Como migrar sem dor de cabeça seus commitments flat-rate do BigQuery que estão expirando para outro plano de preços e manter o uso otimizado depois disso. Em detalhes, vamos mostrar quais tipos de workloads se saem melhor no Editions e quais combinam mais com o preço on-demand, além de como manter os workloads otimizados depois da saída do flat-rate (ou em qualquer cenário).

Quando o BigQuery Editions foi anunciado no fim de março do ano passado, as empresas tinham até 05/07/2023 para tomar uma decisão sobre cada um dos seus projetos:
- Migrar para o Editions
- Continuar (ou passar a usar) o preço on-demand, que ficou 25% mais caro
- Comprar um commitment flat-rate anual e seguir no flat-rate por mais um ano
Muita gente optou pelos commitments flat-rate de 1 ano para ganhar tempo, repensar a arquitetura dos workloads do BigQuery e entender melhor o novo autoscaler, as métricas de slot-hour e o Editions como um todo.
Se esse é o seu caso, você tem uma decisão importante pela frente — com grande impacto nos custos — à medida que seu(s) commitment(s) flat-rate começam a expirar: ir para o Editions ou para o on-demand.
Por isso, vamos explicar como fazer essa transição sem sustos e manter o uso otimizado depois.
Em detalhes, vamos cobrir:
- Quais tipos de workloads se saem melhor no Editions e quais combinam mais com o preço on-demand
- Como manter seus workloads otimizados depois de sair do flat-rate (ou em qualquer cenário)
Também falamos sobre isso no nosso podcast Cloud Masters, caso prefira ouvir/assistir em vez de ler:

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Como sair do commitment flat-rate que está expirando
Se você não tomar uma decisão antes que o commitment flat-rate expire, seu projeto será automaticamente convertido em uma reserva Enterprise Edition, com os slots baseline e máximo ajustados ao número de slots que você tinha contratado.
E como os jobs no Enterprise Edition saem cerca de 2,53x mais caros por slot utilizado em comparação ao flat-rate, vale avaliar antes se o Enterprise Edition — ou o Editions em geral — faz sentido para o seu workload.
Mas não é tão simples definir qual plano de preços é o ideal no seu caso.
Por que "depende" qual modelo de preços do BigQuery é o melhor para você
Antes de entrar nos cenários em que cada modelo se encaixa melhor, vale revisar alguns pontos importantes sobre cada um para te ajudar na avaliação.
On-demand
O on-demand entrega mais capacidade de processamento por um preço melhor do que qualquer Edition.
Em compensação, como a cobrança é baseada nos dados processados ou escaneados, jobs que varrem muitos dados podem sair mais caros no on-demand. Além disso, há um teto de 2.000 slots.
BigQuery Editions
No BigQuery Editions, a cobrança é por slot-hour com base nos slots alocados, e não nos slots usados. Isso é importante de lembrar quando você usa o autoscaler de slots que vem com o Editions.
Pode ser que, no flat-rate, você tenha percebido que precisava de mais slots do que os contratados em determinados horários do dia. Nesse caso, o autoscaler pode pesar a balança a favor do Editions.
Mas é preciso ter cuidado, porque o autoscaler escala em incrementos de 100 slots, com mínimo de 60 segundos. Isso te deixa exposto a desperdício ou gasto excessivo com slots.
Por exemplo: se um job precisa de 101 slots, o autoscaler vai te jogar para 200, te obrigando a pagar por 99 slots que você não precisava.
Ou imagine um job que exige 200 slots por apenas seis segundos. Nesse caso, você pagaria por 200 slots durante 54 segundos a mais do que o necessário.
Regra prática para escolher o modelo de preços certo
Você vai precisar comparar quantos slots o job está usando com o volume de dados que ele escaneia para definir se sai mais barato no on-demand ou no Editions. Considere também as necessidades de velocidade/desempenho.
