












Tensor Cores boost your neural network training
Deep neural networks are used in numerous cool applications such as self driving cars or phone call transcription. Over the last years networks enabled more sophisticated application using larger and deeper networks. While deeper and larger networks show record breaking results, their training requires more time encumbering development and research in this field. Now, with a new training technique called Mixed Precision that was introduced by Sharan Narang et al 2018 and hardware called Tensor-Cores by Nvidia training deep neural network is faster than ever. In this blog post we will review the code changes required to perform mixed precision with Tensorflow. In a following post we examine the effect of using tensor cores for training GANs.

How much time does it take to train a deep network? Nvidia’s Progressive GAN, for example, was trained for 20 days using multiple powerful GPU’s to achieve outstanding results in generating fake celebrity image. Another example is Google’s NAS based AutoML that utilizes over 800(!) GPUs for several hour in order to find an optimal architecture for image recognition.

In an effort to address the problem of extensive training time, hardware manufacturers like Nvidia and Google develop dedicated processor architectures that boost the training speed like TPUs and Tensor Cores.
Training neural networks can take a long time and can be expensive.
Why does training take a long time?
Neural network are structured as a set of layers nodes and edges that are represented in the memory as matrices. During the training process, the processor performs billions of matrix multiplication to minimize a scalar called “loss”. Generally, software programs are ran on CPUs that are based on the Von Neumann architecture. While this architecture makes CPUs flexible enough to execute a variety of instructions, they are not optimal to perform matrix multiplications. There is a good explanation by Google here about how CPUs perform multiple reads and writes to the memory and why it slows the training process.
GPUs — the more the merrier?
GPUs are an extension of the CPU, the main idea is to have more processor sub-units (ALUs) in order to perform parallel computations. Each core holds a tiny CPU core with less cache and lower clock rate. Thanks to that GPUs can perform large amounts of calculations in short time, reducing the training time of neural networks. However, since the GPU is merely an extension of the CPU, to perform better on a variety of programs instruction it still needs to read and write to the memory.
The solution: a specific architecture for AI training.
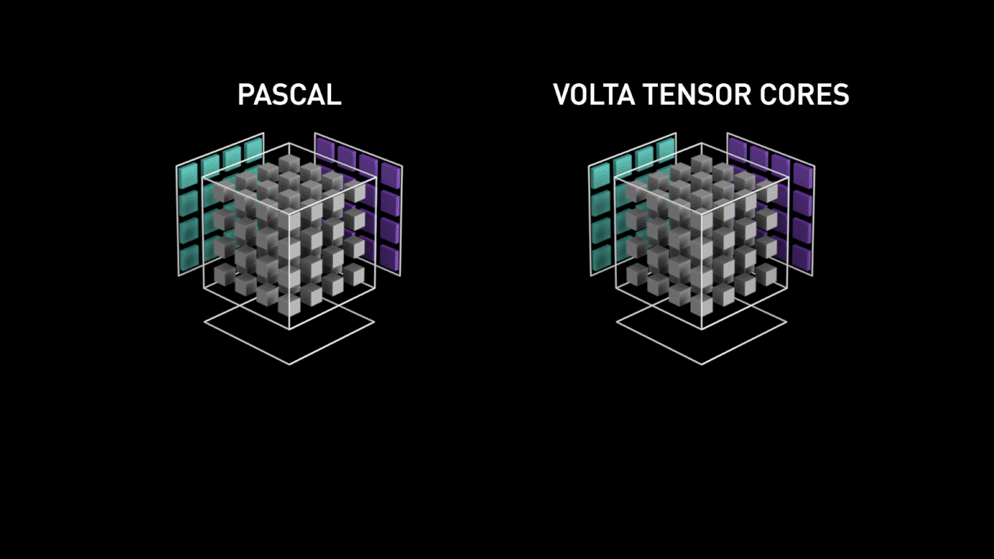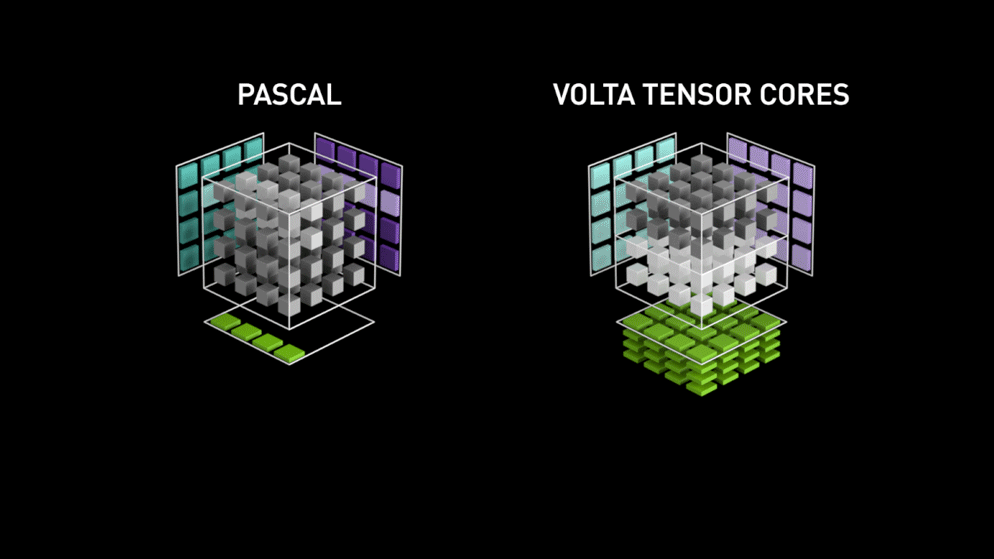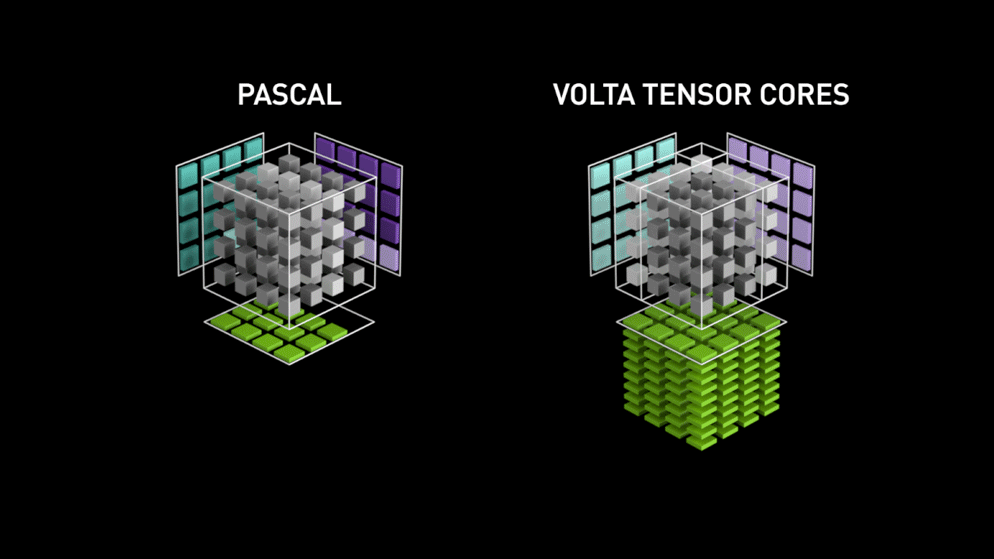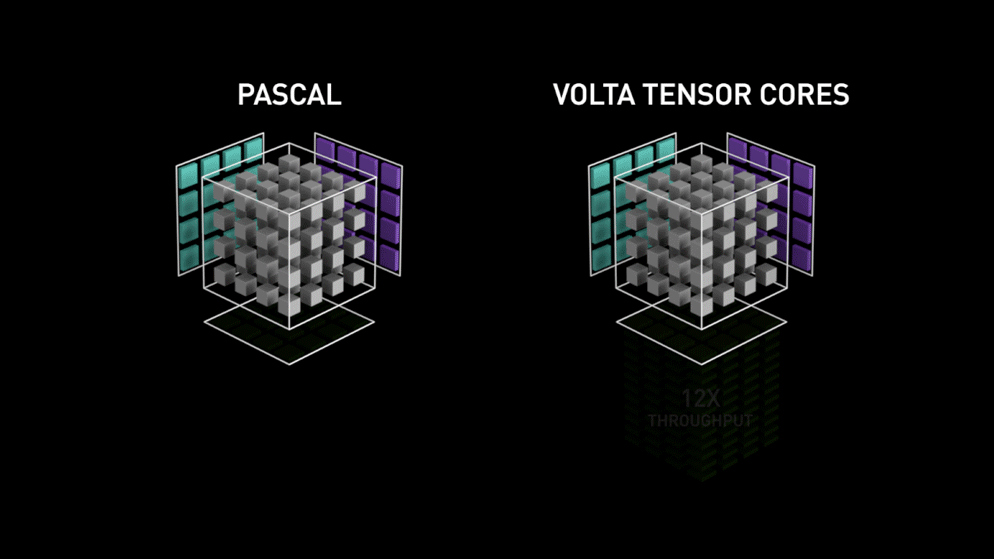
Here comes the new GPU-core architecture — Tensor-cores.
