Te explicamos cómo migrar sin fricciones tus commitments flat-rate de BigQuery que están por vencer a otro plan de precios, y cómo mantener tu uso optimizado después. En concreto, vemos qué tipos de workloads rinden mejor en Editions vs. precios on-demand y cómo mantener tus workloads optimizados tras dejar atrás el flat-rate (o en general).

Cuando se anunciaron las BigQuery Editions a finales de marzo del año pasado, las empresas tuvieron hasta el 5 de julio de 2023 para tomar una decisión por cada uno de sus proyectos:
- Migrar a Editions
- Seguir (o pasarse) a precios on-demand, que subieron un 25%
- Comprar un commitment anual flat-rate para seguir con flat-rate un año más
Muchos optaron por commitments flat-rate de 1 año para darse tiempo de rediseñar sus workloads de BigQuery y entender mejor el nuevo autoscaler, las métricas de slot-hour y Editions en general.
Si te suena familiar, tienes una decisión importante por delante —con enormes implicaciones de costo— a medida que tus commitments flat-rate empiezan a vencer: pasarte a Editions o irte a on-demand.
Por eso vamos a explicarte cómo migrar sin fricciones tus commitments flat-rate de BigQuery que están por vencer a otro plan de precios, y cómo mantener tu uso optimizado después.
En concreto, veremos:
- Qué tipos de workloads rinden mejor en Editions vs. precios on-demand
- Cómo mantener tus workloads optimizados después de dejar atrás el flat-rate (o en general)
También tratamos este tema en nuestro podcast Cloud Masters, por si prefieres escuchar o ver en lugar de leer:

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Cómo dejar atrás tu commitment flat-rate por vencer
Si no tomas una decisión antes de que venza tu commitment flat-rate, tu proyecto se convertirá automáticamente en una reserva de Enterprise Edition, con los baseline y max slots fijados al número de slots que habías comprometido antes.
Y como los jobs en Enterprise Edition te costarán aproximadamente 2.53x más por slot usado vs. flat-rate, conviene definir de antemano si Enterprise Edition —o Editions en general— tiene sentido para tu workload.
Sin embargo, no es del todo evidente cuál plan de precios te conviene.
Por qué la respuesta a qué modelo de precios de BigQuery te conviene es "depende".
Antes de entrar en las situaciones generales en las que cada modelo de precios funciona mejor, repasemos un par de cosas que conviene saber sobre cada modelo y cómo evaluarlos.
On-demand
Optar por on-demand te dará más capacidad de cómputo a mejor precio que cualquier Edition.
El detalle es que, como se factura según los datos procesados o escaneados, los jobs que escanean grandes volúmenes de datos pueden salir más caros en on-demand. Además, el tope es de 2,000 slots.
BigQuery Editions
Con BigQuery Editions, se factura por slot-hora según los slots asignados, no los usados. Esto es clave a la hora de usar el autoscaler de slots que viene con Editions.
Quizá durante tu etapa flat-rate notaste que necesitabas más slots de los comprometidos en ciertos momentos del día. En ese caso, el autoscaler puede inclinar la balanza hacia Editions.
Pero hay que tener cuidado: el autoscaler escala en bloques de 100 slots, durante un mínimo de 60 segundos. Esto te expone a la pérdida de slots o a sobregastar en ellos.
Por ejemplo, si tienes un job que necesita 101 slots, el autoscaler escalará a 200, lo que te obliga a pagar 99 slots que no necesitabas.
O podrías tener un job que requiere 200 slots durante apenas seis segundos. En ese caso, terminarías pagando esos 200 slots durante 54 segundos más de los que realmente los necesitabas.
Regla práctica para elegir el modelo de precios correcto
Tendrás que comparar cuántos slots usa tu job vs. los datos que escanea para determinar si sale más barato en on-demand o en Editions. También conviene tener en cuenta las necesidades de velocidad y rendimiento.