Por exemplo: digamos que você roda muitos jobs de análise estatística (agregações, k-means etc.) que são intensivos em processamento, mas leves em slots. Se cada execução escaneia 1 TB de dados, o custo é de US$ 6,25 no on-demand. Já se você colocar esse mesmo job no Standard Edition e dedicar 100 slots a ele, pode custar só US$ 2,00.
Multiplique pela quantidade de execuções e a diferença entre os dois modelos fica significativa.
Pode ser que os jobs demorem mais no Editions, mas talvez essa diferença de 68% no custo compense para você.
É uma decisão que precisa ser tomada workload por workload.

Quais workloads se saem melhor no BigQuery Editions?
De modo geral, workloads de longa duração e com poucos picos combinam muito bem com o Editions. Melhor ainda se eles leem grandes volumes de dados, já que o autoscaler do BigQuery pode ser agressivo com workloads que têm picos.
Imagine, por exemplo, um projeto que executa um job intensivo em slots em um horário fixo do dia.
Se você rodar isso no Editions, o uso de slots vai disparar enquanto o job é executado (com slots adicionais além do necessário também sendo cobrados, por no mínimo um minuto), gerando imprevisibilidade nos custos durante os picos.
Por outro lado, quando você tem workloads consistentes, mas relevantes em volume, comprar slots pelos planos do Editions costuma sair mais barato do que o on-demand e garante disponibilidade estável dos recursos de computação do BigQuery, com um preço previsível e fácil de planejar.
Exemplos: jobs de analytics regulares e de longa duração, ou tarefas de machine learning que processam muitos dados e ficam rodando por horas a fio.
Quais workloads se saem melhor no preço on-demand do BigQuery?
Já se você lida com workloads cheios de picos ou esporádicos — surtos curtos de processamento intenso seguidos por longos períodos de inatividade — o preço on-demand costuma ser a melhor escolha.
Isso aparece bastante em projetos de dev/test ou em workloads de BI. Nesses casos, costuma valer a pena pagar pelos bytes processados, já que o custo de execução tende a ser bem menor do que pagar até por uma reserva pequena no BQ Editions.
Pense também nos jobs que não processam dados, mas mesmo assim consomem slots. Os refreshes de metadados do BigLake, em que o schema da tabela é atualizado e recarregado sem processamento real de dados, são um exemplo clássico. Se esse job estivesse em um projeto com preço Editions, você pagaria pelos slots escalados (não usados). Já em um projeto com preço on-demand, o custo é US$ 0.
Divida seus workloads para otimizar custos do BigQuery
Quando o assunto é preço do BigQuery, não existe receita única.
Como dá para usar diferentes modelos de preços do BigQuery em projetos distintos, o primeiro passo é garantir que seus workloads estejam separados em projetos dedicados, e não amontoados em um único projeto.
Colocar diferentes tipos de workload em projetos distintos — e usar diferentes níveis de preço do BigQuery em cada um — é uma ótima forma de reduzir os custos, porque facilita combinar o plano de preços certo com cada workload.
Se seus workloads ainda não estão isolados em projetos diferentes, talvez valha a pena fazer isso primeiro antes de
Por exemplo:
- Workloads de ETL e ELT devem ficar em um projeto separado dos workloads de P&D
- Workloads de curta duração e cheios de picos devem ir para um projeto que use preço on-demand
Se a maior parte dos seus workloads está em um único projeto principal, talvez você ache que dividir o projeto vai ser complicado demais. Existem mudanças de configuração para considerar — por exemplo, talvez você precise alterar suas macros se usa dbt. Mas pense nas consequências de não separar seus workloads do BigQuery em projetos diferentes.
Imagine uma empresa com os jobs diários do pipeline de dados no mesmo projeto que jobs ad-hoc de análise exploratória. Se o projeto estivesse no BigQuery Edition, ela gastaria demais com as consultas ad-hoc; e o oposto valeria se o projeto estivesse no on-demand.
Como calcular qual nível de preço do BigQuery é o melhor para o seu workload
Os especialistas em BigQuery da DoiT desenvolveram um script para te ajudar a descobrir qual modelo de preços faz sentido para cada um dos seus workloads (ou seja, projetos).
