So wechseln Sie reibungslos von auslaufenden BigQuery Flat-Rate-Commitments zu einem anderen Preismodell – und nutzen BigQuery danach weiterhin optimiert. Konkret klären wir, welche workloads besser zu Editions und welche besser zu On-Demand-Pricing passen und wie Sie Ihre workloads nach dem Wechsel von Flat-Rate (oder generell) optimiert halten.

Als BigQuery Editions Ende März letzten Jahres angekündigt wurden, hatten Unternehmen bis zum 5. Juli 2023 Zeit, für jedes ihrer Projekte zu entscheiden:
- auf Editions umzusteigen,
- weiterhin On-Demand-Pricing zu nutzen (oder darauf zu wechseln) – mit einem Preisaufschlag von 25 %, oder
- ein einjähriges Flat-Rate-Commitment abzuschließen, um Flat-Rate noch ein Jahr lang weiterzunutzen.
Viele entschieden sich für ein einjähriges Flat-Rate-Commitment, um sich Zeit zu verschaffen, ihre BigQuery-workloads neu aufzustellen und den neuen Autoscaler, die Slot-Hour-Metriken sowie Editions insgesamt besser zu durchdringen.
Wenn Ihnen das bekannt vorkommt, steht Ihnen mit dem Auslaufen Ihres Flat-Rate-Commitments eine Entscheidung mit erheblichen Kostenfolgen bevor: Wechsel zu Editions oder zu On-Demand.
Genau deshalb zeigen wir Ihnen, wie Sie reibungslos von auslaufenden BigQuery Flat-Rate-Commitments auf ein anderes Preismodell wechseln und Ihre Nutzung danach optimiert halten.
Konkret behandeln wir:
- welche workloads besser zu Editions und welche besser zu On-Demand-Pricing passen
- wie Sie Ihre workloads nach dem Wechsel von Flat-Rate (oder generell) optimiert halten
Wir haben das Thema auch in unserem Cloud Masters Podcast besprochen – falls Sie lieber zuhören oder zuschauen statt lesen:

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Den Wechsel vom auslaufenden Flat-Rate-Commitment meistern
Wenn Sie keine Entscheidung treffen, bevor Ihr Flat-Rate-Commitment ausläuft, wandelt sich Ihr Projekt automatisch in eine Enterprise-Edition-Reservation um – mit Baseline und Max Slots auf der Anzahl an Slots, die Sie zuvor zugesichert hatten.
Und da Jobs auf der Enterprise Edition pro genutztem Slot etwa das 2,53-Fache gegenüber Flat-Rate kosten, sollten Sie vorab prüfen, ob die Enterprise Edition – oder Editions im Allgemeinen – für Ihren Workload überhaupt sinnvoll ist.
Welches Preismodell für Sie das richtige ist, lässt sich allerdings nicht pauschal beantworten.
Warum die Antwort lautet: "Es kommt darauf an"
Bevor wir die typischen Einsatzszenarien der einzelnen Preismodelle durchgehen, schauen wir uns ein paar Punkte an, die Sie zu jedem Modell wissen und bewerten sollten.
On-Demand
Mit On-Demand bekommen Sie mehr Compute-Kapazität zu einem besseren Preis als bei jeder Edition.
Allerdings wird nach verarbeiteten oder gescannten Daten abgerechnet – Jobs, die enorme Datenmengen scannen, können unter On-Demand also teurer ausfallen. Außerdem sind Sie auf 2.000 Slots gedeckelt.
BigQuery Editions
Bei BigQuery Editions zahlen Sie pro Slot-Hour für zugewiesene Slots, nicht für tatsächlich genutzte. Das ist wichtig, wenn Sie den Autoscaler einsetzen, der zu Editions gehört.
Vielleicht ist Ihnen unter Flat-Rate aufgefallen, dass Sie zu bestimmten Tageszeiten mehr Slots brauchen, als Sie zugesichert hatten. In solchen Fällen kann der Autoscaler den Ausschlag in Richtung Editions geben.
