Comment migrer en douceur vos commitments BigQuery flat-rate arrivant à expiration vers un autre modèle tarifaire, tout en gardant un usage optimisé par la suite. Nous abordons précisément quels types de workloads tirent le meilleur parti d'Editions par rapport à la tarification on-demand, et comment maintenir vos workloads optimisés après une sortie du flat-rate (ou de manière générale).

Lorsque BigQuery Editions a été annoncé fin mars de l'an dernier, les entreprises avaient jusqu'au 5 juillet 2023 pour trancher pour chacun de leurs projets :
- Passer à Editions
- Continuer (ou basculer) sur la tarification on-demand, augmentée de 25 %
- Souscrire un commitment flat-rate annuel pour conserver le flat-rate pendant un an
Beaucoup ont opté pour un commitment flat-rate d'un an, afin de se laisser le temps de réarchitecturer leurs workloads BigQuery et de bien prendre en main le nouvel autoscaler, les métriques en slot-hour et Editions dans son ensemble.
Si cela vous parle, une décision lourde de conséquences financières vous attend à l'approche de l'expiration de vos commitments flat-rate : passer à Editions ou basculer en on-demand.
Nous allons donc voir comment migrer en douceur vos commitments BigQuery flat-rate arrivant à expiration vers un autre modèle tarifaire, et garder un usage optimisé par la suite.
Au programme :
- Quels types de workloads sont mieux servis par Editions ou par la tarification on-demand
- Comment garder vos workloads optimisés après une sortie du flat-rate (ou en général)
Nous avons aussi traité ce sujet dans notre podcast Cloud Masters, si vous préférez l'écouter ou le visionner :

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Sortir de votre commitment flat-rate arrivant à expiration
Si vous ne tranchez pas avant l'expiration de votre commitment flat-rate, votre projet sera automatiquement converti en réservation Enterprise Edition, avec les baseline et max slots calés sur le nombre de slots auquel vous étiez engagé.
Et puisque les jobs sur Enterprise Edition coûtent environ 2,53 fois plus par slot utilisé qu'en flat-rate, mieux vaut déterminer en amont si Enterprise Edition — ou Editions de manière générale — a du sens pour votre workload.
Cela dit, identifier le modèle tarifaire le plus adapté n'a rien d'évident.
Pourquoi le choix du modèle tarifaire BigQuery dépend du contexte
Avant d'aborder les cas de figure auxquels chaque modèle convient le mieux, passons en revue quelques points à connaître pour bien les évaluer.
On-demand
Le on-demand offre davantage de capacité de calcul à un meilleur prix que n'importe quelle Edition.
Revers de la médaille : la facturation se faisant sur les données traitées ou scannées, les jobs qui parcourent d'énormes volumes peuvent revenir plus cher en on-demand. À cela s'ajoute un plafond de 2 000 slots.
BigQuery Editions
Avec BigQuery Editions, la facturation s'effectue au slot-hour sur les slots alloués, et non sur les slots utilisés. Un point clé à garder en tête lorsque vous utilisez l'autoscaler de slots fourni avec Editions.
Peut-être qu'en flat-rate, vous avez parfois eu besoin de plus de slots que ceux engagés à certains moments de la journée. Dans ce cas, l'autoscaler peut faire pencher la balance du côté d'Editions.
Restez prudent toutefois : l'autoscaler s'ajuste par tranches de 100 slots, sur une durée minimale de 60 secondes. Vous vous exposez donc à du gaspillage de slots ou à un surcoût.
Par exemple, si un job nécessite 101 slots, l'autoscaler vous fera passer à 200, vous obligeant à payer 99 slots inutiles.
Autre cas : un job qui requiert 200 slots pendant seulement six secondes. Vous paierez 200 slots durant 54 secondes de plus que nécessaire.
Règle empirique pour choisir le bon modèle tarifaire
Il faut comparer le nombre de slots utilisés par votre job au volume de données scannées pour savoir s'il revient moins cher en on-demand ou en Editions. Pensez aussi aux exigences de vitesse et de performance.