Por ejemplo, podrías estar ejecutando muchos jobs de análisis estadístico intensivos en cómputo y ligeros en slots (agregaciones, k-means, etc.). Si escaneas 1 TB de datos cada vez para correr este job, te costará $6.25 en on-demand. En cambio, si lo pones en Standard Edition y le dedicas 100 slots, podría costarte solo $2.00.
Multiplica esto por la cantidad de veces que ejecutas el job y verás una diferencia significativa entre ambos modelos de precios.
Quizá los jobs tarden más en correr en Editions, pero tal vez la diferencia de costo del 68% lo justifique.
Tendrás que decidirlo workload por workload.

¿Qué workloads se adaptan mejor a BigQuery Editions?
En general, los workloads de larga duración con muy pocos picos encajan muy bien en Editions. Mejor aún si esos workloads leen grandes volúmenes de datos. Esto se debe a que el autoscaler de BigQuery puede ser agresivo cuando se trata de workloads con picos.
Por ejemplo, imagina un proyecto que ejecuta un job de BigQuery intensivo en slots a una hora específica del día.
Si lo corres en Editions, los slots usados se dispararán mientras el job está en ejecución (y los slots adicionales más allá de los que necesitas también se facturan, durante un mínimo de un minuto), lo que se traduce en cargos imprevisibles durante los periodos de pico.
En cambio, cuando tienes workloads de BigQuery consistentes pero significativos, comprar slots vía los modelos de precios de Editions suele ser más barato que el on-demand y te garantiza disponibilidad consistente de tus recursos de cómputo de BigQuery a un precio predecible que puedes planificar.
Ejemplos típicos: jobs de analítica regulares y de larga duración, o una tarea de machine learning que procesa muchísimos datos durante horas.
¿Qué workloads se adaptan mejor a los precios on-demand de BigQuery?
Por otro lado, si manejas workloads con picos o esporádicos —ráfagas cortas de procesamiento intenso seguidas de largos periodos de inactividad— el on-demand suele ser la mejor opción.
Esto suele verse en proyectos de dev/test o en workloads de BI. En esos casos, suele convenir pagar por los bytes procesados, ya que el costo de correr esos workloads suele ser mucho menor que pagar incluso por una pequeña reserva de BQ Editions.
Además, considera los jobs que no procesan datos pero igual usan slots. Los refrescos de metadatos de BigLake, donde el esquema de la tabla se refresca y recarga sin procesamiento real de datos, son un ejemplo claro. Si ese job estuviera en un proyecto con precios de Editions, pagarías por los slots escalados (no usados). En cambio, pagas $0 si está en un proyecto con precios on-demand.
Divide tus workloads para optimizar los costos de BigQuery
Cuando se trata de los precios de BigQuery, no existe un enfoque único para todos.
Como puedes usar distintos modelos de precios de BigQuery en distintos proyectos, primero conviene asegurarte de que tus workloads estén separados en proyectos dedicados, y no agrupados en un solo proyecto.
Colocar distintos tipos de workload en proyectos diferentes —y usar distintos tiers de precios de BigQuery en cada uno— es una excelente forma de reducir tus costos de BigQuery, porque facilita asignar el plan de precios correcto a cada workload.
Si tus workloads aún no están aislados en proyectos distintos, conviene hacerlo primero, antes de
Por ejemplo:
- Los workloads de ETL y ELT deberían estar en un proyecto separado de tus workloads de I+D
- Los workloads cortos y con picos deberían ir en un proyecto que use precios on-demand
Si la mayoría de tus workloads están en un proyecto principal, quizá te preocupe que dividirlo sea demasiado complicado. Habrá cambios de configuración que considerar —podrías tener que ajustar tus macros si usas dbt, por ejemplo. Pero piensa en las consecuencias de no separar tus workloads de BigQuery en proyectos distintos.
Imagina una empresa con sus jobs diarios de pipeline de datos en el mismo proyecto que jobs ad-hoc de análisis exploratorio de datos. Si el proyecto usaba una BigQuery Edition, estaría sobregastando en las consultas ad-hoc; y al revés si el proyecto usara precios on-demand.