Vorsicht ist aber geboten: Der Autoscaler skaliert in 100-Slot-Schritten und für mindestens 60 Sekunden. Das birgt das Risiko von Slot-Verschwendung oder Mehrausgaben für Slots.
Beispiel: Wenn ein Job 101 Slots benötigt, skaliert der Autoscaler auf 200 Slots hoch – Sie zahlen also für 99 Slots, die Sie nicht gebraucht haben.
Oder ein Job benötigt nur sechs Sekunden lang 200 Slots. In diesem Fall zahlen Sie 200 Slots für 54 Sekunden länger als nötig.
Faustregel zur Wahl des richtigen Preismodells
Sie müssen die Anzahl der genutzten Slots der gescannten Datenmenge gegenüberstellen, um zu beurteilen, ob ein Job auf On-Demand oder auf Editions günstiger ist. Berücksichtigen Sie zudem Anforderungen an Geschwindigkeit und Performance.
Beispiel: Angenommen, Sie führen viele rechenintensive, aber slot-arme statistische Analysejobs aus (Aggregationen, k-Means etc.). Wenn Sie dafür jedes Mal 1 TB Daten scannen, kostet Sie das auf On-Demand 6,25 $. Auf der Standard Edition mit 100 dedizierten Slots zahlen Sie für denselben Job womöglich nur 2,00 $.
Multiplizieren Sie das mit der Häufigkeit, mit der Sie diesen Job ausführen, und der Unterschied zwischen den beiden Preismodellen wird schnell spürbar.
Auf Editions kann der Job zwar länger laufen – aber vielleicht ist Ihnen die Kostenersparnis von 68 % das wert.
Diese Entscheidung müssen Sie pro Workload treffen.

Welche workloads passen am besten zu BigQuery Editions?
Generell sind langlaufende workloads mit wenigen Spitzen ein guter Fit für Editions. Noch besser, wenn diese workloads große Datenmengen lesen. Denn der BigQuery-Autoscaler kann bei spiky workloads recht aggressiv reagieren.
Stellen Sie sich beispielsweise ein Projekt vor, das zu einer bestimmten Tageszeit einen slot-intensiven BigQuery-Job ausführt.
Lassen Sie das auf Editions laufen, schießen die genutzten Slots während der Job-Laufzeit in die Höhe (zusätzliche Slots, die über Ihren Bedarf hinausgehen, werden für mindestens eine Minute mitberechnet) – das führt in Spitzenzeiten zu unvorhersehbaren Kosten.
Bei konstanten, aber dennoch umfangreichen BigQuery-workloads kann der Slot-Erwerb über die Editions-Preismodelle dagegen oft günstiger sein als On-Demand-Pricing – und sorgt zugleich für eine gleichbleibende Verfügbarkeit Ihrer BigQuery-Compute-Ressourcen zu einem planbaren Preis.
Beispiele für solche workloads sind langlaufende, regelmäßige Analytics-Jobs oder Machine-Learning-Tasks, die stundenlang große Datenmengen verarbeiten.
Welche workloads passen am besten zum On-Demand-Pricing von BigQuery?
Auf der anderen Seite ist On-Demand-Pricing oft die bessere Wahl bei spiky oder sporadischen workloads – also kurzen, intensiven Verarbeitungsphasen, gefolgt von langen Phasen der Inaktivität.
Typisch ist das bei Dev-/Test-Projekten oder BI-workloads. Hier ist es oft sinnvoll, für die verarbeiteten Bytes zu zahlen, weil die Kosten meist deutlich unter dem Preis selbst einer kleinen BQ-Editions-Reservation liegen.
Berücksichtigen Sie außerdem Jobs, die zwar keine Daten verarbeiten, aber dennoch Slots beanspruchen. BigLake-Metadaten-Refreshes, bei denen das Tabellenschema aktualisiert und neu geladen wird, ohne dass tatsächlich Daten verarbeitet werden, sind ein Paradebeispiel. Liefe dieser Job in einem Projekt mit Editions-Pricing, würden Sie für die skalierten (nicht genutzten) Slots zahlen. In einem Projekt mit On-Demand-Pricing zahlen Sie dafür hingegen 0 $.
workloads aufteilen, um BigQuery-Kosten zu optimieren
Beim BigQuery-Pricing gibt es keine "One-size-fits-all"-Lösung.
