured here, statistics that rely on approximate region location are precise enough that any error is swallowed inside other variations of network behavior.
Options
If you don’t want to test all regions at once, there are options to let you limit the choice of region-pairs.
You can designate specific regions-pairs. You can also have the system choose region-pairs, restricting the choice to:
- A single cloud,
- Specific inter-cloud pairs (e.g. only GCP-to-AWS or GCP-to-GCP),
- A specific range inter-region distances: The minimum and maximum distance between any two regions to be tested together.
- And you can limit the maximum number of regions selected.
Though testing by default is in parallel for speed and cost control, you can configure the tests to run in sequential batches.
The virtual machine (instance) types used are small and comparable between AWS and GCP. You can also choose the machine types. It’s important to remember that this is not a test of achieving low latency and high throughput — it is a comparison of such metrics across distances, and so all that matters is that tests are comparable. However, because even the smallest instances are allocated bandwidth in the gigabits-per-second, and because this test is limited by the network and by TCP stack definitions, not CPU, RAM or disk, using larger instances does not make much difference.
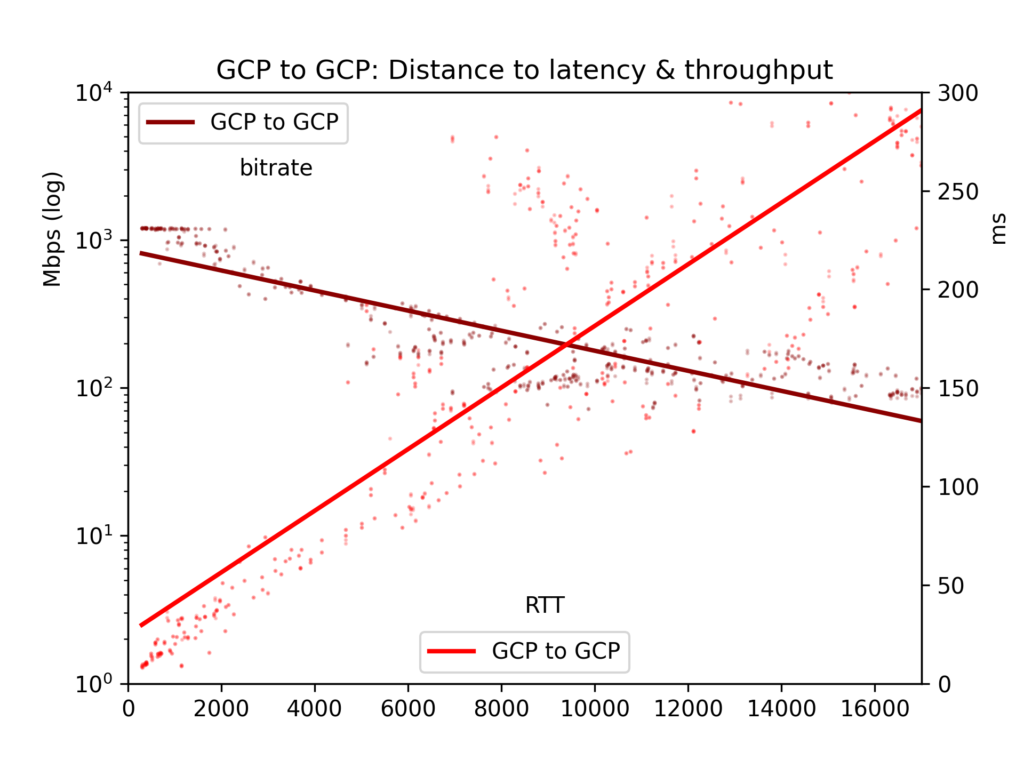
Note that the one exception is that in GCP regions that are very close to each other, where throughput hits ceilings based on resources available. See the charts. However, this does not affect the conclusions, summarized below.
Cost
Launching an instance in every region does not cost much: These small instances cost 0.5 - 2 cents per hour. Because of parallelization, the test suite runs quickly and instance charges are under $2 for a full test. Data volume is 10 MB per test, and egress charges are the majority of the expense, up to $20 for a test that covers all regions.