Cómo calcular qué tier de precios de BigQuery es mejor para tu workload
Los expertos en BigQuery de DoiT desarrollaron un script para ayudarte a saber qué modelo de precios tiene sentido para cada uno de tus workloads (es decir, proyectos).
Funciona analizando cada query ejecutada en un proyecto, durante un periodo que tú defines, y devuelve una recomendación de modelo de precios (on-demand o una Edition específica).
Aquí van otros scripts desarrollados por nuestro equipo que pueden serte útiles:
- Queries más complejas (definidas por uso promedio de slots durante el job).
- Queries más costosas, de mayor a menor costo
- Información general de los jobs
- Si te conviene cambiarte a Physical Storage o quedarte en logical storage
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Cómo mantener optimizados tus costos de BigQuery
Una vez que hayas determinado qué modelo de precios encaja con cada uno de tus workloads, querrás asegurarte de que tus costos sigan optimizados de aquí en adelante. En esta sección repasaremos varios consejos —algunos ya conocidos, otros nuevos con la llegada de Editions— que te ayudarán a no sobregastar en BigQuery.
Particiona y clusteriza tus tablas para reducir los datos procesados
Reducir los bytes procesados en tus queries mejorará el rendimiento de tus consultas y bajará tus costos de BigQuery en cualquiera de los modelos de precios — y particionar y/o clusterizar tus tablas es una excelente forma de hacerlo.
En los proyectos que usan precios on-demand, esto reducirá directamente tus costos de análisis, ya que pagas según los datos que escaneas.
Y con BigQuery Editions, mientras más datos necesite procesar una query, más slots se asignan. Así que aunque BigQuery Editions se cobre por slot-horas, reducir los bytes procesados puede llevar indirectamente a que se necesiten menos slots.
Clusterizar tablas en BigQuery
El clustering mejora el rendimiento de tus queries organizando la tabla en bloques de datos, según la(s) columna(s) por las que clusterizas. Esto facilita que BigQuery escanee solo los bloques de datos relevantes.
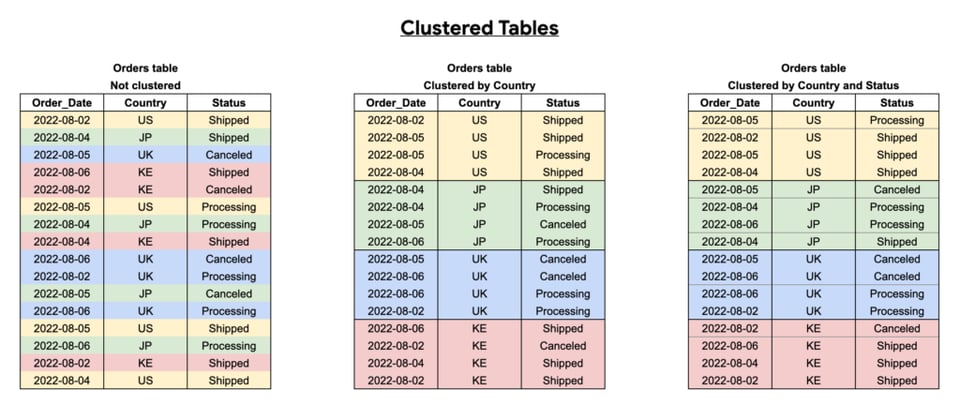
Conviene clusterizar las tablas por columnas que se consulten con frecuencia, sobre todo cuando esas columnas contengan muchos valores distintos.
Como se ve a continuación, la efectividad del clustering depende de qué columnas selecciones, el orden que elijas y de cómo estructures tus queries.