Da Sie projektübergreifend unterschiedliche BigQuery-Preismodelle nutzen können, sollten Sie zunächst sicherstellen, dass Ihre workloads auf dedizierte Projekte verteilt und nicht in einem einzigen Projekt zusammengefasst sind.
Verschiedene Workload-Typen in unterschiedliche Projekte zu legen – und dort jeweils unterschiedliche BigQuery-Preisstufen einzusetzen – ist ein hervorragender Hebel zur Kostensenkung, weil sich für jeden Workload das passende Preismodell leichter zuordnen lässt.
Sind Ihre workloads noch nicht in unterschiedliche Projekte isoliert, sollten Sie das zuerst angehen.
Zum Beispiel:
- ETL- und ELT-workloads gehören in ein eigenes Projekt, getrennt von Ihren R&D-workloads.
- Spiky, kurzlaufende workloads gehören in ein Projekt mit On-Demand-Pricing.
Wenn die meisten Ihrer workloads in einem zentralen Projekt liegen, befürchten Sie vielleicht, dass eine Aufteilung zu kompliziert wird. Es gibt Konfigurationsanpassungen zu beachten – möglicherweise müssen Sie Ihre Macros anpassen, falls Sie dbt einsetzen. Aber bedenken Sie die Folgen, wenn Sie Ihre BigQuery-workloads nicht in unterschiedliche Projekte aufteilen.
Stellen Sie sich ein Unternehmen vor, dessen tägliche Daten-Pipeline-Jobs im selben Projekt laufen wie Ad-hoc-Jobs zur explorativen Datenanalyse. Bei einer BigQuery Edition wären die Ad-hoc-Queries überteuert – bei On-Demand-Pricing wäre es bei den Pipeline-Jobs umgekehrt.
Berechnen, welche BigQuery-Preisstufe für Ihren Workload am besten passt
Die BigQuery-Experten bei DoiT haben ein Skript entwickelt, das Ihnen hilft, das passende Preismodell für jeden Ihrer workloads (also Projekte) zu bestimmen.
Es analysiert jede Query, die in einem Projekt über einen von Ihnen festgelegten Zeitraum ausgeführt wurde, und gibt eine Preismodell-Empfehlung aus (On-Demand oder eine bestimmte Edition).
Hier sind weitere Skripte unseres Teams, die Sie nützlich finden könnten:
- Komplexeste Queries (gemessen an der durchschnittlichen Slot-Nutzung während des Jobs).
- Teuerste Queries, vom teuersten zum günstigsten
- Allgemeine Job-Informationen
- Ob Sie zu Physical Storage wechseln oder bei Logical Storage bleiben sollten
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
So halten Sie Ihre BigQuery-Kosten dauerhaft optimiert
Sobald Sie wissen, welches Preismodell zu welchem Workload passt, sollten Sie dafür sorgen, dass Ihre Kosten auch künftig optimiert bleiben. In diesem Abschnitt zeigen wir Ihnen mehrere Tipps – einige altbekannt, einige neu mit der Einführung von Editions –, die Mehrausgaben bei BigQuery vermeiden helfen.
Tabellen partitionieren und clustern, um die verarbeitete Datenmenge zu reduzieren
Weniger verarbeitete Bytes verbessern die Query-Performance und senken die BigQuery-Kosten in beiden Preismodellen – Tabellen zu partitionieren und/oder zu clustern ist dafür ein hervorragender Weg.
Bei Projekten mit On-Demand-Pricing senken Sie damit Ihre Analysekosten direkt, da Sie auf Basis der gescannten Datenmenge zahlen.
Bei BigQuery Editions gilt: Je mehr Daten eine Query verarbeiten muss, desto mehr Slots werden zugewiesen. Auch wenn BigQuery Editions auf Slot-Hours abrechnen, kann eine geringere verarbeitete Datenmenge indirekt dazu führen, dass weniger Slots benötigt werden.