Vous exécutez peut-être par exemple beaucoup de jobs d'analyse statistique gourmands en calcul mais légers en slots (agrégations, k-means, etc.). Si vous scannez 1 To de données à chaque exécution, le coût grimpe à 6,25 $ en on-demand. En revanche, en plaçant ce job sur Standard Edition avec 100 slots dédiés, il peut tomber à 2 $ seulement.
Multipliez par le nombre d'exécutions : la différence devient significative entre les deux modèles.
Les jobs peuvent prendre un peu plus de temps sous Editions, mais les 68 % d'écart de coût en valent peut-être la peine.
La décision se prend workload par workload.

Quels workloads sont les plus adaptés à BigQuery Editions ?
De manière générale, les workloads de longue durée avec très peu de pics se prêtent parfaitement à Editions. C'est encore mieux s'ils brassent de gros volumes de données. La raison : l'autoscaler BigQuery peut se montrer agressif face aux workloads en pics.
Imaginez par exemple un projet exécutant un job BigQuery gourmand en slots à un moment précis de la journée.
Sous Editions, votre consommation de slots va s'envoler pendant le job (avec en plus la facturation des slots supplémentaires au-delà du nécessaire, sur une durée minimale d'une minute), entraînant des coûts imprévisibles durant les pics.
En revanche, lorsque vos workloads BigQuery sont réguliers mais conséquents, acheter des slots via les modèles tarifaires Editions revient souvent moins cher que le on-demand et garantit une disponibilité constante de vos ressources de calcul BigQuery à un coût prévisible et planifiable.
Exemples typiques : des jobs analytiques réguliers de longue durée, ou une tâche de machine learning qui mouline beaucoup de données pendant des heures.
Quels workloads sont les plus adaptés à la tarification on-demand de BigQuery ?
À l'inverse, pour des workloads en pics ou sporadiques — courtes rafales de traitement intense suivies de longues plages d'inactivité — la tarification on-demand est souvent la meilleure option.
C'est typiquement le cas des projets de dev/test ou des workloads BI. Mieux vaut alors payer au volume de données traitées, le coût d'exécution étant bien inférieur à celui d'une réservation BQ Editions, même modeste.
Pensez également aux jobs qui ne traitent pas de données mais consomment tout de même des slots. Les rafraîchissements de métadonnées BigLake, où le schéma de la table est rafraîchi et rechargé sans réel traitement de données, en sont un exemple parfait. Si ce job s'exécute dans un projet en tarification Editions, vous payez les slots scalés (et non utilisés). En tarification on-demand, le coût est de 0 $.
Séparez vos workloads pour optimiser vos coûts BigQuery
En matière de tarification BigQuery, il n'existe pas d'approche universelle.
Puisque vous pouvez appliquer différents modèles tarifaires BigQuery selon les projets, commencez par vérifier que vos workloads sont répartis dans des projets dédiés, et non regroupés dans un seul projet.
Placer chaque type de workload dans un projet distinct — et y appliquer le palier tarifaire BigQuery adéquat — est un excellent levier de réduction des coûts BigQuery, car cela facilite l'adéquation entre le modèle tarifaire et chaque workload.
Si vos workloads ne sont pas déjà isolés dans des projets distincts, mieux vaut commencer par là.
Par exemple :
- Les workloads ETL et ELT devraient être dans un projet séparé de vos workloads R&D
- Les workloads en pics et de courte durée devraient être dans un projet utilisant la tarification on-demand
Si la majorité de vos workloads se trouvent dans un projet principal, vous pouvez craindre que le scinder soit trop complexe. Il y aura des changements de configuration à prévoir — vous devrez peut-être modifier vos macros si vous utilisez dbt, par exemple. Mais pesez aussi les conséquences de ne pas répartir vos workloads BigQuery dans plusieurs projets.
Imaginez une entreprise dont les jobs quotidiens de pipeline de données cohabitent dans un même projet avec des analyses exploratoires ad hoc. Si le projet utilise une BigQuery Edition, elle dépensera trop sur les requêtes ad hoc — et inversement si le projet est en on-demand.
