Come gestire senza intoppi la transizione dai commitment flat-rate BigQuery in scadenza verso un nuovo piano tariffario, mantenendo l'utilizzo ottimizzato. Nello specifico, vedremo quali tipi di workloads rendono di più con Editions rispetto al pricing on-demand e come tenere ottimizzati i workloads dopo aver lasciato il flat-rate (o più in generale).

Quando, alla fine di marzo dello scorso anno, sono state annunciate le BigQuery Editions, le aziende avevano tempo fino al 5 luglio 2023 per prendere una decisione su ciascuno dei propri progetti:
- Passare a Editions
- Continuare a usare (o passare a) il pricing on-demand, aumentato del 25%
- Acquistare un commitment flat-rate annuale per restare sul flat-rate per un altro anno
Molti hanno scelto di sottoscrivere commitment flat-rate annuali per concedersi un anno di tempo per riprogettare i propri workloads BigQuery e prendere confidenza con il nuovo autoscaler, con le metriche slot-hour e con Editions in generale.
Se è il Suo caso, ha davanti una decisione importante — con conseguenze rilevanti sui costi — da prendere mano a mano che i Suoi commit flat-rate iniziano a scadere: passare a Editions oppure all'on-demand.
Per questo Le spieghiamo come gestire senza intoppi la transizione dai commitment flat-rate BigQuery in scadenza verso un nuovo piano tariffario, mantenendo l'utilizzo ottimizzato.
Nello specifico vedremo:
- Quali tipi di workloads rendono di più con Editions rispetto al pricing on-demand
- Come tenere ottimizzati i workloads dopo il passaggio dal flat-rate (o più in generale)
Abbiamo trattato l'argomento anche nel nostro podcast Cloud Masters, se preferisce ascoltare o guardare invece di leggere:

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Come uscire dal commitment flat-rate in scadenza
Se non prende una decisione prima della scadenza del commitment flat-rate, il progetto viene convertito automaticamente in una reservation Enterprise Edition, con baseline e max slots impostati sul numero di slot precedentemente impegnato.
E poiché su Enterprise Edition i job costano circa 2,53 volte di più per slot utilizzato rispetto al flat-rate, è bene capire in anticipo se Enterprise Edition — o Editions in generale — sia la scelta giusta per il Suo workload.
Tuttavia, individuare il piano tariffario più adatto a Lei non è del tutto immediato.
Perché "dipende" qual è il modello di pricing BigQuery migliore per Lei.
Prima di entrare nelle situazioni tipiche in cui ciascun modello dà il meglio, ripassiamo alcuni aspetti chiave da conoscere e valutare per ognuno di essi.
On-demand
Optare per l'on-demand Le offre più capacità di calcolo a un prezzo migliore di qualsiasi Edition.
Tuttavia, dato che la fatturazione si basa sui dati elaborati o scansionati, i job che scansionano grandi volumi di dati possono risultare più costosi in modalità on-demand. Inoltre, è previsto un tetto massimo di 2.000 slot.
BigQuery Editions
Con BigQuery Editions, la fatturazione avviene per slot-hour sugli slot allocati, non su quelli effettivamente utilizzati. È un dettaglio importante da tenere a mente quando si usa l'autoscaler degli slot incluso in Editions.
Magari, mentre era in flat-rate, in alcune fasce orarie Le sono serviti più slot di quelli impegnati. In questo caso l'autoscaler potrebbe far pendere l'ago della bilancia verso Editions.
Ma occorre prestare attenzione: l'autoscaler scala a incrementi di 100 slot, per un minimo di 60 secondi. Questo La espone al rischio di sprecare slot o di spendere troppo.
Se ad esempio ha un job che richiede 101 slot, l'autoscaler La porta a 200, costringendoLa a pagare per 99 slot di cui non aveva bisogno.
Oppure può capitare di avere un job che richiede 200 slot per soli sei secondi: in tal caso pagherebbe 200 slot per 54 secondi in più rispetto al necessario.
Regola pratica per scegliere il modello di pricing giusto
Per capire se un job costa meno on-demand o su Editions, occorre confrontare quanti slot sta utilizzando con la quantità di dati scansionati. Conviene poi valutare anche le esigenze di velocità e performance.
