まだお読みでない方は、本シリーズの前編を先にご覧ください。前編を読んでいないと、以下の内容が分かりにくくなります。

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
不良データを正常データから切り分ける
パイプラインにいくつか機能を追加しました。リトライの試行時間を設定できるようにし、データを受信した日時(processed_timestamp)を記録するようにしたほか、リトライ時間を過ぎたデータは「不良データテーブル」に出力されるようになっています。
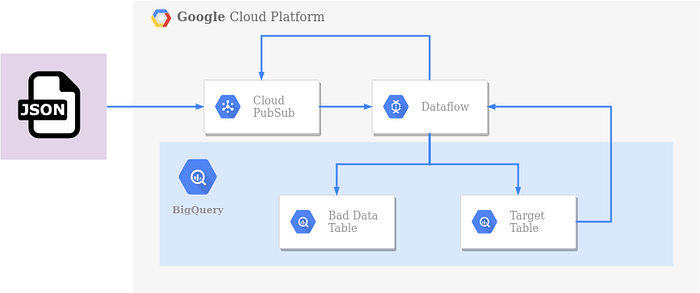
新しいDAGを見てみましょう。
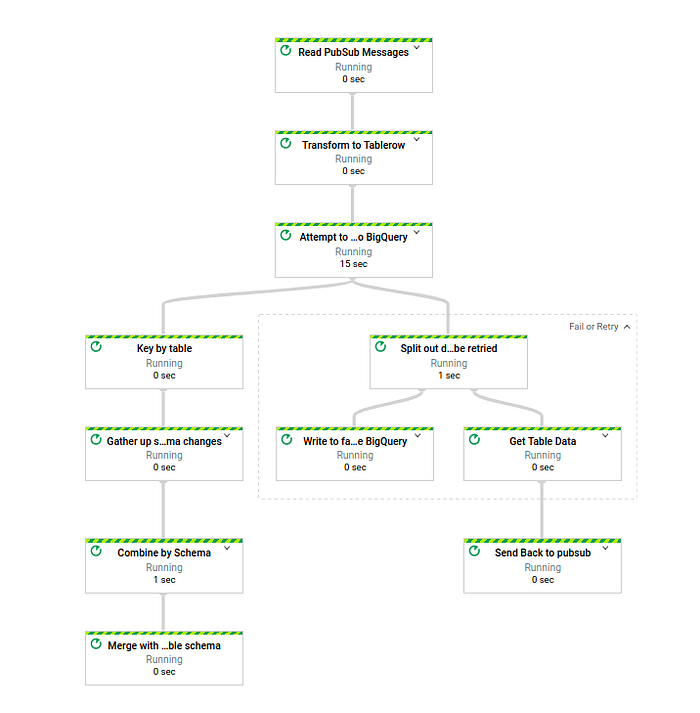
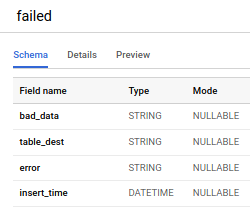
ご覧のとおり、データを2つのグループに分けるステップが新たに加わりました。リトライするデータと、「不良データテーブル」に出力するデータです。不良データテーブルには、元データ(bad_data)、BigQuery側のターゲットテーブル(target_dest)、そのデータが失敗した具体的なエラー内容(error)、不良データテーブルへの挿入時刻(insert_time)が格納されます。
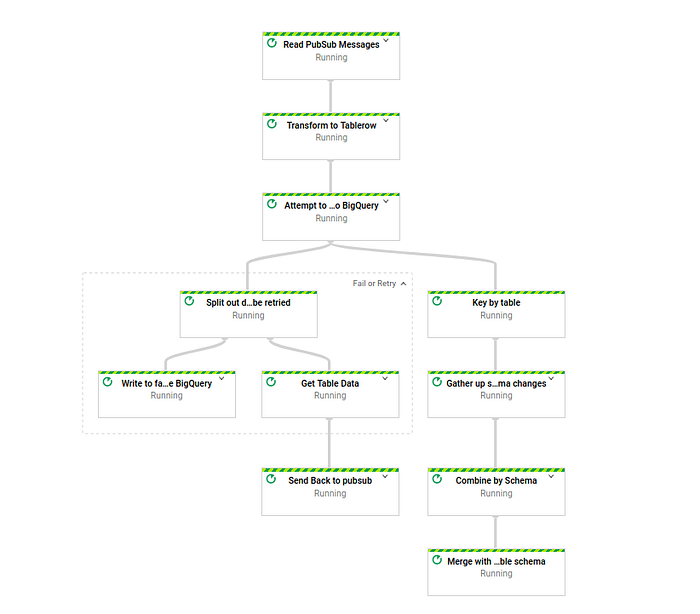
リトライ機構の仕組み
リトライ機構では、メッセージをリトライできる時間(分単位)を整数で指定します。メッセージがリトライされるたびに、メッセージに保持されているリトライ回数が更新されます。この値は、最初に受信した時刻(processed_timestamp)と現在時刻との差(分)を、処理時間ウィンドウのサイズ(分)で割った数値です。これにより、BigQueryのターゲットテーブルへのスキーマ移行を試みた回数を実質的に把握できます。
ただし注意点として、メッセージがリトライステップを複数回通過している可能性はあります。とはいえ、処理時間ウィンドウの仕組み上、移行の試行回数は一定の範囲に収まるため、ターゲットテーブルのスキーマ変更を試みた回数を正確に表していると言えます。
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
スキーマ変更の時間ウィンドウを設定する
スキーマ変更の処理時間ウィンドウは、ターゲットテーブルをキーに、新たに到着したスキーマと現行ターゲットテーブルのスキーマをマージした新しいスキーマを値として作成することで動作します。これを設定可能な時間間隔で繰り返します。こうすることで、異なるスキーマを持つデータが届くたびにBigQueryを更新するのではなく、ウィンドウ単位でまとめて変更を反映できます。このまとめ方式により、新しいスキーマを持つJSONオブジェクトが直近で大量に発生し、ターゲットテーブルを一斉に更新しようとする事態を防げます。並列処理によって多数の更新が同時にトリガーされうるため、こうしたまとめ処理が必要になるのです。Dataflowでこれを実現するには、Fixed Timeウィンドウを使用します。詳しくはBeamの公式ドキュメントをご覧いただくか、以下の簡単な例を参考にしてください。
スキーマ変更をまとめる仕組みにより、リトライ回数は実質的に「パイプラインがターゲットテーブルのスキーマ更新を試みた回数」となります。この変更のきっかけとなったJSONオブジェクト自体は、パイプラインを何度も通過している場合もあれば、ほとんど通過していない場合もあります。大量のデータを扱う場合は、ウィンドウサイズを小さめ(1〜5)に設定してください。データ量が少なければ大きな値も使えますが、その分ターゲットテーブルの更新までに時間がかかるようになります。迷ったときは、デフォルトの3のままで問題ありません。
詳細は本プロジェクトのGitHubリポジトリをご覧ください。気に入っていただけたら、私の個人gitリポジトリもぜひチェックしてみてください。