













In my previous article, I showed you how to run containers using Cloud Composer (managed Apache Airflow for the uninitiated). Since that article was published, Google has pushed out a preview build of Composer that uses Airflow 2.0, a big upgrade. It fixes many issues, while also making development more like coding in Python.
Composer is currently supporting Airflow 2.0.1. Hence, please note that this article has been written with this specific version in mind.
There haven’t been any groundbreaking changes in the Airflow 2.0 series code that I have used in this article. But as we learned with Airflow 1.0, this can change very fast with new versions that will be released in the near future. So please keep this fact in mind if you are pulling this code a year or so from now while using the latest and greatest version.
This is a two-section article. The first will cover some basic Airflow 1.0 vs 2.0 differences from the code perspective, namely around what I am using in my code for the second part. The second section will show how to run containers on a newly created GKE cluster, after which we’ll revisit my previous article’s codebase that has been updated for Airflow 2.0.
Writing Python Files vs “Writing in Airflow”
Some of the biggest Airflow 2.0 changes include allowing you to write a DAG in an easier manner, which makes the code more readable. These changes are being appreciated by developers who are not Airflow experts.
For example, you need to do something like this to define a DAG in Airflow 2.0:
@dag(schedule_interval=None, default_args=default_args, catchup=False) def composer_cluster_gke_pod_dag(): ...
Compare this to the Airflow 1.0 definition:
with models.DAG(JOB_NAME, default_args=default_args, schedule_interval=None, catchup=False) as dag: ...
Python developers can now easily read this code, making the DAG a function that can be easily wrapped by testing frameworks. There is also the simplicity of passing data between tasks. With the old Airflow 1.0, you would have to use XComs and perform some complex workarounds to get the output of a bash script task into another. Take a look at this code:
# operator that echoes out a message and pushes it to xcom
bash_task = BashOperator(
task_id="bash_task",
xcom_push=True,
bash_command='echo "Hello World"'
)
# inside another PythonOperator where provide_context=True
def pull_function(**context):
value = context['task_instance'].xcom_pull(task_ids='bash_task')
But with Airflow 2.0, the same code is more straightforward:
# assigns output to the `output` variable for use later in the DAG output = BashOperator(task_id="bash_task", bash_command="echo 'Hello World'")
It’s quite clear that the new code is much cleaner, making it easier for the developer to get the output of that bash command.
GKE Operations on Airflow 1.0 vs 2.0
In my previous article, I used KubernetesPodOperator to run a container within a GKE cluster. This worked fine, but Airflow 2.0 is now allowing a different way of performing this operation for improved results. Google has created a set of operators for interacting specifically with GKE clusters, unlike the more general Kubernetes ones in Airflow 1.0.
The three operators I will use now are GKECreateClusterOperator, GKEStartPodOperator, and GKEDeleteClusterOperator. The names are pretty self-explanatory. They create a GKE cluster, start a pod, and delete a GKE cluster respectively. Now let’s see them all in action via a very simple Airflow 2.0 DAG to understand the dynamics.
Sample Airflow 2.0 GKE DAG
The GitHub repository I’m referencing for the rest of this article is located here. I’m referencing the new_cluster_gke_pod.py file in this section.
This is a very simple DAG that performs 3 operations: creates a GKE cluster, runs a dummy process as a pod on the GKE cluster, and deletes the GKE cluster. It makes it very easy to demonstrate the structure of an Airflow 2.0 DAG vs the old style. You will soon notice that the code is structured like a Python script, unlike the domain-specific language of Airflow 1.0.
This can be very useful for running processes on a transient GKE cluster, meaning it “lives” only as long as required. This also may be a great way to run ad hoc processes that need the power of a Kubernetes cluster, but don’t require any resources upon completion.
A quick pricing tip. If you are using this method in production, I recommend using a compute instance type that’s already discounted and not applicable for a sustained use discount, like the n2d instance types. The reason for this is that they are short-lived instances and won’t receive any sustained usage discount. So if you use an instance type with the discount already applied, it will save you money in the long run.
The Old DAG Reimagined for Airflow 2.0
In my previous article, I showed how to use create a new node pool on a GKE cluster in Composer and schedule a pod within a DAG. This process was relatively easy to perform and involved just a few steps. One of the problems with new technology is that sometimes existing code needs to be changed and modified to work properly without affecting performance.