BigQuery-Tabellen clustern
Clustering verbessert die Query-Performance, indem die Tabelle anhand der Spalte(n), nach denen Sie clustern, in Datenblöcke organisiert wird. So kann BigQuery gezielt nur die relevanten Datenblöcke scannen.
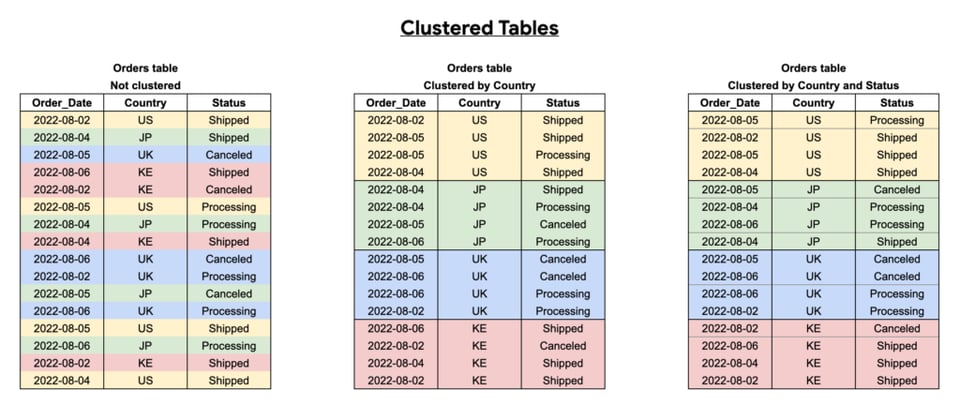
Sie sollten Tabellen nach häufig abgefragten Spalten clustern – vor allem dann, wenn diese viele unterschiedliche Werte enthalten.
Wie unten zu sehen, hängt die Wirksamkeit des Clusterings davon ab, welche Spalten Sie wählen, in welcher Reihenfolge und wie Ihre Queries strukturiert sind.
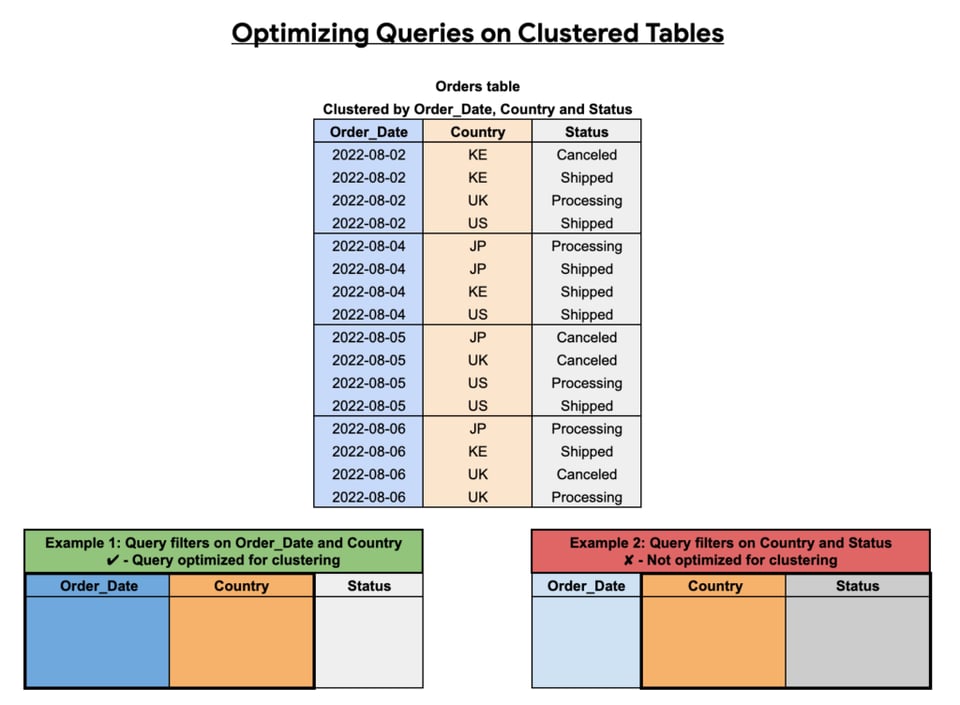
BigQuery-Tabellen partitionieren
Partitionierung hilft, Kosten zu kontrollieren, indem eine große Tabelle in kleinere Stücke aufgeteilt wird, sodass Sie nur eine Teilmenge der Tabelle abfragen.
