期限切れが近づくBigQueryの定額コミットメントを、別の料金プランへスムーズに乗り換え、その後も利用を最適に保つための方法をご紹介します。具体的には、Editionsとオンデマンド料金それぞれに向くworkloadsの種類、そして定額制からの移行後(あるいは普段から)workloadsを最適化し続けるコツを取り上げます。

BigQuery Editionsが昨年3月下旬に発表された際、各企業はプロジェクトごとに2023年7月5日までに次のいずれかを選択する必要がありました。
- Editionsへ切り替える
- 25%値上げされたオンデマンド料金を継続利用(または切り替え)する
- 年間定額コミットメントを購入し、もう1年間定額制を続ける
多くの企業は、BigQueryのworkloadsを再設計し、新しいオートスケーラーやスロット時間メトリクス、Editions全般を理解するための猶予期間として、1年間の定額コミットメントを選びました。
もし当てはまる場合、定額コミットメントの期限が迫るにつれ、コストへの影響が大きい重要な判断——Editionsへ切り替えるか、オンデマンドへ移行するか——を下す必要があります。
そこで本記事では、期限切れが近いBigQueryの定額コミットメントを別の料金プランへスムーズに移行し、その後も利用を最適に保つ方法を解説します。
具体的に取り上げるのは次の2点です。
- Editionsとオンデマンド料金、それぞれに向くworkloadsの種類
- 定額制からの移行_後_(あるいは普段から)workloadsを最適化し続ける方法
本テーマはCloud Mastersポッドキャストでも取り上げています。読むより聞く・観る方が好みの方はこちらをどうぞ。

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
期限切れの定額コミットメントから移行する
定額コミットメントの期限切れまでに何も決定_しなかった_場合、プロジェクトは自動的にEnterprise Editionの予約に変換され、ベースラインと最大スロット数は以前コミットしていたスロット数に設定されます。
Enterprise Editionでのジョブは定額制と比べてスロット使用あたり約2.53倍のコストがかかるため、Enterprise Edition——あるいはEditions全般——が自社のworkloadに合うかどうかを事前に見極めておくことが重要です。
とはいえ、どの料金プランが最適かは一概には言えません。
BigQueryの最適な料金モデルが「ケースバイケース」になる理由
各料金モデルが向くシーンを見ていく前に、それぞれのモデルについて押さえておきたいポイントと評価の観点を確認しておきましょう。
オンデマンド
オンデマンドを選べば、どのEditionよりもお得な価格で、より多くのコンピューティング能力が手に入ります。
ただし、処理またはスキャンしたデータ量に応じて課金されるため、大量データをスキャンするジョブはオンデマンドの方が割高になる場合があります。さらに、スロット数の上限は2,000です。
BigQuery Editions
BigQuery Editionsでは、使用したスロットではなく_割り当てられた_スロットに対してスロット時間単位で課金されます。Editionsに付属するスロットオートスケーラーを使う際には、必ず押さえておきたいポイントです。
定額制を利用していたとき、1日のうち特定の時間帯にコミット数を超えるスロットが必要になった経験はないでしょうか。そうしたケースでは、オートスケーラーがEditionsを選ぶ決め手になるかもしれません。
ただし注意したいのは、オートスケーラーが100スロット単位、最低60秒間でスケールするという点です。これがスロットの無駄遣いや過剰支出を招くリスクになります。
たとえば101スロット必要なジョブがある場合、オートスケーラーは200スロットまでスケールするため、不要な99スロット分まで支払うことになります。
あるいは、200スロットがわずか6秒だけ必要なジョブの場合、必要のない54秒分も含めて200スロット分の料金を支払うことになります。
適切な料金モデルを選ぶための目安
ジョブがオンデマンドとEditionsのどちらで安く済むかを判断するには、ジョブが使用するスロット数とスキャンするデータ量を比較する必要があります。加えて、速度・パフォーマンス面の要件も考慮しましょう。
たとえば、コンピューティング負荷が高くスロット負荷の軽い統計分析ジョブ(集計、k-meansなど)を多数実行しているケースを考えてみましょう。このジョブで毎回1 TBのデータをスキャンするなら、オンデマンドでは$6.25かかります。一方、Standard Editionで100スロットを専有させて実行すれば、$2.00程度で済むかもしれません。
これにジョブの実行回数を掛け合わせれば、両料金モデルの差はかなり大きなものになります。
Editionsではジョブの実行に時間がかかるかもしれませんが、68%ものコスト差はそれだけの価値があると判断できる場合もあるでしょう。
結局のところ、workloadごとに判断していく必要があります。

BigQuery Editionsに向くworkloadsとは?