Ad esempio, potrebbe eseguire molti job di analisi statistica compute-intensive ma poco esigenti in termini di slot (aggregazioni, k-means, ecc.). Se per ciascuna esecuzione scansiona 1 TB di dati, on-demand Le costerà 6,25 $. Se invece sposta lo stesso job su Standard Edition dedicandogli 100 slot, potrebbe pagare appena 2,00 $.
Moltiplichi il dato per il numero di esecuzioni del job e vedrà una differenza significativa tra i due modelli di pricing.
Su Editions i job potrebbero richiedere più tempo, ma forse il risparmio del 68% giustifica l'attesa.
La scelta va fatta workload per workload.

Quali workloads rendono di più con BigQuery Editions?
In linea generale, i workloads di lunga durata e con pochissimi picchi sono ideali per Editions. Ancora meglio se leggono grandi volumi di dati. Questo perché l'autoscaler di BigQuery può rivelarsi aggressivo di fronte a workloads con picchi.
Immagini ad esempio un progetto che esegue un job BigQuery slot-intensive in un orario specifico della giornata.
Se lo esegue su Editions, gli slot utilizzati subiranno un picco mentre il job è in corso (con la fatturazione anche degli slot eccedenti rispetto al fabbisogno reale, per un minimo di un minuto), generando imprevedibilità sui costi nei periodi di picco.
Quando invece i workloads BigQuery sono costanti ma significativi, acquistare slot tramite i modelli di pricing Editions risulta spesso più economico dell'on-demand e garantisce la disponibilità continua delle risorse di calcolo BigQuery a un prezzo prevedibile e pianificabile.
Esempi tipici: job di analytics ricorrenti e di lunga durata, oppure attività di machine learning che elaborano grandi quantità di numeri restando in esecuzione per ore.
Quali workloads rendono di più con il pricing on-demand di BigQuery?
Al contrario, se gestisce workloads con picchi o sporadici — brevi raffiche di elaborazione intensa seguite da lunghi periodi di inattività — il pricing on-demand è spesso la scelta migliore.
È il caso, ad esempio, di progetti di dev/test o di workloads BI. In questi scenari ha senso pagare per i byte elaborati, perché il costo di esecuzione di tali workloads sarà spesso di gran lunga inferiore al costo anche di una piccola reservation BQ Editions.
Consideri inoltre i job che non elaborano dati ma utilizzano comunque slot. Un esempio classico sono i refresh dei metadati BigLake, in cui lo schema della tabella viene aggiornato e ricaricato senza alcuna elaborazione effettiva di dati. Se questo job si trovasse in un progetto con pricing Editions, pagherebbe gli slot scalati (non utilizzati). In un progetto con pricing on-demand, invece, paga 0 $.
Suddivida i workloads per ottimizzare i costi BigQuery
Quando si parla di pricing BigQuery, non esiste un approccio "taglia unica".
Poiché può adottare modelli di pricing BigQuery diversi su progetti diversi, il primo passo è assicurarsi che i workloads siano suddivisi in progetti dedicati e non concentrati in un unico progetto.
Collocare tipologie diverse di workload in progetti diversi — utilizzando in ciascuno il livello di pricing BigQuery più adatto — è un ottimo modo per ridurre i costi BigQuery, perché rende più semplice abbinare il piano tariffario corretto a ogni workload.
Se i Suoi workloads non sono già isolati in progetti distinti, è opportuno farlo come primo passo.
Ad esempio:
- I workloads ETL ed ELT dovrebbero risiedere in un progetto separato rispetto ai workloads di R&D
- I workloads con picchi e di breve durata dovrebbero finire in un progetto che utilizza il pricing on-demand
Se la maggior parte dei Suoi workloads si concentra in un unico progetto principale, potrebbe temere che suddividerlo sia troppo complicato. Ci sono modifiche di configurazione da considerare — ad esempio potrebbe dover aggiornare le macro se utilizza dbt. Ma valuti le conseguenze del non suddividere i workloads BigQuery in progetti diversi.