Beachten Sie aber: Eine partitionierte Tabelle bringt nichts, wenn Sie in Ihren Queries nicht angeben, welche Tabellenpartitionen gescannt werden sollen – auch bekannt als Partition Pruning.
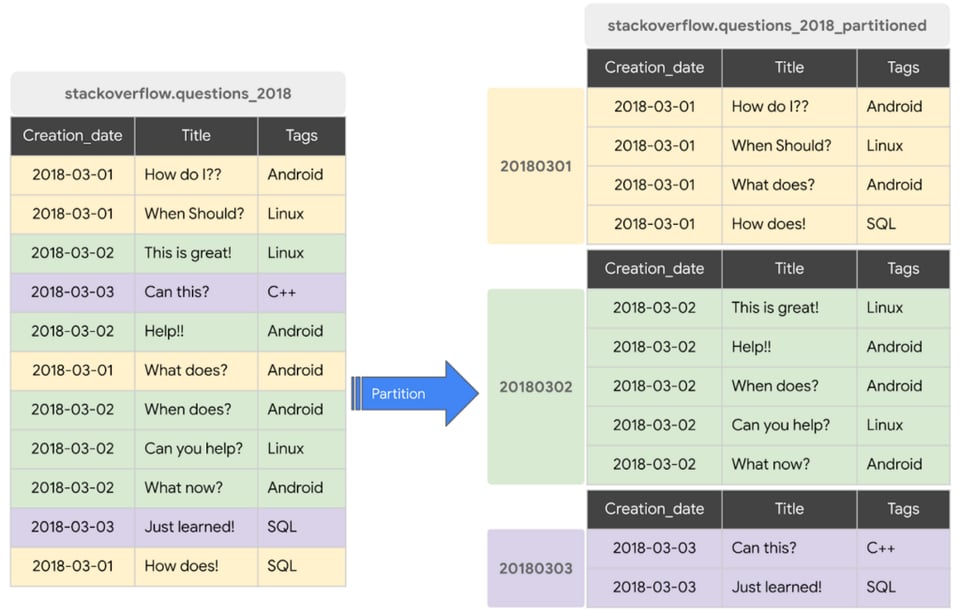
Eine Beispiel-Query, die für den obigen Screenshot eine Partition nutzt, sähe so aus:
SELECT * FROM stackoverflow_questions_2018 WHERE creation_date BETWEEN ‘2018-01-01’ AND ‘2018-01-31’Eine Beispiel-Query, die KEINE Partition nutzt, wäre:
SELECT * FROM stackoverflow_questions_2018Tabellen sollten Sie generell partitionieren – besonders dann, wenn Sie BI-gestützte dashboards auf BigQuery betreiben. Tabellenpartitionen machen Ihre dashboards schneller und Queries günstiger.
Identifizieren, welche Tabellen geclustert oder partitioniert werden sollten
Generell sollten Sie große Tabellen (>100 GB) partitionieren, deren Queries häufig nach Datums-/Zeitfeldern filtern.
Setzen Sie Clustering ein, wenn Ihre Queries häufig nach bestimmten Spalten filtern oder aggregieren. Welche Felder sich in welcher Reihenfolge zum Clustern eignen, erkennen Sie an den Spalten, die in WHERE- oder GROUP-BY-Klauseln – und in begrenzterem Umfang in ORDER-BY-Klauseln – am häufigsten vorkommen. Die Reihenfolge der Spalten beeinflusst, wie BigQuery die Daten sortiert – priorisieren Sie also die am häufigsten verwendeten Filter-/Aggregationsspalten zuerst.