This is one of these cases. I had to modify the code to work in Airflow 2.0, but this was a blessing in disguise. It also forced me to apply the KISS (Keep It Simple Stupid) principle to the existing DAG and break down operations into simpler individual steps. This means it is much easier to read and follow, since each individual step is broken down to make its core purpose clear.
You will also note that I have put in some updated cleanup code that removes used Airflow variables.
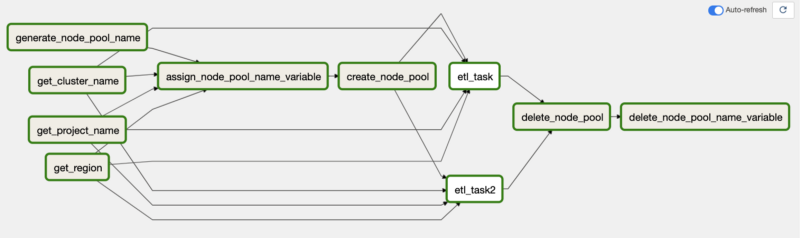
At first glance, you will notice there are a lot more tasks and arrows within this DAG. Due to it being more like Python code and less like Airflow, this requires some tasks to get values from the environment and store them as Python variables.
Let me get one gripe out of the way before we continue. The visualization in Airflow 2.0 can be confusing at first as it tends to group things in ways that make it difficult to follow the flow visually during execution in the user interface. As you can see in the screenshot above, everything looks a little convoluted with the arrows.
To simplify this and clear up the confusion, here’s the task from my Python code that defines the execution flow (items in brackets are run in parallel):
[get_project_name_task, get_cluster_name_task, get_zone_task] >>
assign_node_pool_name_to_variable_task >>
create_node_pool_task >>
[etl_task, etl_task2] >>
delete_node_pool_task >>
delete_node_pool_name_to_variable_task
The first set of tasks simply pulls out values from the Composer environment that are needed for execution, followed by assigning the node pool name to an Airflow variable. In the previous article, these were all contained in a single BashOperator, but I broke them down to simplify things.
Next, it creates the node pool, executes the two dummy ETL tasks in parallel, deletes the node pool upon completion, and lastly deletes the variable containing the node pool name variable in Airflow, a new step I added for cleanup. This step should have been performed in the previous article as well. It’s the same workflow as before, just a little more granular in nature.
Comparison of the Approaches
Both of these approaches perform the same operation of scheduling containers on a GKE cluster for execution with a very minimal difference in pricing. GKE pricing can be found here.
There is no clear answer on which one is the better choice, as it will depend upon your use case and environment. In general, if you don’t have an existing GKE cluster running workloads, you may want to use a node pool on the Airflow cluster. If you do run other workloads on a GKE cluster that can handle the additional load, it’s best to schedule it on this cluster.
Please note that ETL tasks are very resource-heavy in general. This means if you choose to run this on an existing GKE cluster, make sure that the node instance types are large enough to handle the extra resource usage. It may also be a good idea to enable autoscaling just to be on the safe side.
A hybrid approach, involving the creation of a separate node pool on an existing GKE cluster and then scheduling on that, can be the way out.
Going Forward with Airflow 2.0
With Airflow 2.0 now being used globally, I fully expect Google to start shifting most of the existing documentation and recommend it as the default option for all Airflow workloads. I strongly suggest to start moving exisiting Airflow 1.0 workloads and building all new workloads on Airflow 2.0.
The simpler nature of writing DAGs in Airflow 2.0 makes it cleaner and more readable. This will make it easier to maintain in the long term. Trust me, your developers will appreciate this. This is coming from a former dev!
Since the world is moving towards a containerized workload for most purposes, I highly recommend using one of the above two approaches for scheduling workloads on GKE. It’s going to save a lot of trouble as shown in my last article about scheduling and balancing the needs of your workloads.
Kubernetes is the de facto approach for container workloads. Since Google invented it and thankfully keeps their GKE service as the de facto Kubernetes managed service, the most logical thing to do is utilize it for what it does very well. Keep your workloads as efficient as possible for best results.
Thanks for reading! To stay connected, follow us on the DoiT Engineering Blog, DoiT Linkedin Channel, and DoiT Twitter Channel. To explore career opportunities, visit https://careers.doit.com.