一般に、スパイクがほとんどない長時間稼働のworkloadsはEditionsと相性が良く、さらに大量のデータを読み込むケースであれば最適です。BigQueryのオートスケーラーはスパイク的なworkloadsに対して積極的にスケールしがちなため、安定稼働のworkloadsの方が無駄なく運用できるからです。
たとえば、1日の特定の時間帯にスロット負荷の高いBigQueryジョブを実行するプロジェクトを思い浮かべてみてください。
これをEditionsで実行すると、ジョブ稼働中にスロット使用量が急増し(必要以上のスロットも最低1分間は課金対象)、スパイク時の料金が読みづらくなります。
一方、安定的でありながら相応の規模があるBigQueryのworkloadsの場合、Editions料金モデルでスロットを購入する方がオンデマンド料金より安く済むケースが多く、計画しやすい予測可能な価格で、BigQueryのコンピューティングリソースを安定的に確保できます。
こうしたworkloadsの例としては、長時間稼働する定例の分析ジョブや、大量の数値計算を伴い数時間連続で稼働する機械学習タスクなどが挙げられます。
BigQueryのオンデマンド料金に向くworkloadsとは?
一方で、スパイク的・散発的なworkloads——短時間の集中処理と長い非稼働時間が交互に発生するタイプ——を扱う場合は、オンデマンド料金の方が適していることが多いです。
これは開発・テスト用プロジェクトやBI関連のworkloadsでよく見られます。こうしたケースでは処理バイト数に対して支払う方が理にかなっており、小規模なBQ Editions予約を購入するよりはるかに安く済むことも珍しくありません。
さらに、データを処理しないものの、スロットを使用するジョブも見落とさないようにしましょう。実データを処理せずテーブルスキーマをリフレッシュ・再読み込みするBigLakeのメタデータ更新はその代表例です。このジョブがEditions料金のプロジェクトにあれば、(使用ではなく)_スケールされた_スロット分の料金が発生します。一方、オンデマンド料金のプロジェクトなら$0で済みます。
workloadsを分けてBigQueryコストを最適化する
BigQueryの料金プランに、すべての用途に最適な「万能解」は存在しません。
BigQueryの料金モデルはプロジェクトごとに切り替えられるため、まずはworkloadsを単一のプロジェクトにまとめず、用途別に専用プロジェクトに分けることから始めましょう。