Ele analisa todas as consultas executadas em um projeto, dentro de um período definido por você, e devolve uma recomendação de modelo de preços (on-demand ou um Edition específico).
Aqui vão alguns scripts adicionais criados pelo nosso time que podem ser úteis:
- Consultas mais complexas (definidas pelo uso médio de slots durante o job).
- Consultas mais caras, da mais cara para a mais barata
- Informações gerais sobre jobs
- Se vale migrar para Physical Storage ou continuar no logical storage
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Como manter seus custos do BigQuery otimizados
Depois de identificar qual modelo de preços combina com cada workload, é hora de garantir que os custos continuem sob controle daqui para frente. Nesta seção, reunimos várias dicas — algumas clássicas, outras novas com a chegada do Editions — que vão te ajudar a não gastar demais com o BigQuery.
Particione e clusterize suas tabelas para reduzir o volume de dados processados
Reduzir os bytes processados nas suas consultas melhora o desempenho e, ao mesmo tempo, reduz os custos do BigQuery em qualquer modelo de preços — e particionar e/ou clusterizar suas tabelas é uma ótima forma de fazer isso.
Em projetos com preço on-demand, isso reduz diretamente seus custos de análise, já que a cobrança é baseada nos dados escaneados.
E no BigQuery Editions, quanto mais dados uma consulta precisa processar, mais slots são alocados. Ou seja, mesmo que o BigQuery Editions seja cobrado por slot-hour, reduzir os bytes processados pode, indiretamente, exigir menos slots.
Clusterizando tabelas do BigQuery
Clustering melhora o desempenho das consultas ao organizar a tabela em blocos de dados, com base na(s) coluna(s) escolhida(s) para o cluster. Isso facilita para o BigQuery escanear apenas os blocos relevantes.
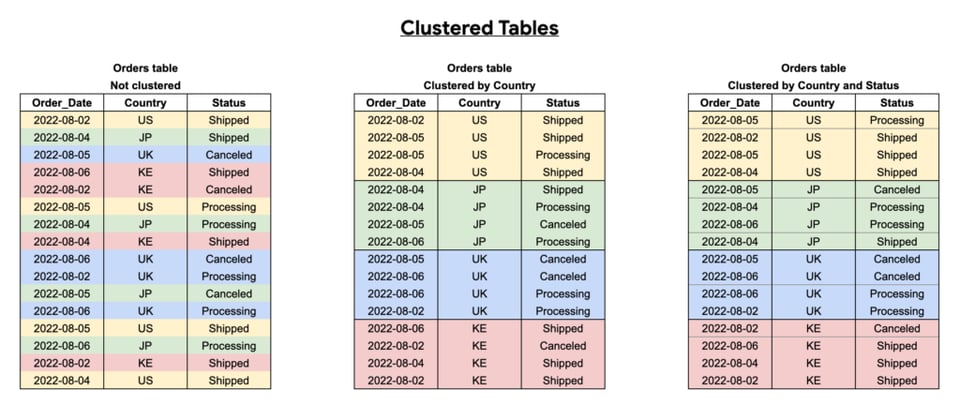
Clusterize as tabelas pelas colunas mais consultadas, principalmente quando elas têm muitos valores distintos.
Como dá para ver abaixo, a eficácia do clustering depende das colunas escolhidas, da ordem definida e de como as consultas são estruturadas.