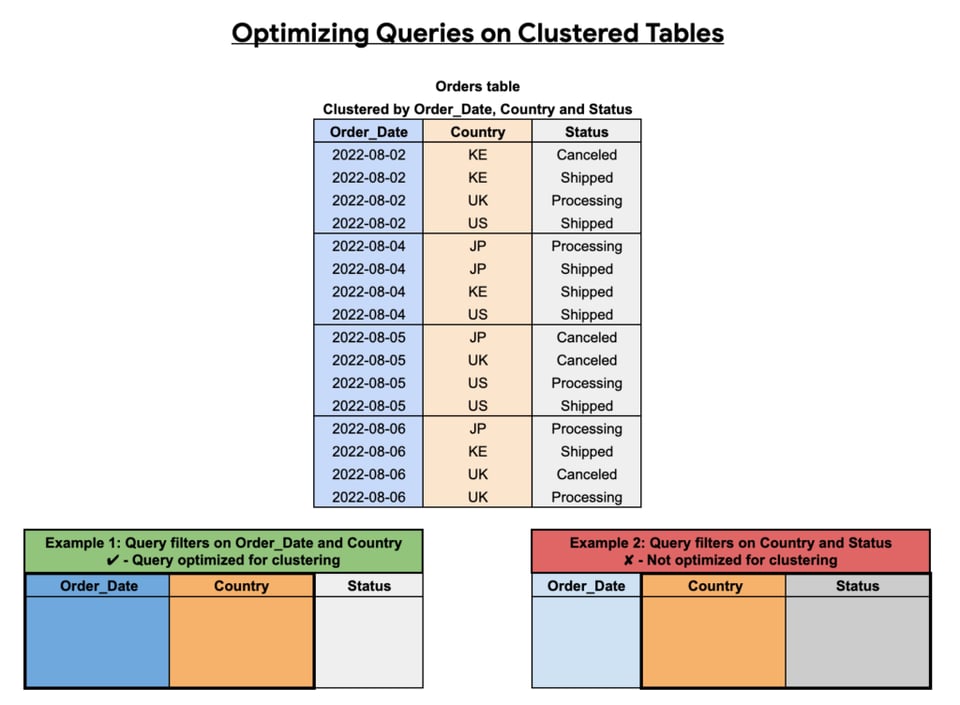
Particionar tablas en BigQuery
Particionar tablas ayuda a controlar costos al dividir una tabla grande en porciones más pequeñas, lo que te permite consultar un subconjunto reducido de la tabla.
Pero ten en cuenta que particionar una tabla no te servirá si no especificas las particiones que quieres escanear en tus queries, lo que se conoce como partition pruning.
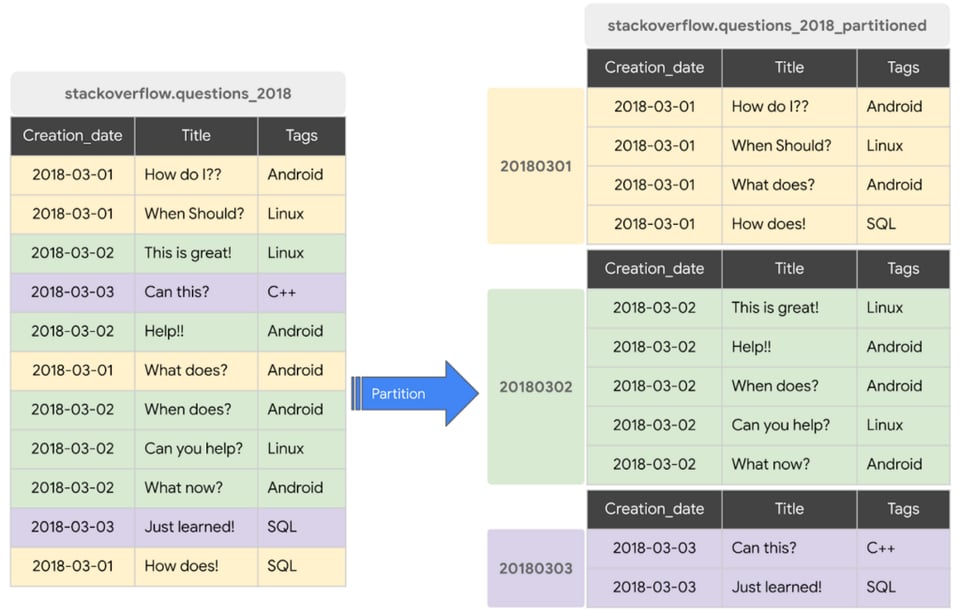
Una query de ejemplo que use una partición para la captura anterior sería:
SELECT * FROM stackoverflow_questions_2018 WHERE creation_date BETWEEN ‘2018-01-01’ AND ‘2018-01-31’Una query de ejemplo que NO usaría partición sería:
SELECT * FROM stackoverflow_questions_2018Si bien deberías particionar tus tablas en general, hazlo especialmente si tienes dashboards de BI corriendo sobre BigQuery, porque implementar particiones de tabla hará que tus dashboards sean más rápidos y tus queries más baratas.