Pensi a un'azienda con i job giornalieri della data pipeline nello stesso progetto dei job di analisi esplorativa ad-hoc. Se il progetto utilizzasse una BigQuery Edition, l'azienda spenderebbe troppo per le query ad-hoc; viceversa, con il pricing on-demand spenderebbe troppo sui job ricorrenti.
Calcolare il livello di pricing BigQuery più adatto al Suo workload
Gli esperti BigQuery di DoiT hanno sviluppato uno script che La aiuta a capire quale modello di pricing ha senso per ciascuno dei Suoi workloads (cioè progetti).
Lo script analizza ogni query eseguita in un progetto, in un intervallo di tempo da Lei specificato, e restituisce una raccomandazione sul modello di pricing (on-demand o una specifica Edition).
Ecco altri script sviluppati dal nostro team che potrebbero esserLe utili:
- Le query più complesse (in base all'utilizzo medio di slot durante il job).
- Le query più costose, dalla più costosa alla meno costosa
- Informazioni generali sui job
- Se conviene passare al Physical Storage o restare sul logical storage
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Come mantenere ottimizzati i costi BigQuery
Una volta individuato il modello di pricing più adatto a ciascun workload, vorrà fare in modo che i costi restino ottimizzati nel tempo. In questa sezione raccogliamo diversi consigli — alcuni consolidati, altri nati con l'introduzione di Editions — per aiutarLa a evitare sprechi su BigQuery.
Partizioni e cluster sulle tabelle per ridurre i dati elaborati
Ridurre i byte elaborati nelle query migliora le performance e abbatte i costi BigQuery con entrambi i modelli di pricing — e partizionare e/o clusterizzare le tabelle è un ottimo modo per farlo.
Sui progetti con pricing on-demand, ridurre i byte elaborati abbatte direttamente i costi di analisi, dato che paga in base ai dati scansionati.
Con BigQuery Editions, invece, più dati una query deve elaborare, più slot vengono allocati. Quindi, anche se BigQuery Editions si paga in slot-hour, ridurre i byte elaborati può portare indirettamente a un fabbisogno minore di slot.
Clustering delle tabelle BigQuery
Il clustering migliora le performance delle query organizzando la tabella in blocchi di dati, in base alla colonna o alle colonne scelte come chiave di clustering. Così BigQuery può scansionare solo i blocchi di dati rilevanti.
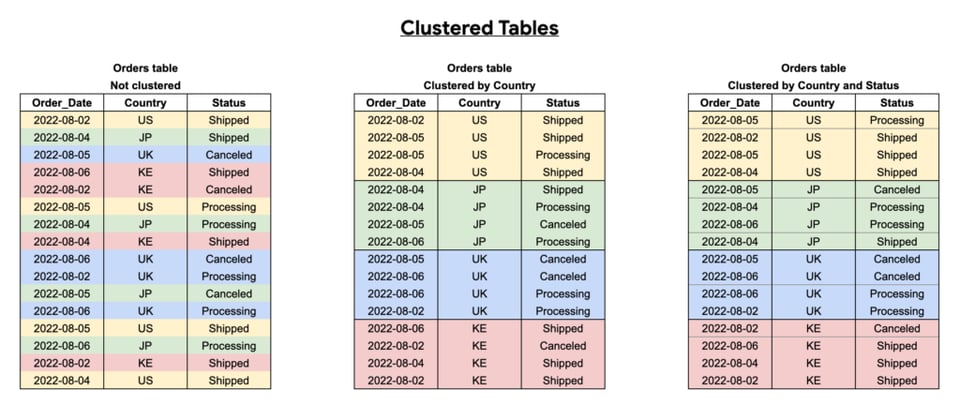
Conviene clusterizzare le tabelle in base alle colonne più frequentemente interrogate, soprattutto quando contengono molti valori distinti.
Come si vede qui sotto, l'efficacia del clustering dipende da quali colonne sceglie, dall'ordine in cui le seleziona e da come struttura le query.