Wenn Sie DoiT Cloud Navigator nutzen, erhalten Sie Zugriff auf BigQuery Lens, das Empfehlungen liefert, welche Tabellen geclustert oder partitioniert werden sollten – und nach welchen Spalten.
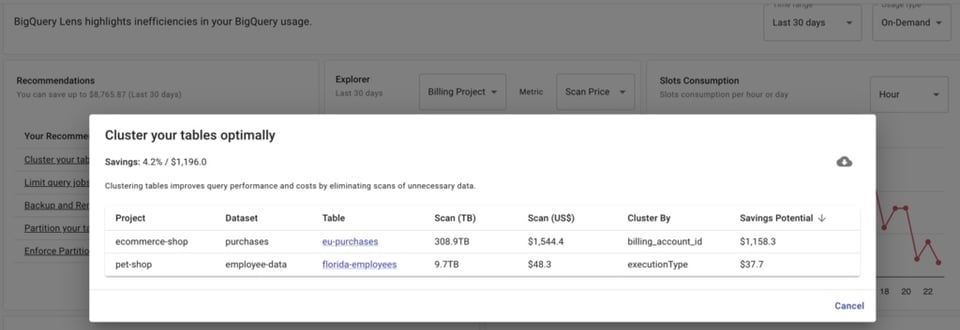
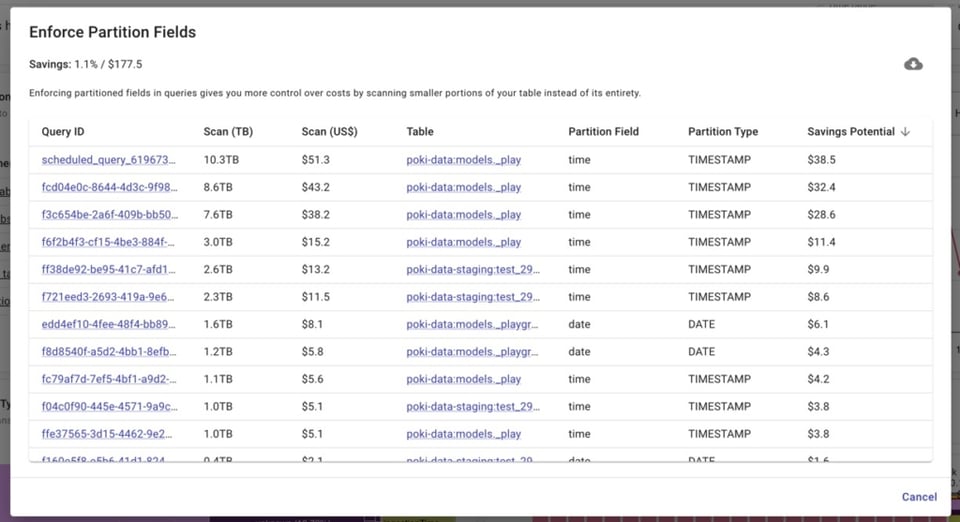
Doch selbst bei bereits partitionierten Tabellen müssen Sie sicherstellen, dass diese auch über das Feld abgefragt werden, nach dem partitioniert wurde. So gewinnen Sie mehr Kontrolle über die Kosten, weil Sie kleinere Teile statt der gesamten Tabelle scannen.
Wenn Sie ein Team aus Datenanalysten führen, ist allerdings schwer zu überblicken, ob alle das partitionierte Feld in ihren Queries auch tatsächlich verwenden.
BigQuery Lens identifiziert Jobs, die partitionierte Tabellen abfragen, ohne das partitionierte Feld zu verwenden.
Baseline und Max Slots richtig konfigurieren
Wenn Sie BigQuery Editions bereits einsetzen oder einen Wechsel planen, ist die richtige Konfiguration von Baseline und Max Slots entscheidend, um den BigQuery-Autoscaler optimal zu nutzen.
Tipps zur Konfiguration der Baseline Slots
Ihre Baseline Slots sind im Grunde die Mindestanzahl an Slots, die Sie jederzeit für Ihre Queries verfügbar haben möchten. Wichtig dabei: Baseline Slots werden Ihnen rund um die Uhr berechnet.