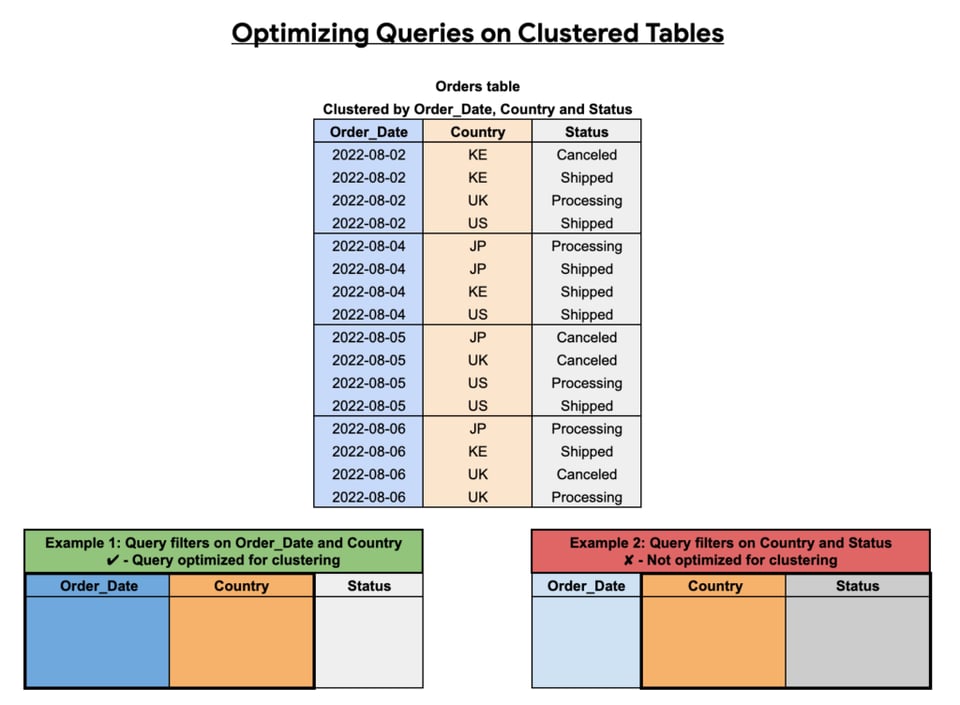
Particionando tabelas do BigQuery
Particionar tabelas ajuda a controlar custos ao dividir uma tabela grande em pedaços menores, permitindo que você consulte só um subconjunto dela.
Mas atenção: particionar uma tabela não vai te ajudar se as consultas não especificarem quais partições devem ser escaneadas, prática conhecida como partition pruning.
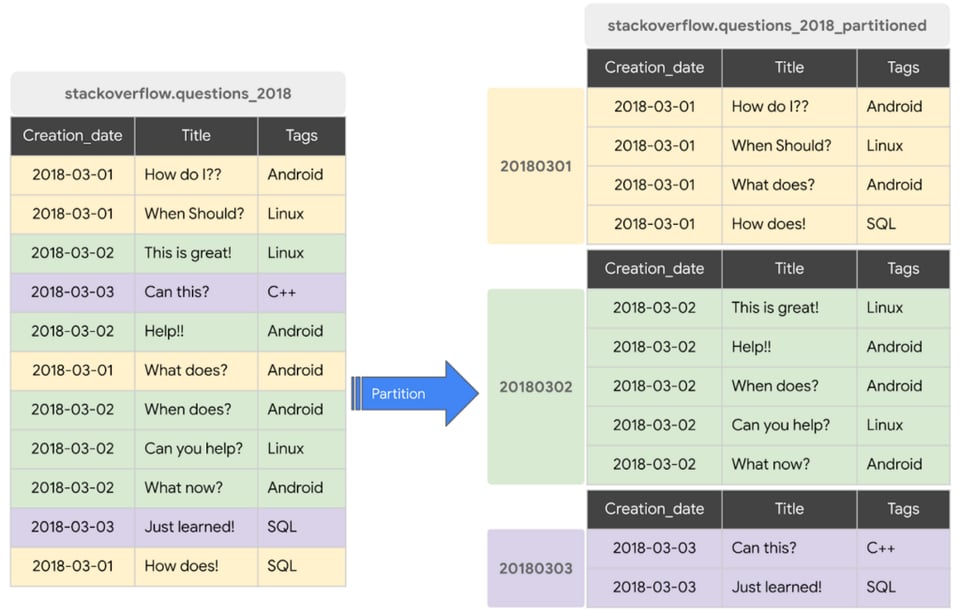
Um exemplo de consulta que usa partição para o screenshot acima seria:
SELECT * FROM stackoverflow_questions_2018 WHERE creation_date BETWEEN ‘2018-01-01’ AND ‘2018-01-31’Já um exemplo de consulta que NÃO usaria partição seria:
SELECT * FROM stackoverflow_questions_2018Embora particionar seja uma boa prática em geral, faça isso especialmente se você tem dashboards de BI rodando em cima do BigQuery, porque as partições deixam os dashboards mais rápidos e as consultas mais baratas.