異なる種類のworkloadsを別々のプロジェクトに配置し、それぞれに適したBigQuery料金階層を使うことは、各workloadに最適なプランを当てはめやすくなるため、BigQueryコスト削減に大いに効果があります。
workloadsがまだ別々のプロジェクトに分かれていない場合は、まずこの整理から着手することをおすすめします。
たとえば次のような切り分けです。
- ETL/ELTのworkloadsは、R&Dのworkloadsとは別のプロジェクトに置く
- スパイク的で短時間稼働のworkloadsは、オンデマンド料金を利用するプロジェクトに置く
workloadsの大半が1つのメインプロジェクトに集まっている場合、プロジェクトを分割するのは大変だと感じるかもしれません。たとえばdbtを使っていればマクロの修正など、構成変更も必要になるでしょう。それでも、BigQueryのworkloadsを別プロジェクトに分割_しなかった_場合の影響を一度想像してみてください。
たとえば、日次のデータパイプラインジョブと、アドホックな探索的分析ジョブが同じプロジェクトに同居している企業があるとします。プロジェクトがBigQuery Editionを使っていればアドホッククエリで過剰支出が発生し、逆にオンデマンド料金ならパイプラインジョブ側で過剰支出が発生してしまいます。
workloadに最適なBigQuery料金階層を計算する
DoiTのBigQueryエキスパートは、各workloads(つまりプロジェクト)にどの料金モデルが適しているかを判断するのに役立つスクリプトを開発しました。
このスクリプトは、ユーザーが指定した期間内にプロジェクトで実行されたすべてのクエリを分析し、料金モデルの推奨(オンデマンドまたは特定のEdition)を返してくれます。
当社チームが開発した、その他に役立つスクリプトもいくつかご紹介します。
- 最も複雑なクエリ(ジョブ中の平均スロット使用量で定義)
- 最も高コストなクエリ(高コスト順)
- ジョブの一般情報
- 物理ストレージへの切り替え/論理ストレージ継続の判定
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
BigQueryコストを最適な状態に 保ち続ける 方法
各workloadに合う料金モデルを決めたら、次は今後もコストを最適な状態に保てるようにすることが大切です。本セクションでは、BigQueryで余計な支出を生まないために役立つヒントを——以前から知られているものから、Editions登場で生まれた新しいものまで——複数ご紹介します。
テーブルをパーティション化・クラスタリングして処理データ量を減らす