Cómo identificar qué tablas clusterizar o particionar
En general, conviene particionar tablas grandes (>100 GB) cuando las queries sobre esas tablas filtran frecuentemente por campos de fecha/hora.
Usa clustering cuando tus queries suelen filtrar o agregar datos por columnas específicas. Para definir por qué campo(s) clusterizar una tabla (y en qué orden), revisa las columnas más usadas en cláusulas WHERE o GROUP BY —y en menor medida en cláusulas ORDER BY— de tus queries. El orden en que elijas estas columnas afectará cómo BigQuery ordena los datos, así que prioriza primero las columnas de filtro/agregación más usadas.
Pero si usas DoiT Cloud Navigator, puedes acceder a BigQuery Lens, que te mostrará recomendaciones sobre qué tablas clusterizar o particionar — y por qué columna(s) hacerlo.
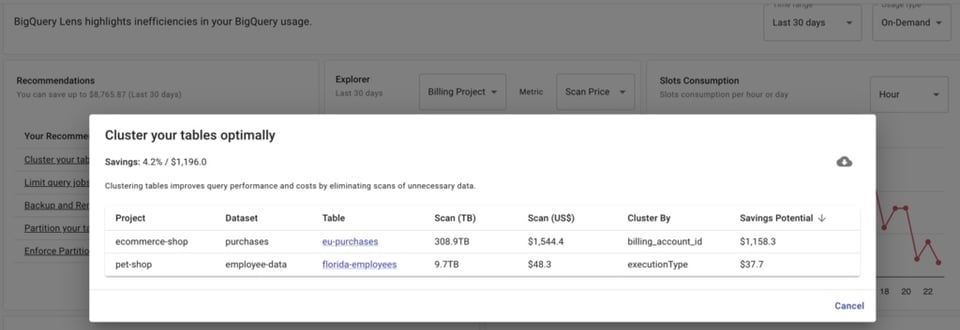
Sin embargo, incluso si ya particionaste tus tablas, aún tienes que asegurarte de que esas tablas se estén consultando usando el campo por el que están particionadas. Eso te da más control sobre los costos al escanear porciones más pequeñas de la tabla, en vez de la tabla entera.
Pero al gestionar un equipo de analistas de datos, es difícil saber si todos están realmente incluyendo el campo particionado en sus queries.
BigQuery Lens identifica los jobs que consultan tablas particionadas en los que el campo particionado no se está utilizando.
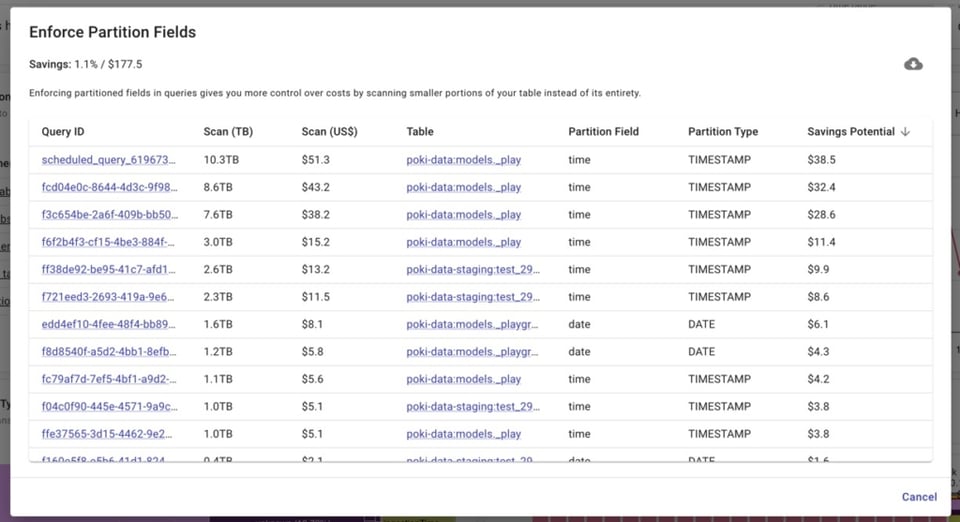
Configurar correctamente tus baseline y max slots
Si ya estás usando BigQuery Editions o planeas migrar, saber cómo configurar correctamente tus baseline y max slots es clave para sacarle provecho al autoscaler de BigQuery.