Calculer le palier tarifaire BigQuery le mieux adapté à votre workload
Les experts BigQuery de DoiT ont mis au point un script qui vous aide à déterminer le modèle tarifaire le plus pertinent pour chacun de vos workloads (autrement dit, de vos projets).
Il analyse chaque requête exécutée dans un projet sur une période que vous définissez, et renvoie une recommandation de modèle tarifaire (on-demand ou une Edition spécifique).
Voici quelques scripts complémentaires développés par notre équipe qui pourraient vous être utiles :
- Requêtes les plus complexes (selon l'utilisation moyenne de slots durant le job).
- Requêtes les plus coûteuses, classées de la plus chère à la moins chère
- Informations générales sur les jobs
- Faut-il passer au stockage physique ou rester sur le stockage logique
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Comment garder vos coûts BigQuery optimisés
Une fois identifié le modèle tarifaire qui correspond à chacun de vos workloads, encore faut-il s'assurer que vos coûts restent optimisés sur la durée. Cette section passe en revue plusieurs leviers — certains éprouvés, d'autres apparus avec Editions — pour éviter de trop dépenser sur BigQuery.
Partitionnez et clusterisez vos tables pour réduire les données traitées
Réduire les octets traités par vos requêtes améliore leurs performances tout en faisant baisser les coûts BigQuery, quel que soit le modèle tarifaire — et le partitionnement et/ou le clustering des tables sont d'excellents moyens d'y parvenir.
Pour les projets en tarification on-demand, la baisse des coûts d'analyse est directe puisque vous payez en fonction des données scannées.
Avec BigQuery Editions, plus une requête a de données à traiter, plus de slots sont alloués. Donc, même si BigQuery Editions est facturé au slot-hour, réduire les octets traités peut indirectement réduire le besoin de slots.
Clusterisation des tables BigQuery
Le clustering améliore les performances de vos requêtes en organisant la table en blocs de données, selon la ou les colonnes choisies. BigQuery peut alors scanner uniquement les blocs pertinents.
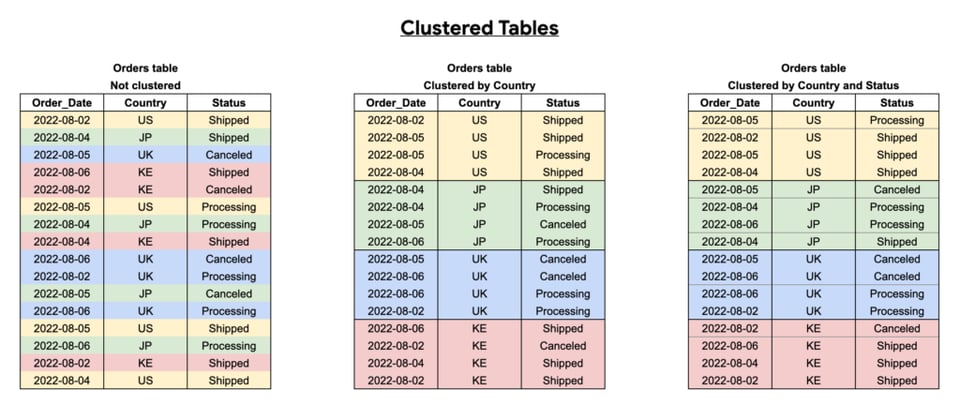
Clusterisez vos tables sur les colonnes fréquemment interrogées, surtout lorsqu'elles contiennent de nombreuses valeurs distinctes.
Comme on le voit ci-dessous, l'efficacité du clustering dépend des colonnes sélectionnées, de l'ordre choisi et de la façon dont vos requêtes sont structurées.