Output
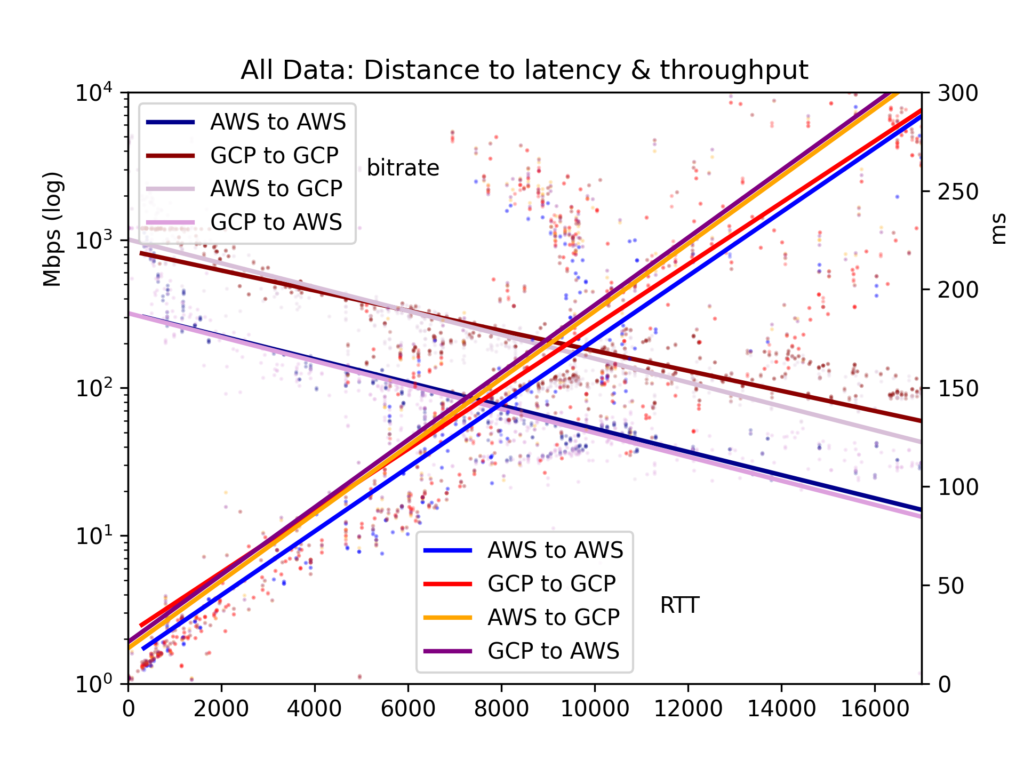
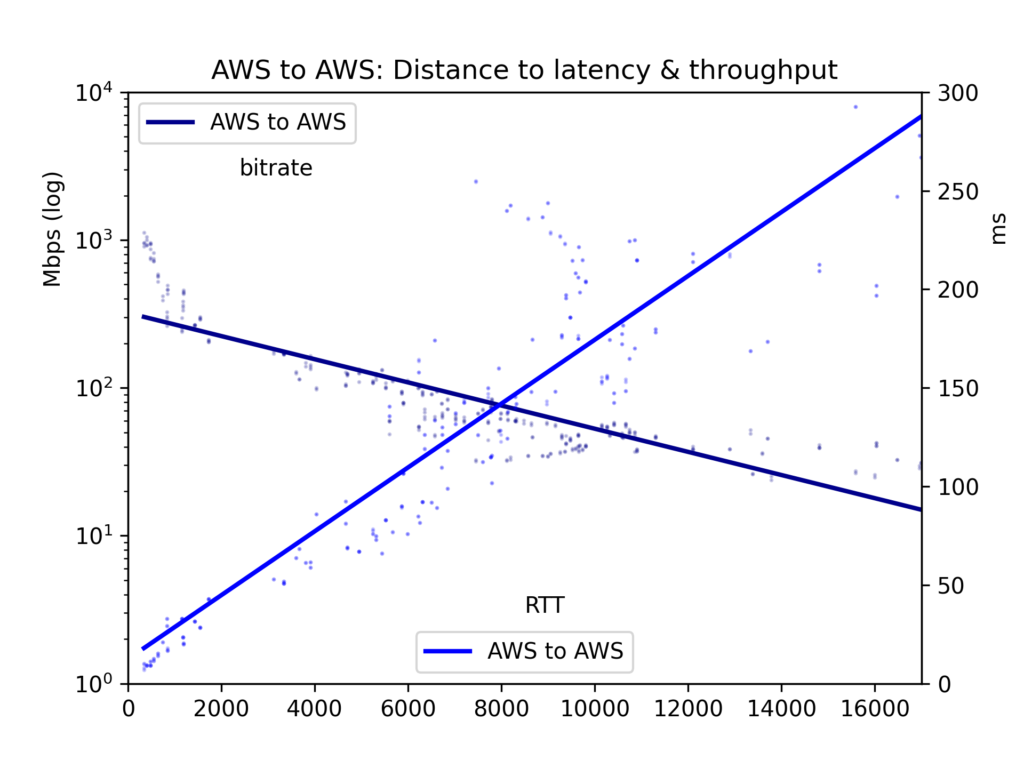
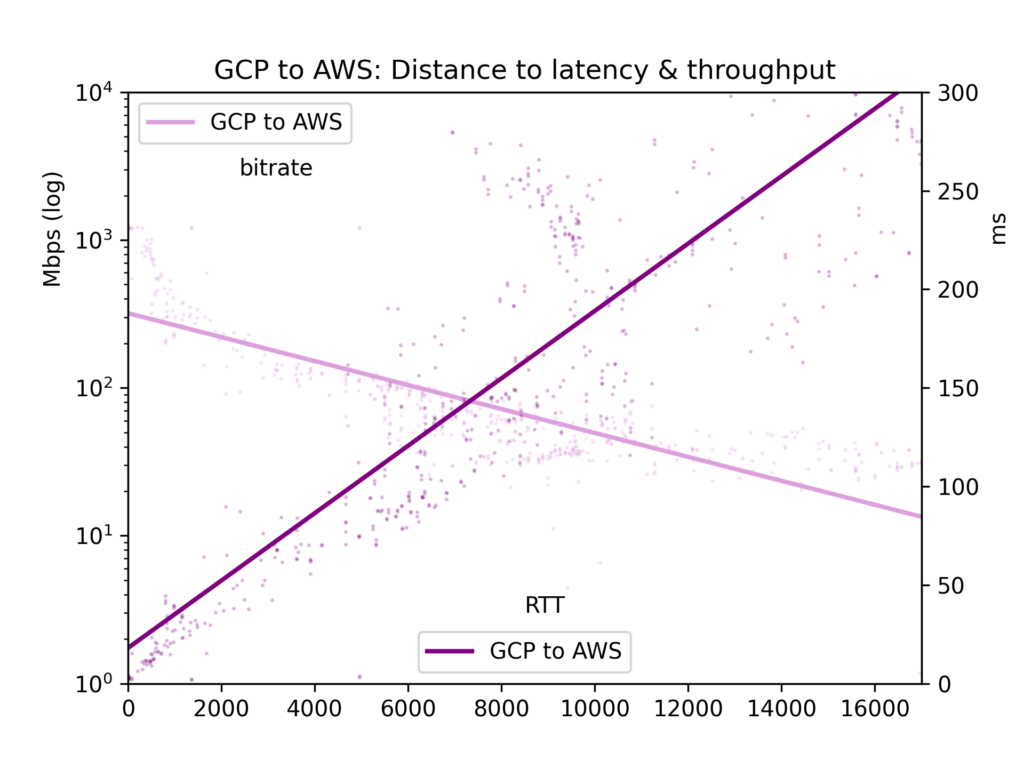
Average round-trip time and bitrate are gathered in a CSV file and presented in five charts: all cloud-pairs, GCP-to-GCP, GCP-to-AWS, AWS-to-GCP and AWS-to-AWS.
Results from the throughput testing
Results are noisy. Across the public internet, congestion and BGP rebalancing can greatly affect both latency and throughput. But the results give some clear results. Latency and throughput are indeed better within a cloud than cross clouds, though perhaps not as different as you would think.
For our primary focus here, the effects of distance, we see that latency is linear with distance (correlation r=0.92). So the speed of light and some minimal router processing take time in a relatively straightforward way. Throughput is much more spiky, as TCP buffers and other bottlenecks slow down transmission less linearly, yet throughput is clearly log-proportional to distance (r=-0.7).
See the charts below. The main result is: Though in principle a massive river of data can slowly flow a long distance, in practice TCP buffers mean that latency, and therefore distance, impede throughput. If you want to offload massive data between clouds, look up the physical locations and find the nearest region.