Consejos para la configuración de tus baseline slots
Tus baseline slots son básicamente el número mínimo de slots que quieres tener siempre disponibles para tus queries. Al configurarlos, recuerda que se te factura por baseline slots las 24/7.
Si tienes workloads consistentes y constantes corriendo a lo largo del día, fija un baseline más alto para evitar "cold starts" y colas.
Para workloads con picos o ráfagas, quizá te convenga un baseline bajo o incluso en 0 para no pagar por slots no utilizados. Pero ten en cuenta que el autoscaler tarda unos segundos en escalar de 0 a X slots. Tomará tiempo escalar para el primer job, y si ese job sigue corriendo cuando arranca otro, también tomará tiempo volver a escalar.
Consejos para la configuración de tus max slots
El límite de max slots establece el número máximo de slots a los que BigQuery puede escalar automáticamente para tus workloads. Configurar el máximo correctamente es importante para controlar costos y evitar que el auto-scaler aprovisione slots de más.
Analiza tus patrones históricos de uso de slots (con los scripts que mencionamos antes) para fijar un máximo razonable que aguante las cargas pico sin sobreaprovisionar de más.
Ajustar dinámicamente el modelo de precios de tus reservas
Dentro de un mismo proyecto puedes tener distintas actividades que rinden mejor (o cuestan menos) con Editions o con on-demand.
Por ejemplo:
- Las queries interactivas ocurren principalmente en días hábiles durante el horario laboral
- Alta concurrencia de queries con tiempos de respuesta rápidos
- Tareas concretas programadas para correr de noche o los fines de semana
En este caso, lo ideal sería usar on-demand durante las horas laborales para una latencia eficiente y alta concurrencia, y durante las horas no laborales usar la 'Enterprise Edition' con un máximo de 100 slots.
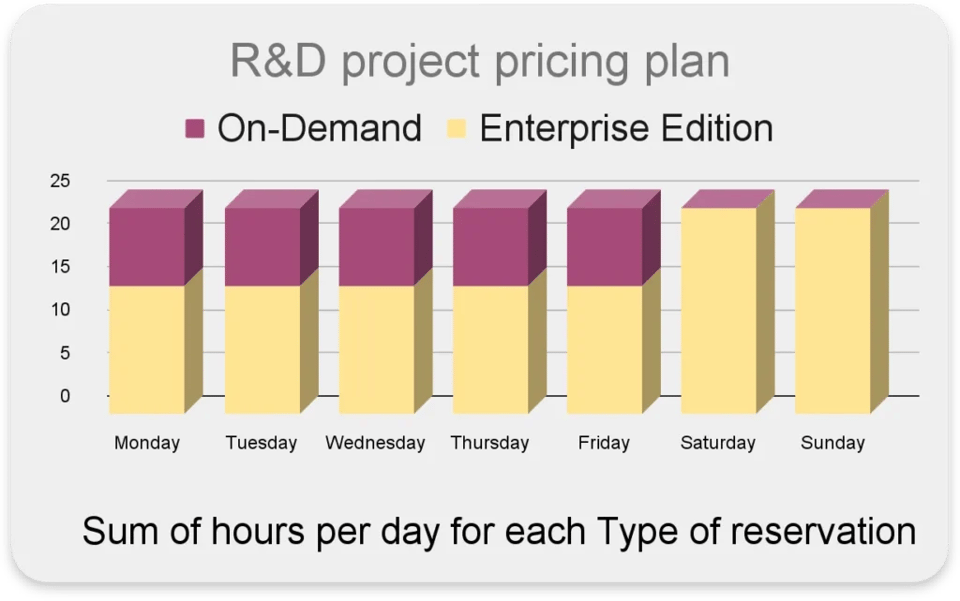
Uno de nuestros expertos en BigQuery, Nadav Weissman, explica paso a paso cómo automatizar los cambios de reservas y asignaciones para este caso aquí.