Laufen über den Tag konstante, gleichmäßige workloads, setzen Sie eine höhere Baseline an, um "Cold Starts" und Queuing zu vermeiden.
Bei spiky oder bursty workloads kann es sinnvoll sein, die Baseline niedrig oder sogar auf 0 zu setzen, um nicht für ungenutzte Slots zu zahlen. Beachten Sie aber: Der Autoscaler braucht ein paar Sekunden, um von 0 auf X Slots hochzuskalieren. Beim ersten Job dauert das Hochskalieren also etwas – und läuft dieser Job noch, während ein weiterer startet, ist erneut Skalierungszeit nötig.
Tipps zur Konfiguration der Max Slots
Das Max-Slots-Limit legt fest, auf wie viele Slots BigQuery für Ihre workloads automatisch hochskalieren darf. Eine angemessene Obergrenze ist wichtig, um Kosten zu kontrollieren und zu verhindern, dass der Autoscaler zu viele Slots bereitstellt.
Werten Sie Ihre historischen Slot-Nutzungsmuster aus (mit den oben genannten Skripten), um ein realistisches Maximum festzulegen, das Lastspitzen abdeckt, ohne übermäßig zu überprovisionieren.
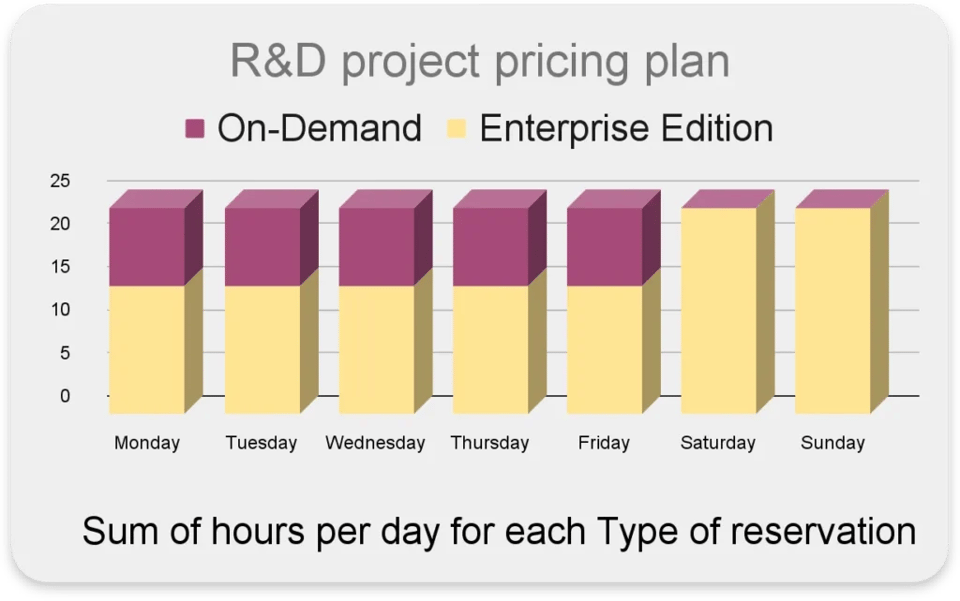
Das Preismodell Ihrer Reservations dynamisch anpassen
Innerhalb eines Projekts kann es Aktivitäten geben, die mit Editions besser laufen (oder günstiger sind) – und andere, die mit On-Demand besser fahren.
Zum Beispiel:
- Interaktive Queries laufen vor allem werktags zu Geschäftszeiten
- Hohe Query-Concurrency mit kurzen Antwortzeiten
- Bestimmte Tasks sind nachts oder am Wochenende geplant
In diesem Fall wäre es ideal, während der Arbeitszeiten On-Demand zu nutzen – für effiziente Query-Latenzen und hohe Concurrency – und außerhalb der Arbeitszeiten die "Enterprise Edition" mit maximal 100 Slots einzusetzen.
Einer unserer BigQuery-Experten, Nadav Weissman, zeigt Schritt für Schritt, wie Sie Reservation- und Assignment-Wechsel zu diesem Zweck automatisieren – hier.