Como identificar quais tabelas clusterizar ou particionar
De modo geral, particione tabelas grandes (>100 GB) em que as consultas costumam filtrar por campos de data/hora.
Use clustering quando suas consultas filtram ou agregam dados com frequência por colunas específicas. Para definir por qual(is) campo(s) clusterizar uma tabela (e em que ordem), olhe as colunas mais usadas em cláusulas WHERE ou GROUP BY — e, em menor medida, em cláusulas ORDER BY. A ordem das colunas escolhidas afeta como o BigQuery ordena os dados, então priorize as colunas de filtro/agregação mais usadas.
Mas, se você usa o DoiT Cloud Navigator, pode acessar o BigQuery Lens, que traz recomendações sobre quais tabelas clusterizar ou particionar — e em qual(is) coluna(s) fazer isso.
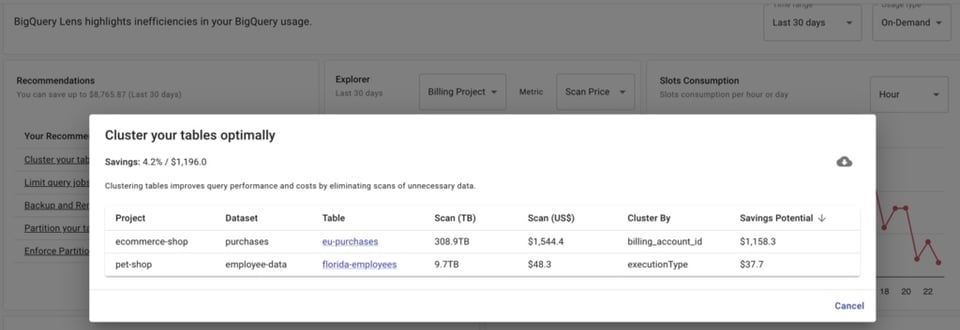
E mesmo já tendo particionado as tabelas, você ainda precisa garantir que as consultas estão usando o campo de partição. É isso que dá mais controle sobre os custos, ao escanear apenas partes menores da tabela em vez de tudo.
Mas, ao gerenciar um time de analistas de dados, é difícil saber se todo mundo está realmente incluindo o campo particionado nas consultas.
O BigQuery Lens identifica jobs que consultam tabelas particionadas sem usar o campo de partição.
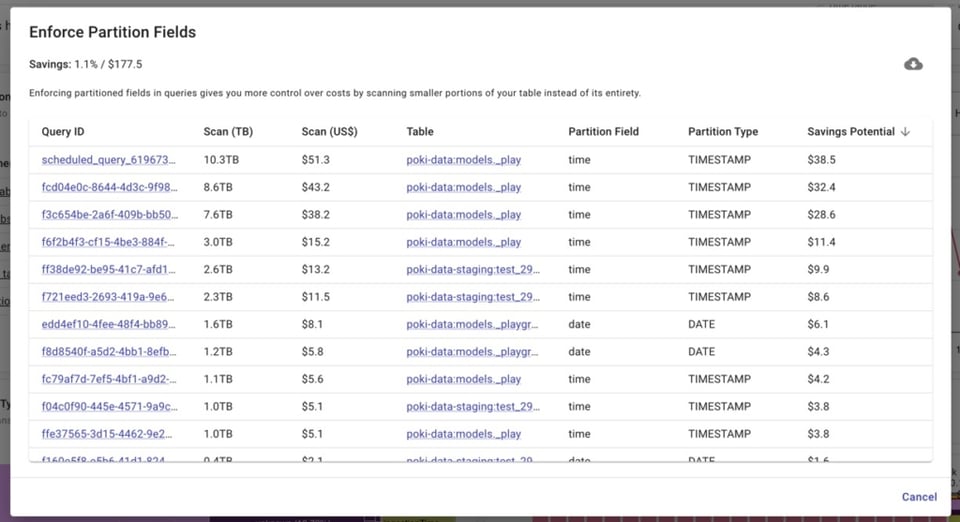
Como configurar seus slots baseline e máximos do jeito certo
Se você já usa o BigQuery Editions ou planeja migrar, saber configurar os slots baseline e máximos do jeito certo é fundamental para tirar proveito do autoscaler do BigQuery.