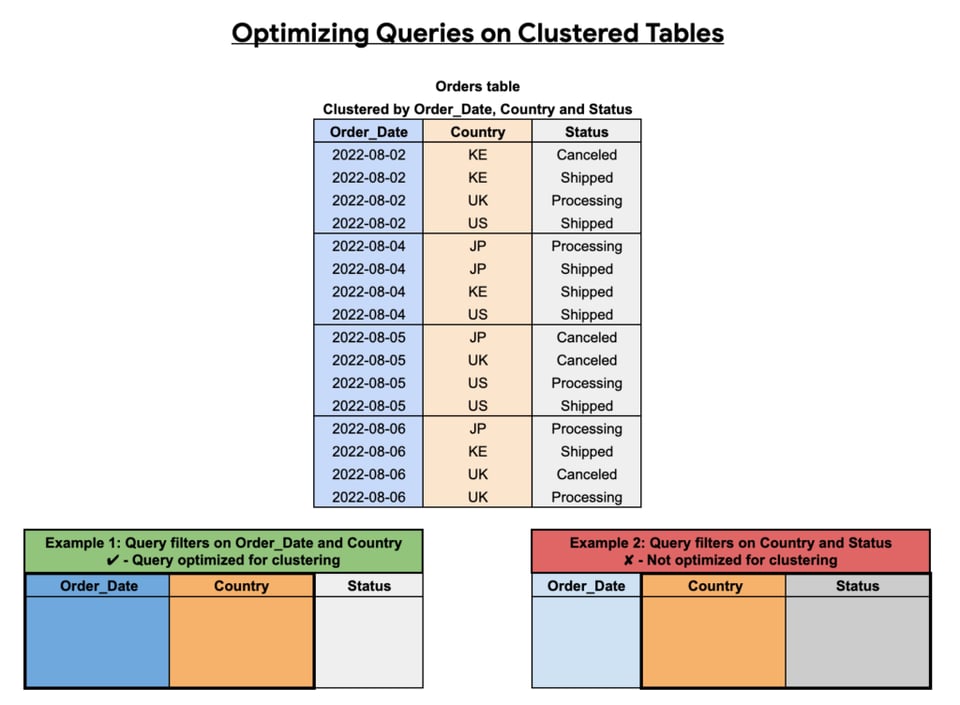
Partitionnement des tables BigQuery
Le partitionnement des tables aide à maîtriser les coûts en divisant une grande table en blocs plus petits, ce qui permet d'interroger un sous-ensemble plus restreint.
Mais attention : partitionner une table ne sert à rien si vos requêtes ne précisent pas les partitions à scanner — c'est ce qu'on appelle le partition pruning.
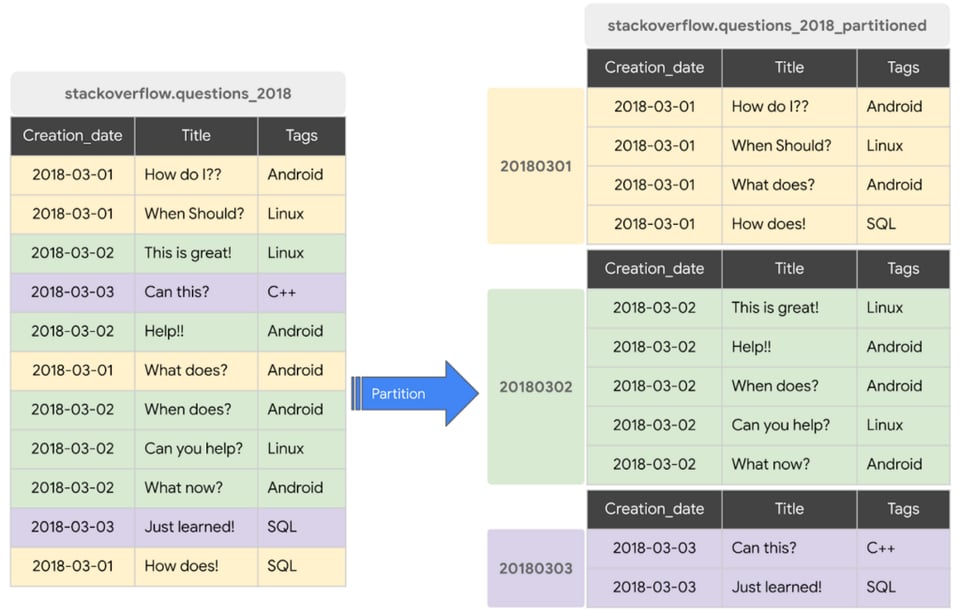
Un exemple de requête utilisant une partition pour la capture ci-dessus :
SELECT * FROM stackoverflow_questions_2018 WHERE creation_date BETWEEN ‘2018-01-01’ AND ‘2018-01-31’Et un exemple de requête qui n'utilisera PAS de partition :
SELECT * FROM stackoverflow_questions_2018Si le partitionnement est conseillé en règle générale, il devient incontournable dès lors que vous avez des dashboards BI s'appuyant sur BigQuery : il accélère vos dashboards et fait baisser le coût des requêtes.