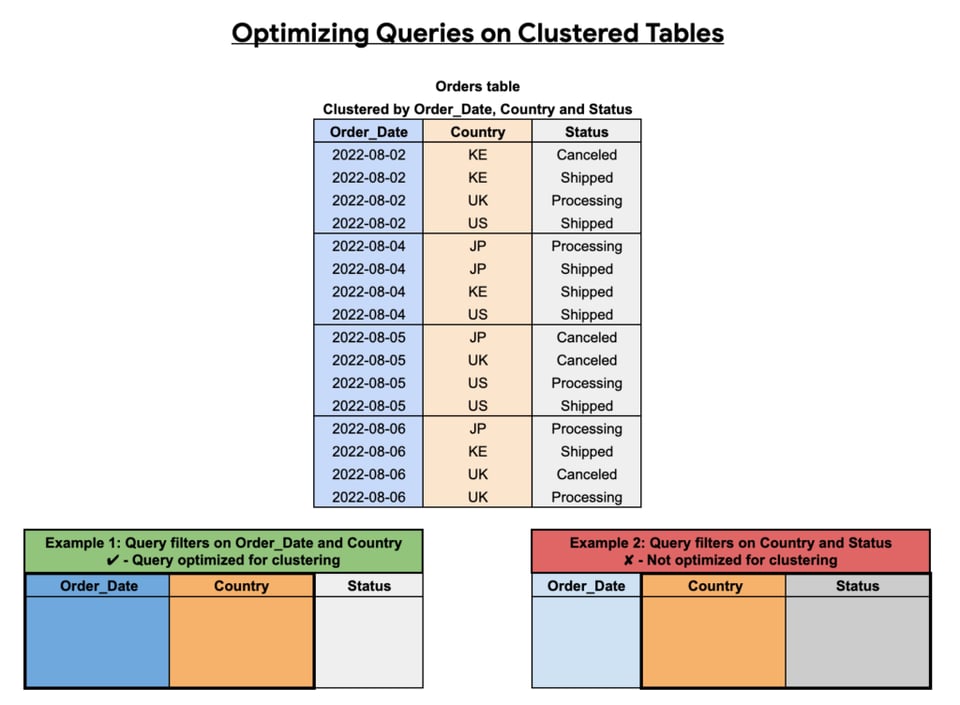
Partizionamento delle tabelle BigQuery
Il partizionamento delle tabelle aiuta a controllare i costi suddividendo una tabella di grandi dimensioni in blocchi più piccoli e permettendo di interrogare un sottoinsieme ridotto della tabella.
Attenzione però: partizionare una tabella non porta benefici se nelle query non si specificano le partizioni da scansionare, una pratica nota come partition pruning.
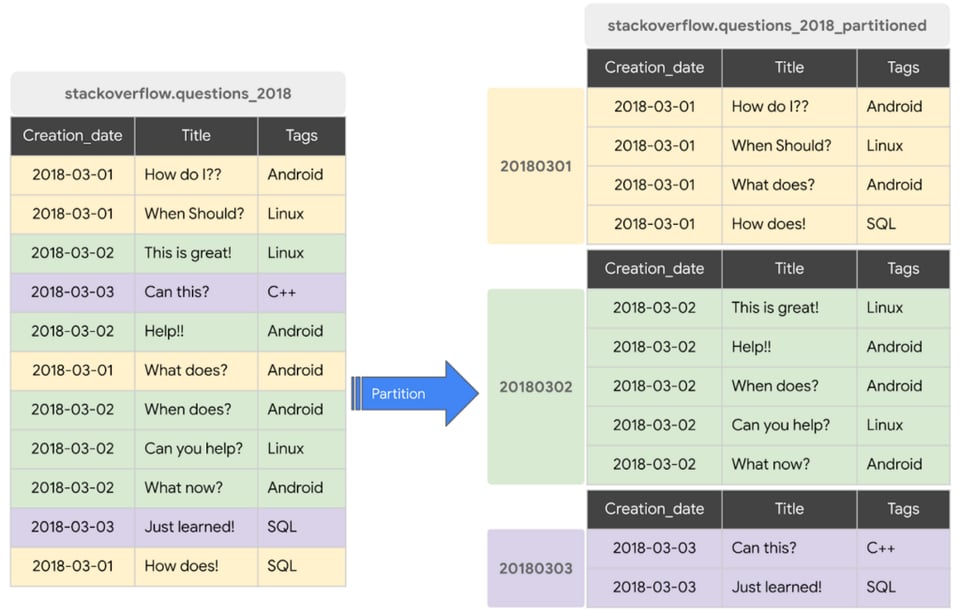
Un esempio di query che utilizza una partizione per lo screenshot qui sopra è:
SELECT * FROM stackoverflow_questions_2018 WHERE creation_date BETWEEN '2018-01-01' AND '2018-01-31'Un esempio di query che NON utilizza alcuna partizione è invece:
SELECT * FROM stackoverflow_questions_2018Pur essendo una buona pratica generale, il partizionamento delle tabelle è particolarmente consigliato se ha dashboard BI alimentate da BigQuery, perché renderà le dashboard più veloci e le query più economiche.