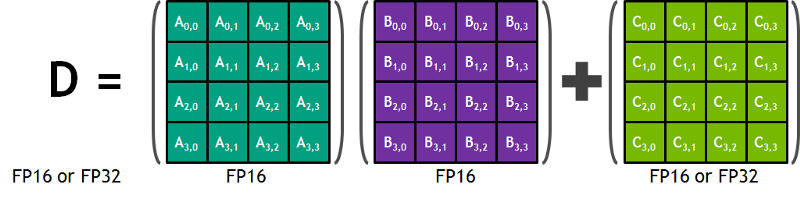
from Nvidia’s blog: “Each Tensor Core provides a 4x4x4 matrix processing array which performs the operation D = A * B + C, where A, B, C and D are 4×4 matrices as Figure 1 shows. The matrix multiply inputs A and B are FP16 matrices, while the accumulation matrices C and D may be FP16 or FP32 matrices.” a drawing only text. This specific architecture requires no memory access during the calculation. Furthermore, each tensor core connected to another tensor and the output of the first will be the input of the proceeding”
Float 16 precision?
Training neural networks is usually done by representing them as matrices of FP32 (Single Precision). However, using FP16 (Half Precision) reduces two constraints that impact the computation speed: memory bandwidth pressure is lowered by using fewer bits to represent the same number of values and the arithmetic time is also reduced by this change. Why not use FP16 for the entire program? Half precision can result in errors such as overflow and underflow in the backpropagation calculation, the reason is that the FP16 representational range is lower than the FP32. For example on the backpropagation process, involves multiplying the weight gradients by the learning rate, and if the product is lower than 1/²¹⁴ it becomes to zero as can see in next figure.
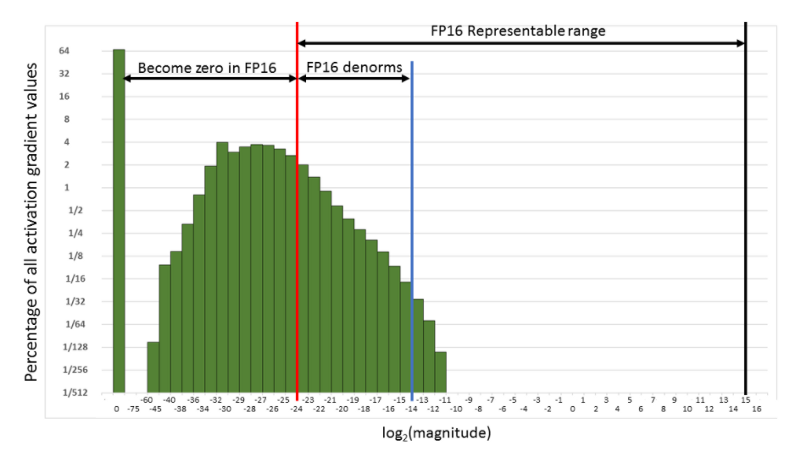
To handle this problem Baidu and Nvidia researchers introduced the the Mixed Precision training, in which specific parts of the program will use float 16 while other parts will remain float 32.
Coding Mixed Precision in Tensorflow
Ok great, but how can I use those tensor cores in code? For the next example, I’ll use Nvidia’s code example and make some changes to it to train deep neural networks using Tensorflow. The full code on GitHub.
Mixed precision stages:
- Create a model using FP16 data-type.
2. Use custom variable getter that forces trainable variables to be stored in
float32 precision and then casts them to the training precision.
3. Use the Tensorflow mixed precision optimization library.
4. Use the training_opt for the training process.
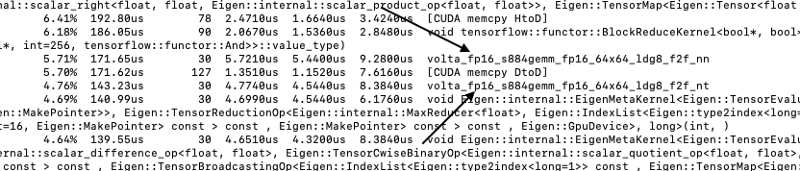
In order to validate that the tensors cores are working use the command ‘nvprof’ to run the script, for example running the script ‘main.py’ :
nvprof python main.py
this will print to the console a log file that contains the core was activated during the training process. the volta_fp16_s884 indicates for using the tensor cores.
In the next part, I’ll use the mix precision process applied to GAN’s, and compare the results on T4, P100, and V100.