Identifier les tables à clusteriser ou à partitionner
De manière générale, partitionnez les tables volumineuses (>100 Go) lorsque les requêtes filtrent fréquemment sur des champs de date ou d'heure.
Utilisez le clustering quand vos requêtes filtrent ou agrègent souvent les données sur des colonnes spécifiques. Pour déterminer le ou les champs sur lesquels clusteriser une table (et dans quel ordre), regardez les colonnes les plus utilisées dans les clauses WHERE ou GROUP BY — et, dans une moindre mesure, ORDER BY. L'ordre choisi influencera le tri des données par BigQuery : placez en premier les colonnes les plus fréquemment utilisées en filtre ou en agrégation.
Si vous utilisez DoiT Cloud Navigator, vous accédez à BigQuery Lens, qui fait remonter des recommandations sur les tables à clusteriser ou partitionner — et sur les colonnes à privilégier.
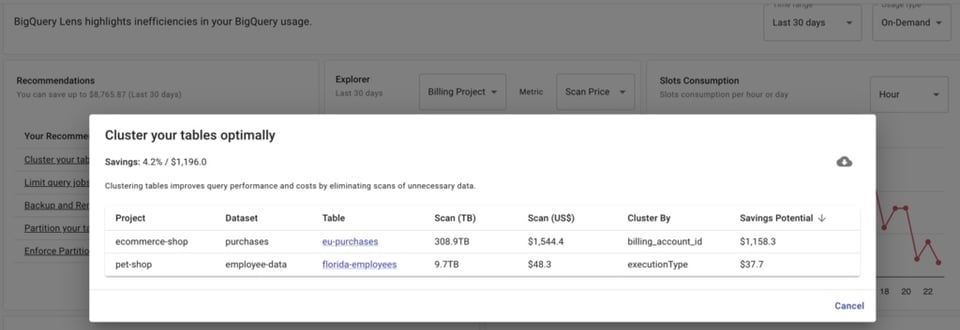
Mais même avec des tables déjà partitionnées, il faut s'assurer qu'elles sont interrogées via le champ de partitionnement. C'est ce qui vous donne plus de contrôle sur les coûts, en scannant des portions plus petites plutôt que la table entière.
Or, lorsqu'on pilote une équipe d'analystes, difficile de savoir si chacun inclut bien le champ de partitionnement dans ses requêtes.
BigQuery Lens identifie les jobs qui interrogent des tables partitionnées sans utiliser le champ de partitionnement.
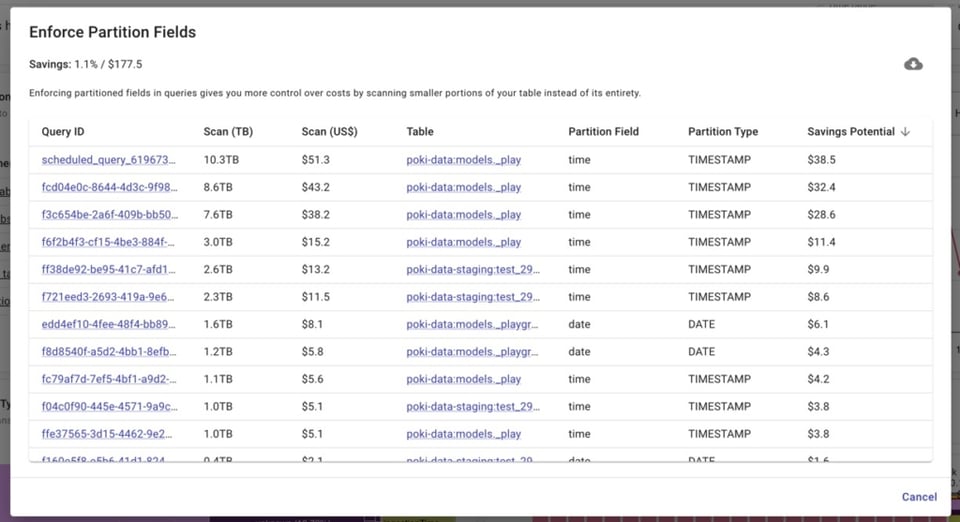
Configurer correctement vos baseline et max slots
Si vous utilisez déjà BigQuery Editions ou prévoyez d'y passer, savoir configurer correctement vos baseline et max slots est essentiel pour tirer parti de l'autoscaler de BigQuery.