Dicas para configurar os slots baseline
Os slots baseline são, basicamente, o número mínimo de slots que você quer ter sempre disponíveis para suas consultas. Ao defini-los, lembre-se de que a cobrança roda 24/7.
Se você tem workloads consistentes e estáveis ao longo do dia, defina um baseline mais alto para evitar "cold starts" e filas.
Para workloads cheios de picos ou rajadas, talvez seja melhor manter o baseline baixo ou até em 0, para não pagar por slots ociosos. Só lembre que o autoscaler leva alguns segundos para escalar de 0 até X slots. Ou seja, vai demorar para escalar no primeiro job e, se ele ainda estiver rodando quando outro começar, vai demorar de novo.
Dicas para configurar os slots máximos
O limite de slots máximos define até quantos slots o BigQuery pode escalar automaticamente para os seus workloads. Definir esse máximo do jeito certo é importante para controlar custos e impedir que o autoscaler provisione slots em excesso.
Analise seus padrões históricos de uso de slots (use os scripts citados acima) para definir um máximo razoável que dê conta dos picos sem provisionamento excessivo.
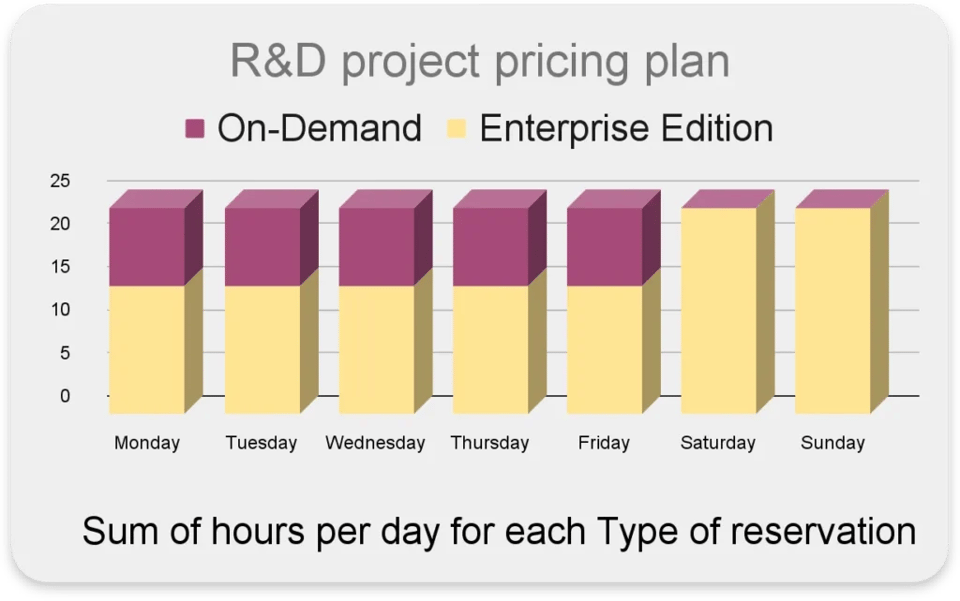
Como ajustar dinamicamente o modelo de preços usado nas reservas
Em um mesmo projeto, você pode ter atividades diferentes que rodam melhor (ou custam menos) com Editions ou on-demand.