クエリで処理するバイト数を減らせば、どちらの料金モデルでもクエリのパフォーマンスが上がり、BigQueryコストの削減につながります。テーブルのパーティショニングやクラスタリングは、その有効な手段です。
オンデマンド料金のプロジェクトでは、スキャンしたデータ量に応じて課金されるため、分析コストの直接的な削減につながります。
BigQuery Editionsでも、クエリが処理するデータ量が多いほど割り当てられるスロットも増えます。Editionsはスロット時間ベースの料金体系ですが、処理バイト数を減らせば、必要なスロット数も間接的に減らせるのです。
BigQueryテーブルのクラスタリング
クラスタリングは、指定した列をキーにテーブルをデータブロック単位に整理することで、クエリパフォーマンスを向上させます。これにより、BigQueryは関連するブロックだけを効率的にスキャンできるようになります。
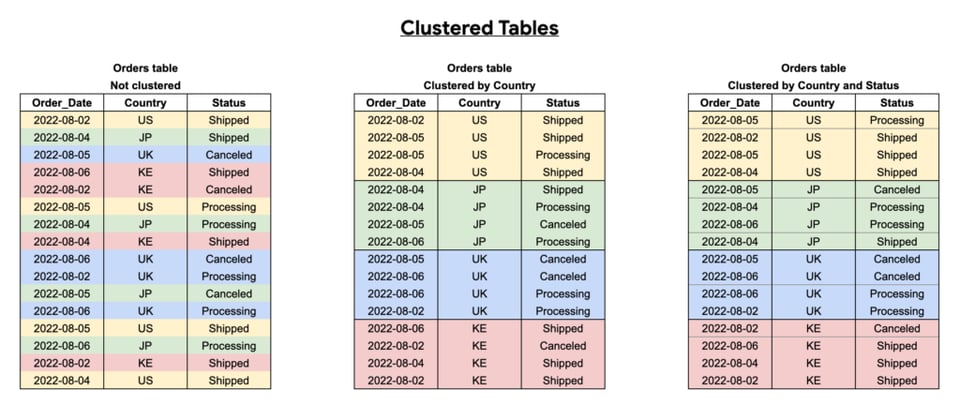
頻繁にクエリされる列、特にユニーク値が多い列をキーにテーブルをクラスタリングするのが効果的です。
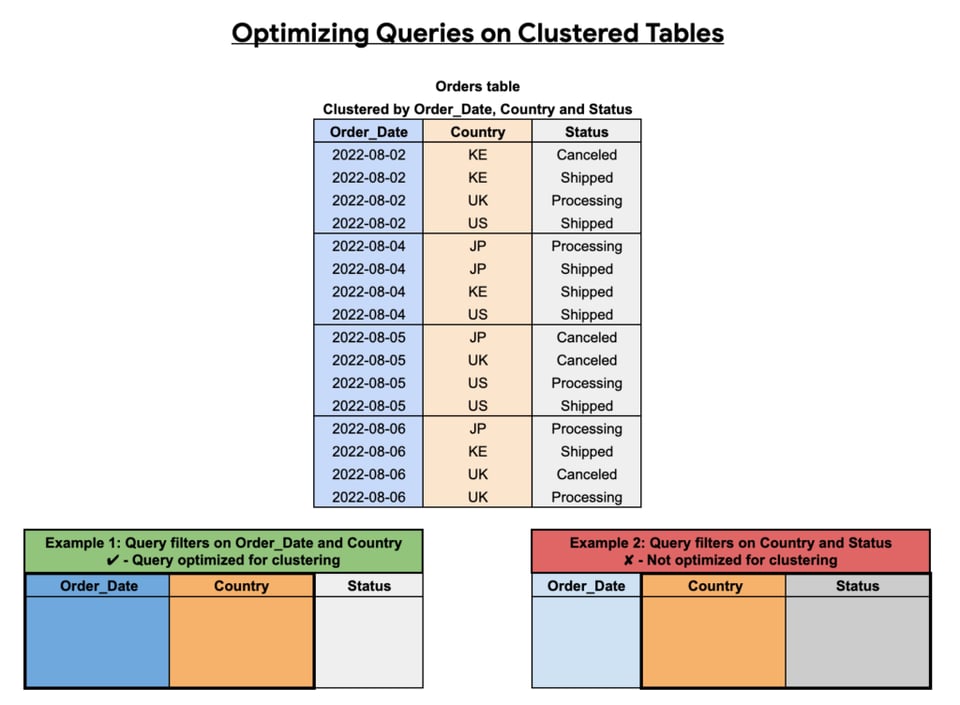
下図のとおり、クラスタリングの効果は、選ぶ列、その並び順、そしてクエリの書き方に大きく左右されます。
BigQueryテーブルのパーティショニング
パーティショニングは、大きなテーブルを小さな塊に分割することで、テーブルの一部のみをクエリ対象にでき、コスト管理に役立ちます。
ただし、クエリでスキャン対象のパーティションを指定しなければ、パーティショニングしてもメリットは得られません。これはパーティションプルーニングと呼ばれます。
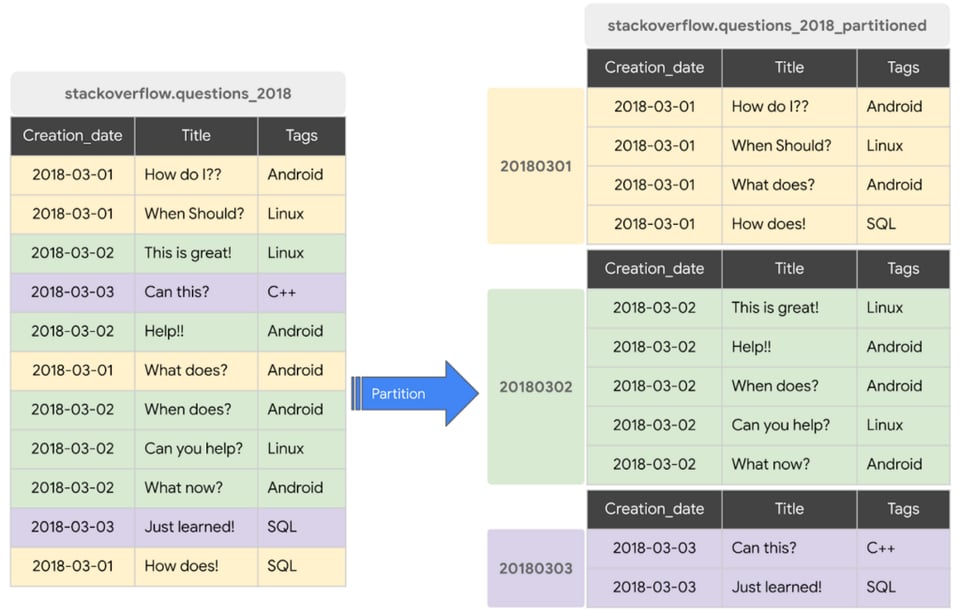
上記のスクリーンショットでパーティションを使用するクエリ例:
SELECT * FROM stackoverflow_questions_2018 WHERE creation_date BETWEEN ‘2018-01-01’ AND ‘2018-01-31’パーティションを使用しないクエリ例:
SELECT * FROM stackoverflow_questions_2018テーブルのパーティショニングは基本的に推奨されますが、特にBigQuery上で動作するBI連携のダッシュボードがある場合は_必ず_実施しましょう。テーブルパーティションを実装すれば、ダッシュボードが高速になり、クエリも安価になります。
クラスタリング・パーティショニング対象のテーブルを見極める
