Falls noch nicht geschehen, lesen Sie bitte zuerst Teil I dieser Serie – sonst ergibt das Folgende deutlich weniger Sinn.

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Schlechte von guten Daten trennen
Ich habe unsere Pipeline um einige Funktionen erweitert. Sie verfügt jetzt über eine konfigurierbare Zeitspanne für Wiederholungsversuche, hält den DateTime-Zeitpunkt des Dateneingangs fest (processed_timestamp) und schreibt Daten, deren Retry-Zeit abgelaufen ist, in eine "Bad Data Table".
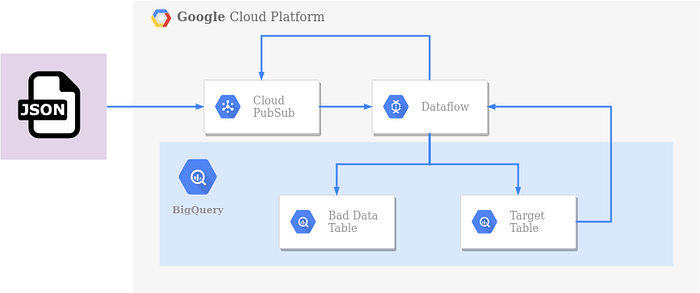
Werfen wir einen Blick auf den neuen DAG:
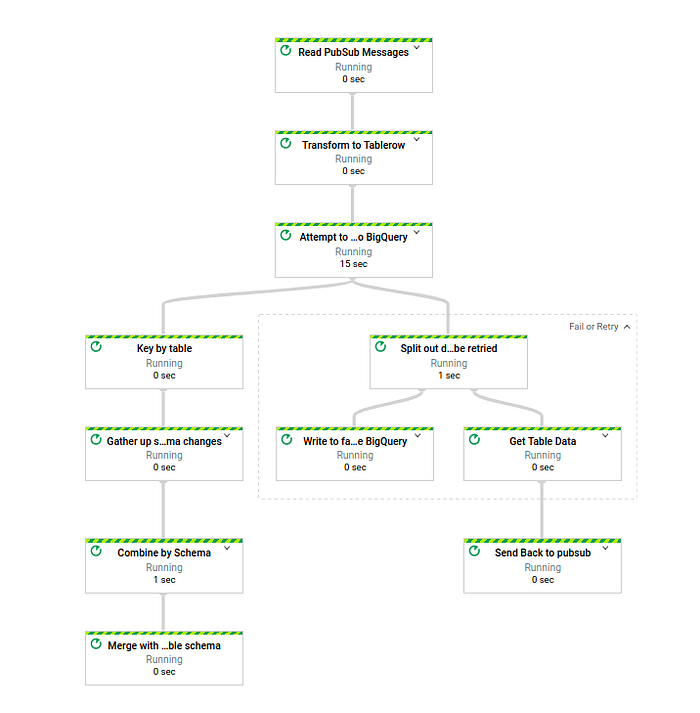
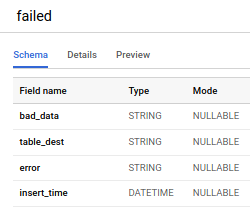
Wie Sie sehen, gibt es einen neuen Schritt, der die Daten in zwei Gruppen aufteilt: Daten, die erneut verarbeitet werden, und Daten, die in die Bad Data Table geschrieben werden. Die Bad Data Table enthält die ursprünglichen Daten (bad_data), die Zieltabelle in BigQuery (target_dest), den konkreten Fehler, an dem der Datensatz gescheitert ist (error), sowie den Zeitpunkt, zu dem der Datensatz in die Bad Data Table eingefügt wurde (insert_time).
So funktioniert der Retry-Mechanismus
Der Retry-Mechanismus arbeitet mit einem Integer-Wert, der festlegt, wie viele Minuten lang eine Nachricht erneut verarbeitet werden darf. Bei jedem Wiederholungsversuch wird die in der Nachricht hinterlegte Retry-Nummer aktualisiert. Dieser Wert entspricht der Differenz in Minuten zwischen dem ursprünglichen Empfangszeitpunkt (processed_timestamp) und der aktuellen Zeit, geteilt durch die Größe des Verarbeitungs-Zeitfensters in Minuten. So erhalten wir die Anzahl der Versuche, das Schema in der BigQuery-Zieltabelle zu migrieren.
Eine Einschränkung: Die Nachricht kann den Retry-Schritt zwar mehr als einmal durchlaufen haben, doch aufgrund des festen Verarbeitungs-Zeitfensters wurde nur eine begrenzte Anzahl an Migrationsversuchen unternommen. Der Wert spiegelt also korrekt wider, wie oft versucht wurde, das Schema der Zieltabelle anzupassen.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Ein Zeitfenster für Schemaänderungen festlegen
Das Verarbeitungs-Zeitfenster für Schemaänderungen erzeugt einen Key für die Zieltabelle und einen Value, der dem zusammengeführten neuen Schema entspricht – also der Vereinigung des eingehenden Schemas mit dem aktuellen Schema der Zieltabelle. Das geschieht in einem konfigurierbaren Zeitintervall. So wird vermieden, dass BigQuery für jeden einzelnen Datensatz mit abweichendem Schema aktualisiert wird; stattdessen werden die Änderungen in einem Fenster gebündelt. Dieses Bündeln verhindert, dass eine große Zahl kürzlich eingegangener JSON-Objekte – allesamt mit neuem Schema – gleichzeitig versucht, die Zieltabelle zu aktualisieren. Da vieles parallel abläuft, können sehr viele Updates gleichzeitig ausgelöst werden – daher die Bündelung. In Dataflow lässt sich das über ein Fixed Time Window umsetzen. Mehr dazu in der offiziellen Dokumentation von Beam – oder im einfachen Beispiel unten.
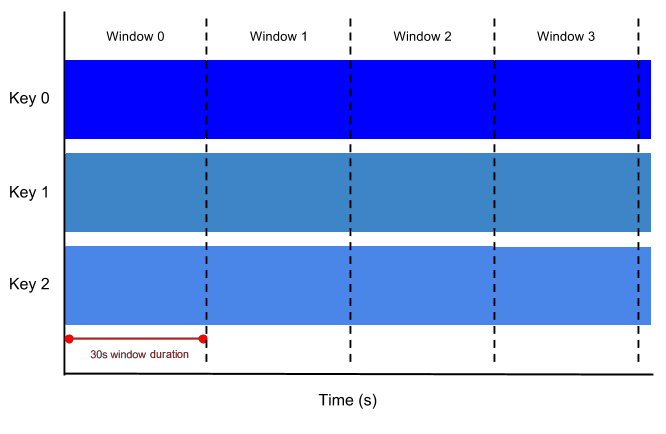
Durch das Bündeln von Schemaänderungen entspricht die Retry-Nummer effektiv der Anzahl der Versuche, mit denen die Pipeline das Schema der Zieltabelle aktualisieren wollte. Das auslösende JSON-Objekt kann die Pipeline viele Male oder auch nur wenige Male durchlaufen haben. Bei großen Datenmengen sollten Sie die Fenstergröße kleiner wählen (1–5). Bei kleineren Datenmengen darf das Fenster natürlich größer sein – allerdings verlängert ein größeres Fenster die Zeit, bis die Zieltabelle aktualisiert wird. Im Zweifelsfall bleiben Sie beim Standardwert 3.
Weitere Informationen finden Sie im GitHub-Repository dieses Projekts. Wenn Ihnen das Projekt gefällt, schauen Sie gerne auch in meinem persönlichen Git-Repository vorbei.