Come individuare le tabelle da clusterizzare o partizionare
In linea generale, conviene partizionare le tabelle di grandi dimensioni (>100 GB) quando le relative query filtrano spesso su campi data/ora.
Usi il clustering quando le query filtrano o aggregano i dati frequentemente in base a colonne specifiche. Per stabilire su quale o quali campi clusterizzare una tabella (e in che ordine), guardi le colonne più utilizzate nelle clausole WHERE o GROUP BY — e, in misura più limitata, ORDER BY — delle Sue query. L'ordine in cui sceglie queste colonne influisce su come BigQuery ordina i dati, quindi dia priorità alle colonne di filtro/aggregazione più frequenti.
Se invece utilizza DoiT Cloud Navigator, può accedere a BigQuery Lens, che Le mostrerà raccomandazioni su quali tabelle clusterizzare o partizionare — e su quali colonne farlo.
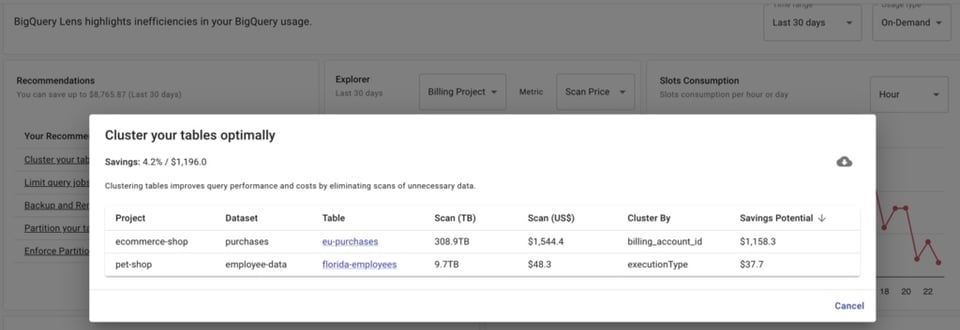
Tuttavia, anche se ha già partizionato le tabelle, deve comunque assicurarsi che vengano interrogate utilizzando il campo di partizionamento. In questo modo avrà maggiore controllo sui costi, scansionando porzioni più piccole della tabella anziché l'intero contenuto.
Ma quando si gestisce un team di data analyst, è difficile sapere se tutti includono effettivamente il campo partizionato nelle proprie query.
BigQuery Lens identifica i job che interrogano tabelle partizionate senza utilizzare il campo di partizionamento.
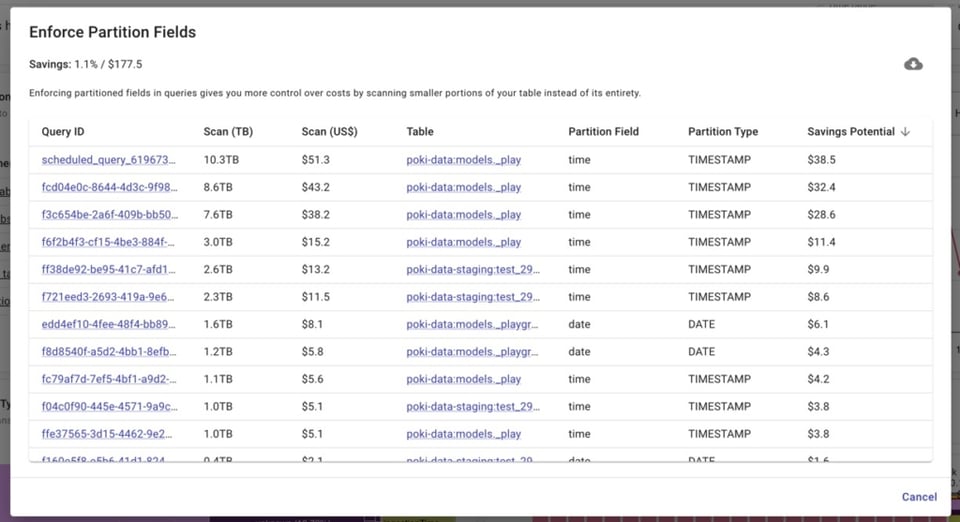
Configurare correttamente baseline e max slots
Se utilizza già BigQuery Editions o sta pianificando il passaggio, sapere come configurare correttamente baseline e max slots è fondamentale per sfruttare al meglio l'autoscaler di BigQuery.
