Se non l'ha ancora fatto, Le consigliamo di leggere la parte I di questa serie: in caso contrario, quanto segue risulterà di più difficile comprensione.

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Come separare i dati corrotti da quelli validi
Ho introdotto alcune funzionalità nella nostra pipeline. Ora prevede un intervallo di tempo configurabile per i tentativi di retry, registra il DateTime di ricezione del dato (processed_timestamp) e sposta i dati che hanno superato il tempo di retry in una "bad data table".
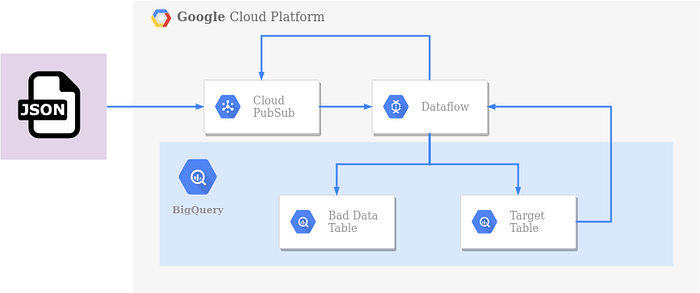
Vediamo come si presenta il nuovo DAG:
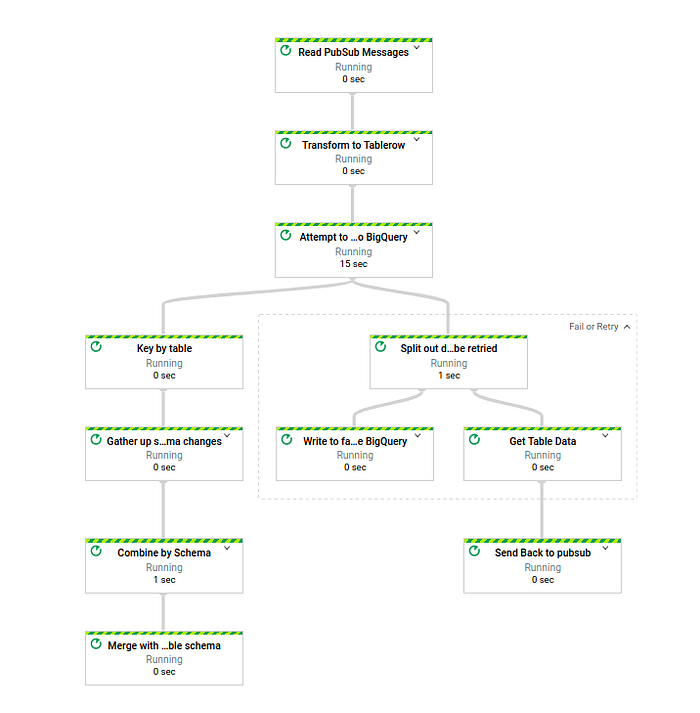
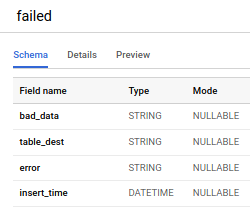
Come può vedere, c'è un nuovo step che separa i dati in due gruppi: quelli che verranno sottoposti a retry e quelli che finiranno nella "bad data table". Quest'ultima contiene il dato originale, bad_data; la tabella di destinazione in BigQuery, target_dest; l'errore specifico con cui il dato è fallito, error; e l'orario di inserimento nella bad data table, insert_time.
Come funziona il meccanismo di retry
Il meccanismo di retry si basa su un valore intero che indica per quanti minuti un messaggio può essere ritentato. Ogni volta che un messaggio viene ritentato, il numero di retry memorizzato al suo interno viene aggiornato. Il valore aggiornato corrisponde alla differenza in minuti tra l'orario di ricezione originale, processed_timestamp, e l'orario attuale, divisa per la dimensione (in minuti) della finestra temporale di elaborazione. Otteniamo così, di fatto, il numero di volte in cui abbiamo provato a migrare lo schema nella tabella di destinazione di BigQuery.
Va precisato che il messaggio potrebbe aver attraversato lo step di retry più di una volta; tuttavia, poiché i tentativi di migrazione sono limitati a un numero fisso dalla finestra temporale di elaborazione, il valore rappresenta in modo accurato il numero di volte in cui si è cercato di modificare lo schema della tabella di destinazione.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Definire una finestra temporale per le modifiche dello schema
La finestra temporale di elaborazione per le modifiche dello schema funziona creando una chiave, associata alla tabella di destinazione, e un valore che corrisponde al nuovo schema combinato, ovvero la fusione tra lo schema in ingresso e quello attuale della tabella di destinazione. Tutto questo avviene con un incremento temporale configurabile. In questo modo si evita di aggiornare BigQuery per ogni singolo dato con uno schema diverso, raggruppando invece le modifiche in un'unica finestra. La finestra combinata evita situazioni in cui un gran numero di oggetti JSON recenti, tutti con un nuovo schema, tenta contemporaneamente di aggiornare la tabella di destinazione. Poiché le operazioni avvengono in parallelo, gli aggiornamenti innescati possono essere molti: da qui la necessità di combinarli. In Dataflow questo risultato si ottiene con una Fixed Time window. Può approfondire l'argomento nella documentazione ufficiale di Beam, oppure consultare un semplice esempio qui sotto.
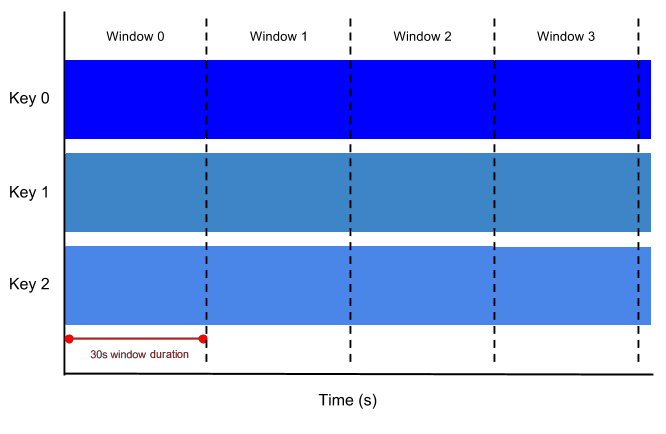
Dato il raggruppamento delle modifiche dello schema, il numero di retry corrisponde di fatto al numero di volte in cui la pipeline ha tentato di aggiornare lo schema della tabella di destinazione. L'oggetto JSON che innesca la modifica può aver attraversato la pipeline molte volte oppure pochissime. Se la pipeline gestisce grandi volumi di dati, Le consigliamo di impostare una finestra ridotta (1-5). Con volumi inferiori può ovviamente usare una finestra più ampia, tenendo però presente che ciò allungherà i tempi di aggiornamento della tabella di destinazione. Nel dubbio, mantenga il valore predefinito di 3.
Trova maggiori informazioni nella repository GitHub di questo progetto. Se Le interessa, può dare un'occhiata anche alla mia git repo personale.