原則として、大規模(>100 GB)なテーブルで、クエリが日付・時刻フィールドで頻繁にフィルタされる場合はパーティショニングを行うべきです。
クエリで特定の列をもとにフィルタや集計を頻繁に行う場合は、クラスタリングを使いましょう。クラスタリングする列(およびその順序)を決めるには、クエリのWHERE句やGROUP BY句——限定的にはORDER BY句——で最も多く使われる列を確認します。列の並び順はBigQueryのデータソートに影響するため、最も使用頻度の高いフィルタ・集計列を先頭に置きましょう。
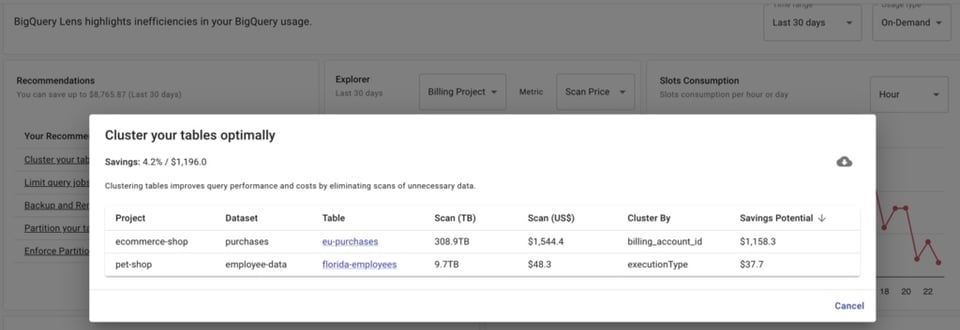
DoiT Cloud Navigatorを利用していれば、BigQuery Lensを使えます。BigQuery Lensは、どのテーブルをクラスタリング/パーティショニングすべきか、またどの列で行うべきかを推奨してくれます。
ただし、すでにテーブルをパーティショニング済みでも、クエリ実行時にパーティションフィールドが指定されているかを確認する必要があります。これにより、テーブル全体ではなく必要な部分のみをスキャンでき、コストをよりコントロールできます。
とはいえ、データアナリストのチームを率いる立場では、全員が実際にクエリでパーティションフィールドを指定しているかを把握するのは簡単ではありません。
BigQuery Lensは、パーティション化されたテーブルへのクエリのうち、パーティションフィールドが活用されていないジョブを自動的に特定します。
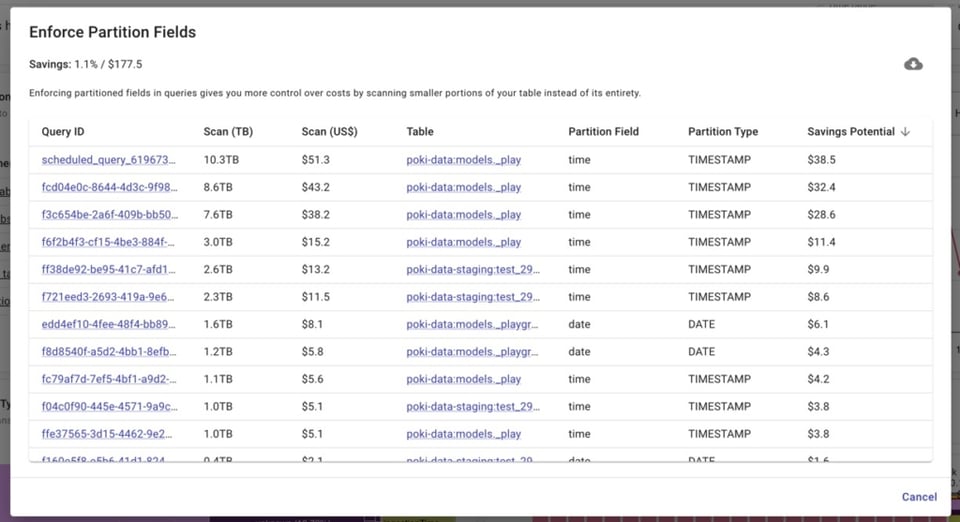
ベースラインと最大スロットを適切に設定する
すでにBigQuery Editionsを使っている、あるいは移行予定の方にとって、BigQueryのオートスケーラーを最大限活かすには、ベースラインと最大スロットを適切に設定する方法を理解しておくことが欠かせません。
ベースラインスロット設定のヒント
ベースラインスロットとは、要するにクエリのために_常時_確保しておきたい最小スロット数のことです。設定する際は、24時間365日課金される点を忘れないでください。
1日を通して安定したworkloadsが稼働している場合は、「コールドスタート」やキューイングを避けるためにベースラインを高めに設定しましょう。
スパイク的・バースト的なworkloadsの場合は、未使用スロットへの支払いを避けるためにベースラインを低め、あるいは0に設定するのがよいでしょう。ただし、オートスケーラーが0からXスロットへスケールアップするには数秒かかる点に注意が必要です。最初のジョブのスケールアップに時間がかかり、そのジョブの稼働中に別のジョブが開始された場合も、再度スケールアップに時間を要します。