Consigli sulla configurazione dei baseline slots
I baseline slots sono, in pratica, il numero minimo di slot che vuole avere sempre a disposizione per le Sue query. Quando li imposta, ricordi che i baseline slots vengono fatturati 24 ore su 24, 7 giorni su 7.
Se ha workloads costanti e regolari distribuiti durante la giornata, imposti un baseline più alto per evitare "cold start" e code in attesa.
Per workloads con picchi o burst, può convenire impostare un baseline basso o addirittura pari a 0, per non pagare slot inutilizzati. Tenga però presente che l'autoscaler impiega alcuni secondi per scalare da 0 a X slot. Servirà quindi tempo per scalare al primo job e, se quel job è ancora in esecuzione quando ne parte un altro, occorrerà ulteriore tempo per scalare nuovamente.
Consigli sulla configurazione dei max slots
Il limite di max slots imposta il numero massimo di slot fino al quale BigQuery può scalare automaticamente per i Suoi workloads. Impostarlo correttamente è fondamentale per controllare i costi ed evitare che l'autoscaler effettui un over-provisioning di slot.
Analizzi i pattern storici di utilizzo degli slot (con gli script citati sopra) per impostare un valore massimo ragionevole, in grado di gestire i picchi di carico evitando un over-provisioning eccessivo.
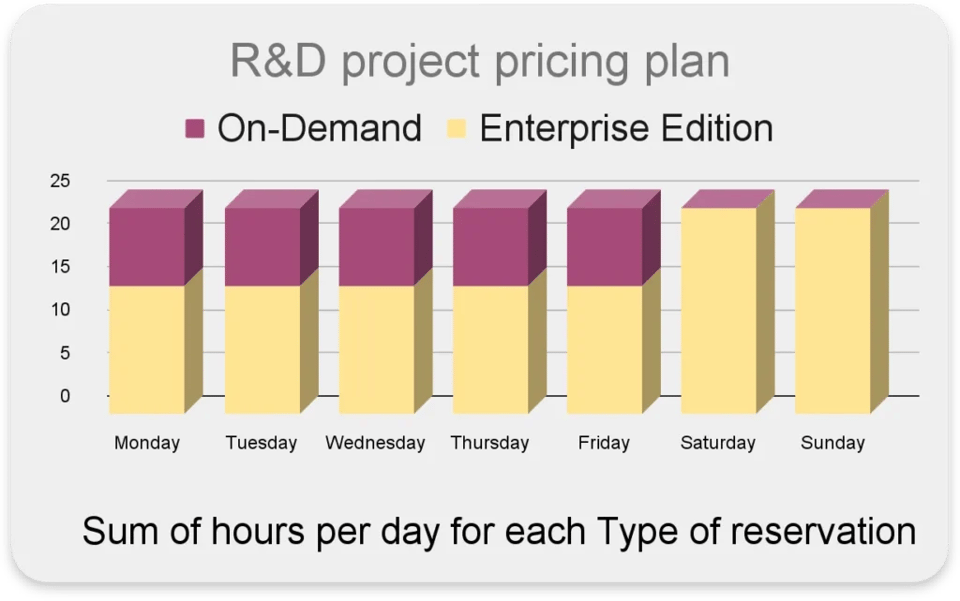
Adattare dinamicamente il modello di pricing nelle reservation
All'interno di un singolo progetto può avere attività diverse che rendono di più (o costano meno) con Editions oppure con on-demand.
