Si ce n'est pas déjà fait, lisez la partie I de cette série, sans quoi ce qui suit aura beaucoup moins de sens.

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Séparer les mauvaises données des bonnes
J'ai ajouté quelques fonctionnalités à notre pipeline. Il dispose désormais d'une durée configurable pour les tentatives de retry, enregistre la DateTime de réception des données (processed_timestamp) et redirige les données ayant dépassé le délai de retry vers une bad data table.
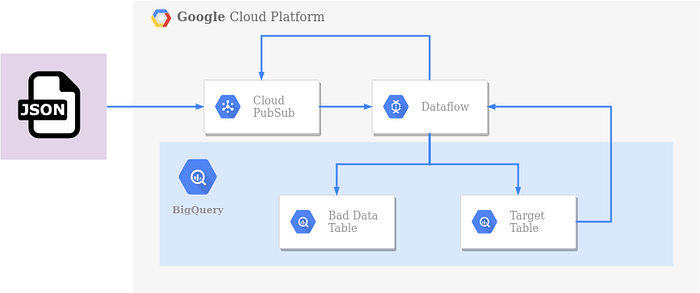
Voyons à quoi ressemble le nouveau DAG :
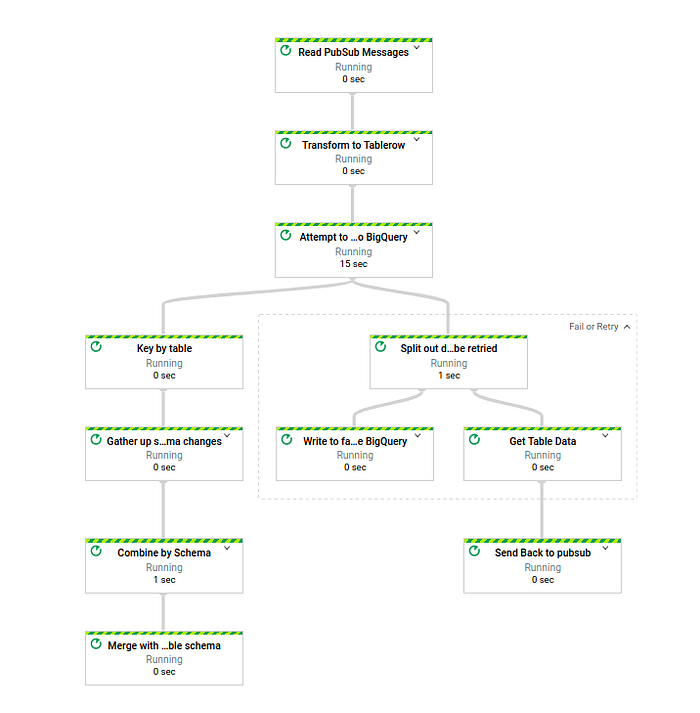
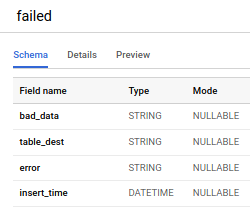
Comme vous pouvez le constater, une nouvelle étape sépare les données en deux groupes : celles qui feront l'objet d'un retry et celles qui seront déversées dans la bad data table. Cette table contient les données d'origine, bad_data ; la table cible dans BigQuery, target_dest ; l'erreur précise rencontrée par cette donnée, error ; et l'horodatage d'insertion dans la bad data table, insert_time.
Fonctionnement du mécanisme de retry
Le mécanisme de retry repose sur un entier définissant le nombre de minutes pendant lesquelles un message peut être retenté. À chaque nouvelle tentative, le compteur de retry stocké dans le message est mis à jour. Cette valeur correspond à la différence en minutes entre l'heure de réception initiale, processed_timestamp, et l'heure courante, divisée par la taille (en minutes) de la fenêtre de traitement. On obtient ainsi le nombre de fois où nous avons tenté de migrer le schéma dans la table cible BigQuery.
À noter que le message a pu repasser plusieurs fois par l'étape de retry ; toutefois, comme la migration n'a été tentée qu'un nombre fixe de fois en raison de la fenêtre de temps de traitement, ce compteur reflète fidèlement le nombre de tentatives de modification du schéma de la table cible.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Définir une fenêtre temporelle pour les changements de schéma
La fenêtre de traitement pour les changements de schéma fonctionne en créant une clé, pour la table cible, et une valeur correspondant au nouveau schéma combiné, c'est-à-dire la fusion du schéma entrant et du schéma actuel de la table cible. Cela se produit selon un intervalle de temps configurable. On évite ainsi de mettre à jour BigQuery pour chaque donnée portant un schéma différent, en privilégiant une fenêtre qui regroupe l'ensemble des changements. Ce regroupement évite les situations où un grand nombre d'objets JSON récents, tous porteurs d'un nouveau schéma pour la table cible, tentent simultanément de la mettre à jour. Comme les opérations s'exécutent en parallèle, de nombreuses mises à jour peuvent être déclenchées — d'où l'intérêt du regroupement. Pour y parvenir dans Dataflow, on utilise une Fixed Time window. Consultez la documentation officielle de Beam à ce sujet, ou l'exemple simple ci-dessous.
Compte tenu du regroupement des changements de schéma, le compteur de retry correspond en réalité au nombre de fois où le pipeline a tenté de mettre à jour le schéma de la table cible. L'objet JSON à l'origine de ce changement a pu transiter de nombreuses fois par le pipeline, ou très peu. Si votre pipeline traite un grand volume de données, réglez la taille de la fenêtre sur une valeur réduite (1 à 5). Avec un volume plus faible, vous pouvez naturellement opter pour une fenêtre plus large ; cela allongera toutefois le temps nécessaire à la mise à jour de la table cible. Dans le doute, conservez la valeur par défaut de 3.
Vous trouverez davantage d'informations dans le dépôt GitHub de ce projet. Si ce projet vous plaît, n'hésitez pas à jeter un œil à mon dépôt git personnel.