最大スロット設定のヒント
最大スロット上限は、BigQueryがworkloadsに対して自動的にスケールアップできる最大スロット数です。最大値を適切に設定することは、コストを管理し、オートスケーラーによるスロットの過剰プロビジョニングを防ぐ上で重要です。
過去のスロット使用パターンを分析し(前述のスクリプトが役立ちます)、ピーク負荷に耐えつつ過剰プロビジョニングを避けられる、現実的な最大値を設定しましょう。
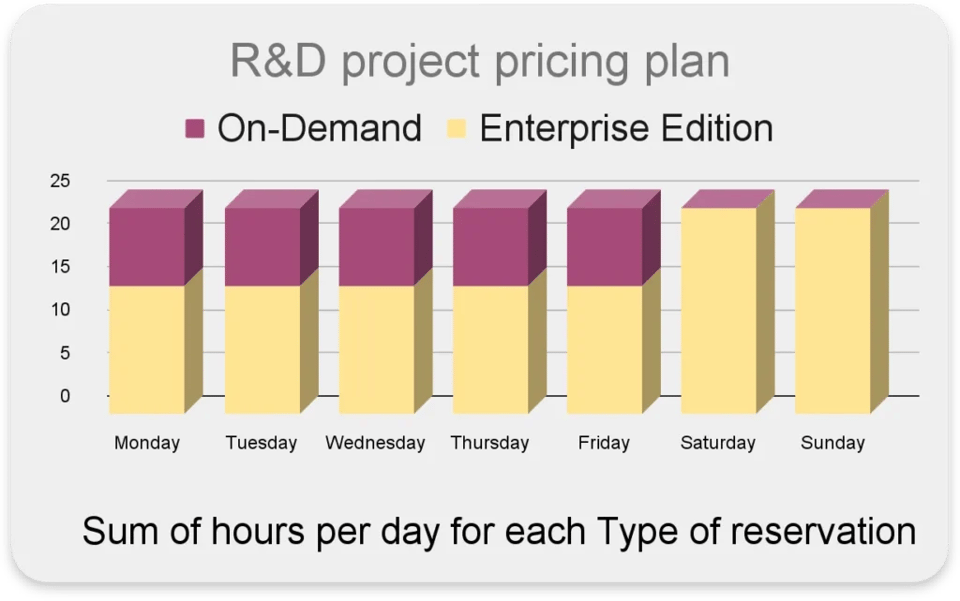
予約で使う料金モデルを動的に切り替える
1つのプロジェクト内でも、Editionsとオンデマンドのどちらかでパフォーマンスが高まる(あるいはコストが下がる)活動が混在しているケースがあります。
たとえば次のような状況です。
- インタラクティブなクエリは主に平日の業務時間中に発生する
- 同時クエリ数が多く、素早い応答時間が求められる
- 特定のタスクは夜間や週末に実行されるよう予約されている
こうした場合、業務時間中は効率的なクエリレイテンシと高い同時実行性のためにオンデマンドを使い、業務時間外は最大100スロットの「Enterprise Edition」を使うのが理想的です。
当社のBigQueryエキスパート、Nadav Weissmanが、こうした目的で予約と割り当ての変更を自動化する手順をこちらで詳しく解説しています。
dbt、Dataform、BIツールのベストプラクティス
dbtとDataform
まず、dbtやDataformのジョブにはオンデマンド料金が適していることが多いです。dbtはコンピューティング・スロット負荷が高く、オンデマンド料金の方が有利になる場面が多々あります。Editionsを使うなら、少なくともベースライン/最大スロット設定にはしっかり目を配る必要があります。
dbtはコンピューティング・スロット負荷が高いため、多くの場合はオンデマンド料金が有利です。Editionsを使う場合は、オートスケーラー向けにベースライン/最大スロットを現実的な値に設定しましょう。
dbt(Incremental models)とDataform(incremental tables)はいずれも、データセット全体を再処理せず、新規・変更データのみを処理する機能を備えています。これにより処理データ量が減り、スロット使用量とコストを最適化できます。