Conseils pour la configuration des baseline slots
Vos baseline slots correspondent au nombre minimum de slots que vous voulez avoir en permanence à disposition pour vos requêtes. En les définissant, gardez à l'esprit qu'ils sont facturés 24 h/24 et 7 j/7.
Si vos workloads sont réguliers et stables tout au long de la journée, fixez une baseline plus élevée pour éviter les cold starts et la mise en file d'attente.
Pour les workloads en pics ou par rafales, il peut être judicieux de fixer la baseline basse, voire à 0, afin de ne pas payer de slots inutilisés. Notez toutefois qu'il faut quelques secondes à l'autoscaler pour passer de 0 à X slots. La montée en charge prendra donc du temps pour le premier job, et si celui-ci tourne encore quand un autre démarre, il faudra à nouveau du temps pour scaler.
Conseils pour la configuration des max slots
La limite de max slots fixe le nombre maximum de slots auxquels BigQuery peut automatiquement scaler pour vos workloads. Bien la régler est essentiel pour maîtriser les coûts et éviter que l'autoscaler ne sur-provisionne des slots.
Analysez vos historiques d'utilisation de slots (avec les scripts mentionnés plus haut) pour fixer un maximum raisonnable, capable d'absorber les pics tout en limitant le sur-provisionnement.
Ajuster dynamiquement le modèle tarifaire utilisé dans vos réservations
Au sein d'un même projet, certaines activités peuvent être plus performantes (ou moins coûteuses) sous Editions, et d'autres en on-demand.
Par exemple :
- Les requêtes interactives ont lieu principalement en semaine, durant les heures ouvrées
- Forte concurrence de requêtes avec des temps de réponse rapides
- Certaines tâches sont planifiées la nuit ou le week-end
L'idéal serait alors d'utiliser le on-demand pendant les heures ouvrées, pour une bonne latence et une forte concurrence, et de basculer sur l'Enterprise Edition avec un maximum de 100 slots en dehors des heures ouvrées.
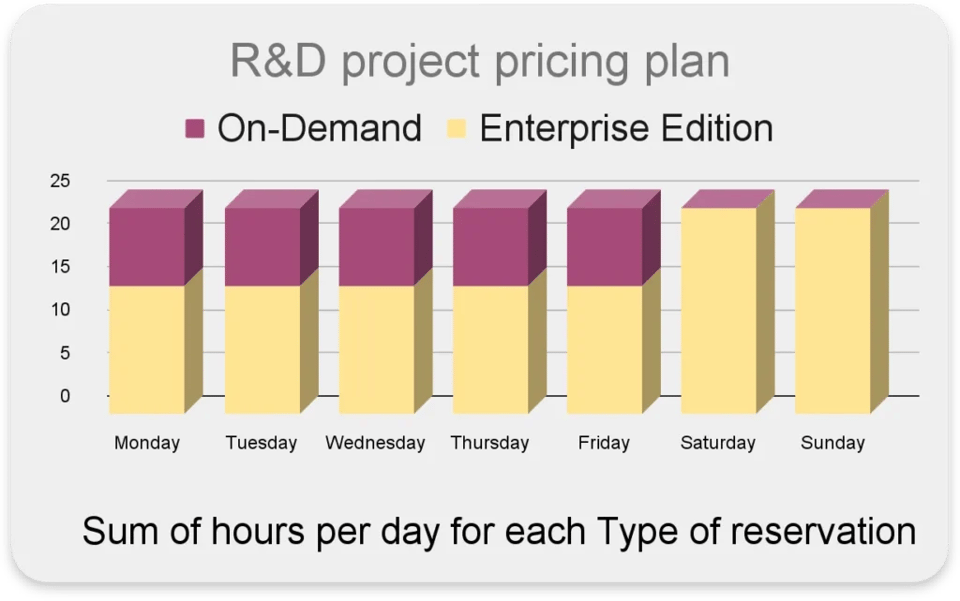
Nadav Weissman, l'un de nos experts BigQuery, détaille étape par étape ici comment automatiser les changements de réservation et d'assignation à cette fin.