Por exemplo:
- Consultas interativas acontecem principalmente em dias úteis, no horário comercial
- Alta concorrência de consultas com tempos de resposta rápidos
- Tarefas específicas agendadas para rodar à noite ou nos fins de semana
Nesse caso, o ideal seria usar on-demand no horário comercial para garantir baixa latência e alta concorrência, e fora do horário comercial usar o ‘Enterprise Edition’ com no máximo 100 slots.
Um dos nossos especialistas em BigQuery, Nadav Weissman, mostra o passo a passo para automatizar mudanças de reserva e atribuição com esse propósito aqui.
Boas práticas para dbt, Dataform e ferramentas de BI
dbt e Dataform
Em primeiro lugar, é bem provável que você queira usar preço on-demand para os jobs de dbt ou Dataform. O dbt é pesado em processamento/slots, e na maioria das vezes o on-demand sai melhor — ou, no mínimo, é importante ficar de olho nas configurações de slots baseline/máximos se estiver usando Editions.
O dbt é pesado em processamento/slots, e muitas vezes você se sai melhor com o on-demand — ou definindo números realistas de slots na configuração baseline/máxima do autoscaler.
Tanto no dbt (Incremental models) quanto no Dataform (incremental tables), dá para processar dados novos/alterados em vez de reprocessar o dataset inteiro. Isso reduz o volume de dados processados, otimizando o uso de slots e os custos.
Por fim, vale considerar tirar do BigQuery os jobs de transformação do dbt/Dataform e movê-los para serviços com processamento mais barato, já que transformações são pesadas em computação.
Por exemplo, sai bem mais barato rodar as transformações em uma VM ou instância do Cloud SQL e depois carregar os dados transformados de volta no Google Cloud Storage, de onde serão carregados de volta no BigQuery já transformados. Isso exige um certo trabalho de orquestração de dados, mas já vimos clientes reduzirem jobs de transformação de US$ 50 para US$ 2 a 3 com esse método.
Ferramentas de BI
Se você usa uma ferramenta de BI como Looker ou Tableau com o BigQuery, principalmente para operações de leitura e agregação de dados ao longo do tempo, vale dar uma olhada no BI Engine.
O BI Engine é perfeito para consultas de dashboard, porque faz cache inteligente dos dados do BigQuery em memória, deixando as consultas mais rápidas. E como o cache é em memória, o estágio da consulta que lê os dados da tabela é gratuito. Em vez disso, você só paga pela capacidade de memória reservada.
Vale notar que, para usar o BI Engine, o projeto precisa estar no Enterprise Edition. Mas se você isolar seus workloads de BI em um projeto próprio, o modelo por slot-hour não vai te impactar tanto (supondo que você esteja fazendo principalmente operações de leitura), considerando o preço do BI Engine.
Se você também transforma muitos dados nos workloads de BI, isso é menos relevante para o seu caso, já que existem algumas limitações em torno de JOINs.
Outra alternativa é usar uma solução de "preço fixo", como o ClickHouse, que sua ferramenta de BI vai consultar no lugar do BigQuery, seja para ganhar desempenho ou para reduzir custos na fatura do BigQuery. A vantagem é pagar uma taxa fixa pelo datastore, em vez de uma taxa por consulta como acontece no BigQuery.
Conclusão
Estejam seus commitments flat-rate do BigQuery expirando ou não, este post traz um guia para te ajudar a escolher o melhor modelo de preços para seus workloads e o trabalho que talvez seja preciso fazer antes para garantir que você não está gastando demais.
Também reunimos dicas para otimizar os custos do BigQuery, como particionar e clusterizar tabelas, configurar os slots baseline e máximos do jeito certo, e usar o BI Engine para workloads de BI. Seguindo essas recomendações, dá para usar o BigQuery da forma mais econômica possível.
Se quiser revisar seu uso do BigQuery com um especialista em BigQuery da DoiT, agende uma conversa com a gente hoje mesmo!