Ad esempio:
- Le query interattive avvengono prevalentemente nei giorni feriali in orario d'ufficio
- Elevata concorrenza di query con tempi di risposta rapidi
- Alcune attività sono pianificate di notte o nei weekend
In questo caso, l'ideale sarebbe usare l'on-demand durante l'orario di lavoro per garantire latenza efficiente e alta concorrenza, mentre nelle ore non lavorative passare a 'Enterprise Edition' con un massimo di 100 slot.
Uno dei nostri esperti BigQuery, Nadav Weissman, illustra passo passo come automatizzare le modifiche a reservation e assignment per questo scopo qui.
Best practice per dbt, Dataform e strumenti BI
dbt e Dataform
Innanzitutto, è probabile che Le convenga utilizzare il pricing on-demand per i Suoi job dbt o Dataform. dbt è esigente in termini di compute/slot e spesso il pricing on-demand è la scelta migliore — oppure, se usa Editions, è bene tenere d'occhio le impostazioni di baseline/max slots.
dbt è esigente in termini di compute/slot e spesso il pricing on-demand è la scelta migliore — oppure occorre impostare valori realistici per il numero di slot nella configurazione baseline/max dell'autoscaler.
Sia in dbt (Incremental models) sia in Dataform (incremental tables) può elaborare solo i dati nuovi o modificati invece di rielaborare l'intero dataset. In questo modo riduce i dati elaborati, ottimizzando l'utilizzo degli slot e i costi.
Infine, può ottenere benefici economici spostando i job di trasformazione dbt/Dataform da BigQuery a servizi con compute più economico, dato che le trasformazioni sono compute-heavy.
Ad esempio, è sensibilmente più conveniente eseguire le trasformazioni su una VM o un'istanza Cloud SQL e poi caricare i dati trasformati su Google Cloud Storage, da cui verranno reimportati in BigQuery già pronti. Pur richiedendo un certo lavoro di orchestrazione dei dati, abbiamo visto clienti ridurre job di trasformazione da 50 $ a 2-3 $ con questo metodo.
Strumenti BI
Se utilizza uno strumento BI come Looker o Tableau con BigQuery principalmente per operazioni di lettura e aggregazione di dati nel tempo, dovrebbe dare un'occhiata a BI Engine.
BI Engine è perfetto per le query di dashboard, perché mantiene in cache in memoria i dati BigQuery in modo intelligente, garantendo query più veloci. E poiché BI Engine memorizza i dati in-memory, la fase di query che legge i dati delle tabelle è gratuita. Paga solo la capacità di memoria riservata.
Tenga presente che per usare BI Engine il progetto deve essere su Enterprise Edition. Ma se isola i workloads BI in un progetto dedicato, il modello di pricing a slot-hour avrà un impatto contenuto (presupponendo operazioni di lettura prevalenti) grazie al pricing di BI Engine descritto sopra.
Se nei workloads BI esegue anche molte trasformazioni di dati, questo aspetto è meno rilevante per Lei, dato che esistono alcune limitazioni sui JOIN.
Un altro approccio consiste nell'utilizzare una soluzione "a prezzo fisso" come ClickHouse, che il Suo strumento BI interrogherà al posto di BigQuery, sia per aumentare le performance sia per ridurre i costi sulla bolletta BigQuery. Il vantaggio è che paga una flat-rate per il datastore invece di una tariffa per query come avverrebbe su BigQuery.
Conclusione
Che i Suoi commitment flat-rate BigQuery siano in scadenza o meno, questo articolo offre una guida per scegliere il modello di pricing più adatto ai Suoi workloads e per affrontare il lavoro preparatorio necessario a evitare sprechi.
Le proponiamo inoltre consigli per ottimizzare i costi BigQuery: dal partizionamento e clustering delle tabelle alla corretta configurazione di baseline e max slots, fino all'uso di BI Engine per i workloads BI. Seguendo queste indicazioni, potrà essere certo di utilizzare BigQuery nel modo più efficiente possibile dal punto di vista dei costi.
Se desidera analizzare il Suo utilizzo di BigQuery con uno specialista BigQuery di DoiT, prenoti oggi una consulenza con noi!