Bonnes pratiques pour dbt, Dataform et les outils de BI
dbt et Dataform
Pour commencer, vous voudrez probablement utiliser la tarification on-demand pour vos jobs dbt ou Dataform. dbt est gourmand en calcul/slots, et il est souvent préférable d'opter pour le on-demand — ou au moins de surveiller de près vos paramètres baseline/max slots si vous utilisez Editions.
dbt est gourmand en calcul/slots, et il est souvent préférable d'opter pour le on-demand — ou de définir des nombres de slots réalistes dans votre configuration baseline/max pour l'autoscaler.
Aussi bien dans dbt (Incremental models) que dans Dataform (incremental tables), vous pouvez ne traiter que les données nouvelles ou modifiées plutôt que de retraiter l'ensemble du dataset. Le volume de données traitées baisse, ce qui optimise l'utilisation des slots et les coûts.
Enfin, vous pouvez réaliser des économies en délestant les jobs de transformation dbt/Dataform de BigQuery vers des services au calcul moins coûteux, les transformations étant gourmandes en calcul.
Par exemple, il est nettement moins cher d'exécuter les transformations sur une VM ou une instance Cloud SQL, puis de remettre les données transformées dans Google Cloud Storage avant de les recharger dans BigQuery déjà transformées. Cette approche demande un peu d'orchestration, mais nous avons vu des clients faire passer des jobs de transformation de 50 $ à 2-3 $ avec cette méthode.
Outils de BI
Si vous utilisez un outil de BI comme Looker ou Tableau avec BigQuery, principalement pour des opérations de lecture et de l'agrégation de données dans le temps, jetez un œil à BI Engine.
BI Engine est parfait pour les requêtes de dashboard : il met intelligemment en cache les données BigQuery en mémoire, ce qui accélère les requêtes. Et puisque les données sont mises en cache en mémoire, l'étape de requête qui lit les données de la table est gratuite. Vous ne payez que la capacité mémoire réservée.
Notez que pour utiliser BI Engine, votre projet doit être en Enterprise Edition. Mais si vous isolez vos workloads BI dans leur propre projet, le modèle tarifaire au slot-hour vous impactera moins (à condition de réaliser essentiellement des opérations de lecture), compte tenu de la tarification de BI Engine évoquée plus haut.
Si vous transformez aussi beaucoup de données dans vos workloads BI, c'est moins pertinent pour vous, certaines limitations existant autour des JOINs.
Autre approche : recourir à une solution à tarif fixe comme ClickHouse, que votre outil de BI interrogera à la place de BigQuery, soit pour gagner en performance, soit pour alléger votre facture BigQuery. L'avantage : vous payez un tarif forfaitaire pour le datastore plutôt qu'un tarif à la requête comme avec BigQuery.
Conclusion
Que vos commitments BigQuery flat-rate soient sur le point d'expirer ou non, cet article vous aide à choisir le meilleur modèle tarifaire pour vos workloads, et à mener en amont les chantiers nécessaires pour éviter de trop dépenser.
Nous proposons également des conseils pour optimiser vos coûts BigQuery : partitionner et clusteriser vos tables, configurer correctement vos baseline et max slots, et utiliser BI Engine pour les workloads BI. En suivant ces recommandations, vous tirerez de BigQuery le meilleur rapport coût-efficacité.
Pour analyser votre usage BigQuery avec un spécialiste BigQuery de DoiT, réservez une consultation avec nous dès aujourd'hui !