Buenas prácticas para dbt, Dataform y herramientas de BI
dbt y Dataform
Lo más probable es que quieras usar precios on-demand para tus jobs de dbt o Dataform. dbt es intensivo en cómputo/slots, y muchas veces te conviene más el on-demand — o al menos vigilar tu configuración de baseline/max slots si usas Editions.
dbt es intensivo en cómputo/slots, y muchas veces te conviene más el on-demand — o configurar cantidades realistas de slots en tu baseline/max para el autoscaler.
Tanto en dbt (Incremental models) como en Dataform (incremental tables), puedes procesar solo los datos nuevos o modificados en lugar de reprocesar el dataset completo. Esto reduce la cantidad de datos procesados y optimiza el uso de slots y los costos.
Por último, podrías ahorrar en costos si sacas los jobs de transformación de dbt/Dataform de BigQuery hacia servicios con cómputo más barato, ya que las transformaciones consumen mucho cómputo.
Por ejemplo, sería bastante más barato correr las transformaciones en una VM o instancia de Cloud SQL y luego cargar los datos transformados de vuelta en Google Cloud Storage, desde donde se cargan en BigQuery ya transformados. Si bien esto requiere algo de orquestación de datos por tu parte, hemos visto a clientes reducir jobs de transformación de $50 a $2-3 con este método.
Herramientas de BI
Si usas una herramienta de BI como Looker o Tableau con BigQuery principalmente para operaciones de lectura y agregación de datos en el tiempo, échale un vistazo a BI Engine.
BI Engine es ideal para queries de dashboard porque cachea inteligentemente los datos de BigQuery en memoria, lo que se traduce en queries más rápidas. Y como BI Engine cachea los datos en memoria, la etapa de la query que lee los datos de la tabla es gratis. Solo pagas por la capacidad de memoria reservada.
Ten en cuenta que para usar BI Engine tu proyecto necesita estar en Enterprise Edition. Pero si aíslas tus workloads de BI en su propio proyecto, el modelo de precios por slot-hora no te pegará tanto (asumiendo que ejecutas mayormente operaciones de lectura), dada la estructura de precios de BI Engine antes mencionada.
Si además transformas mucho los datos en tus workloads de BI, esto es menos relevante para ti, ya que existen algunas limitaciones en los JOINs.
Otro enfoque es usar una solución de "precio fijo" como ClickHouse, a la que tu herramienta de BI consulte en lugar de BigQuery, ya sea para mejorar el rendimiento o reducir los costos en tu factura de BigQuery. La ventaja es que pagas un precio plano por el datastore en vez de un costo por query como en BigQuery.
Conclusión
Estén o no por vencer tus commitments flat-rate de BigQuery, este artículo te entrega una guía para elegir el mejor modelo de precios para tus workloads y el trabajo previo que conviene hacer para asegurarte de no sobregastar.
También te dejamos consejos para optimizar tus costos de BigQuery: particionar y clusterizar tablas, configurar correctamente tus baseline y max slots, y usar BI Engine para workloads de BI. Siguiendo estas recomendaciones, puedes asegurarte de estar usando BigQuery de la forma más eficiente en costos posible.
Si quieres revisar tu uso de BigQuery con un especialista en BigQuery de DoiT, ¡agenda una consultoría con nosotros hoy!