最後に、変換処理はコンピューティング負荷が高いため、dbt/Dataformの変換ジョブをBigQueryから、より安価なコンピューティングを提供するサービスにオフロードすることでコストメリットを得られる場合があります。
たとえば、VMやCloud SQLインスタンスで変換を実行し、変換済みデータをGoogle Cloud Storageに書き戻し、そこからBigQueryへ変換済みの状態でロードする方法は、はるかに安価に済みます。多少のデータオーケストレーション作業は必要ですが、この方法で$50の変換ジョブを$2〜3にまで削減した顧客もいます。
BIツール
LookerやTableauなどのBIツールでBigQueryを主に読み取り操作や時系列データの集計に使っているなら、BI Engineの活用を検討しましょう。
BI EngineはBigQueryのデータをインメモリで賢くキャッシュし、クエリを高速化するため、ダッシュボード用のクエリに最適です。インメモリでキャッシュされるため、テーブルデータを読み取るクエリ段階の料金は無料で、代わりに予約済みメモリ容量に対してのみ支払いが発生します。
BI Engineの利用にはプロジェクトでEnterprise Editionを使う必要がある点に注意してください。ただし、BIのworkloadsを独立したプロジェクトに分離してしまえば、上記のBI Engine料金体系を踏まえると、(主に読み取り操作を行っている前提では)スロット時間料金モデルの影響はそれほど大きくなりません。
BIのworkloads内でデータ変換も多く行っている場合は、JOINに関する制約があるため、これはあまり当てはまりません。
もう1つのアプローチは、BigQueryの代わりにBIツールがクエリする「定額制」のソリューション(たとえばClickHouse)を活用し、パフォーマンス向上やBigQueryの請求コスト削減を図る方法です。クエリ単位の課金ではなく、データストアに対して定額を支払う点がメリットです。
まとめ
定額制のBigQueryコミットメントが期限切れを迎えるかどうかにかかわらず、本記事はworkloadsに最適な料金モデルを選び、過剰支出を防ぐために事前に行うべき作業の指針となるはずです。
あわせて、テーブルのパーティショニングとクラスタリング、ベースラインと最大スロットの適切な設定、BIのworkloadsへのBI Engine活用など、BigQueryコスト最適化に役立つヒントもご紹介しました。これらを実践すれば、BigQueryを最も費用対効果の高い形で運用できます。
DoiTのBigQueryスペシャリストと一緒にBigQueryの利用状況を見直したい方は、ぜひ今すぐ無料相談を予約してください。