Best Practices für dbt, Dataform und BI-Tools
dbt und Dataform
Erstens: Für Ihre dbt- oder Dataform-Jobs ist On-Demand-Pricing meist die richtige Wahl. dbt ist compute-/slot-intensiv – oft fahren Sie mit On-Demand-Pricing besser, oder Sie behalten zumindest Ihre Baseline-/Max-Slots-Einstellungen genau im Auge, falls Sie Editions verwenden.
dbt ist compute-/slot-intensiv – oft fahren Sie mit On-Demand-Pricing besser oder setzen realistische Slot-Werte in Ihrer Baseline-/Max-Konfiguration für den Autoscaler.
Sowohl in dbt (Incremental Models) als auch in Dataform (Incremental Tables) können Sie nur neue/geänderte Daten verarbeiten, statt den gesamten Datensatz neu zu laden. Das senkt die verarbeitete Datenmenge und optimiert Slot-Nutzung und Kosten.
Schließlich kann es kostenseitig sinnvoll sein, dbt-/Dataform-Transformationsjobs aus BigQuery auf Services mit günstigerer Compute-Leistung auszulagern – schließlich sind Transformationen rechenintensiv.
Beispielsweise wäre es deutlich günstiger, die Transformationen auf einer VM oder einer Cloud-SQL-Instanz auszuführen und die transformierten Daten dann zurück in den Google Cloud Storage zu laden, von wo sie bereits transformiert in BigQuery geladen werden. Das erfordert zwar etwas Daten-Orchestrierung, aber wir haben gesehen, wie Kunden mit dieser Methode 50-$-Transformationsjobs auf 2–3 $ reduziert haben.
BI-Tools
Wenn Sie ein BI-Tool wie Looker oder Tableau mit BigQuery vor allem für Lesezugriffe und das Aggregieren von Daten über die Zeit nutzen, sollten Sie sich BI Engine ansehen.
BI Engine ist perfekt für Dashboard-Queries, weil BigQuery-Daten intelligent im Arbeitsspeicher gecacht werden – das beschleunigt Queries spürbar. Und da BI Engine Daten in-memory cacht, ist die Query-Stage, die Tabellendaten liest, kostenlos. Sie zahlen stattdessen nur für die reservierte Speicherkapazität.
Beachten Sie, dass für BI Engine die Enterprise Edition erforderlich ist. Wenn Sie Ihre BI-workloads jedoch in einem eigenen Projekt isolieren, fällt das Slot-Hour-Preismodell – sofern es überwiegend um Leseoperationen geht – angesichts der oben genannten BI-Engine-Preise weniger ins Gewicht.
Wenn Sie in Ihren BI-workloads auch stark Daten transformieren, ist das für Sie weniger relevant – hier gibt es einige Einschränkungen rund um JOINs.
Ein anderer Ansatz ist eine "Fixed-Price"-Lösung wie ClickHouse, die Ihr BI-Tool anstelle von BigQuery abfragt – entweder zur Performance-Steigerung oder zur Senkung Ihrer BigQuery-Rechnung. Vorteil: Sie zahlen für den Datenspeicher einen Pauschalpreis statt eines Preises pro Query wie bei BigQuery.
Fazit
Ob Ihre Flat-Rate-BigQuery-Commitments auslaufen oder nicht – dieser Blogpost ist ein Leitfaden, der Ihnen hilft, das beste Preismodell für Ihre workloads auszuwählen, und zeigt, welche Vorarbeiten nötig sind, um Mehrausgaben zu vermeiden.
Außerdem geben wir Tipps zur Optimierung Ihrer BigQuery-Kosten – darunter das Partitionieren und Clustern von Tabellen, das passende Setzen von Baseline und Max Slots sowie der Einsatz von BI Engine für BI-workloads. Wenn Sie diese Empfehlungen befolgen, nutzen Sie BigQuery so kosteneffizient wie möglich.
Wenn Sie Ihre BigQuery-Nutzung mit einem BigQuery-Spezialisten von DoiT prüfen lassen möchten, vereinbaren Sie noch heute eine Beratung!