Se você ainda não leu, dê uma olhada na parte I desta série — caso contrário, o que vem a seguir vai fazer bem menos sentido.

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Separando os dados ruins dos bons
Adicionei alguns recursos novos ao nosso pipeline. Agora ele tem um tempo configurável para tentativas de retry, registra o DateTime em que os dados foram recebidos (processed_timestamp) e joga em uma "tabela de dados ruins" tudo o que ultrapassa o tempo de retry.
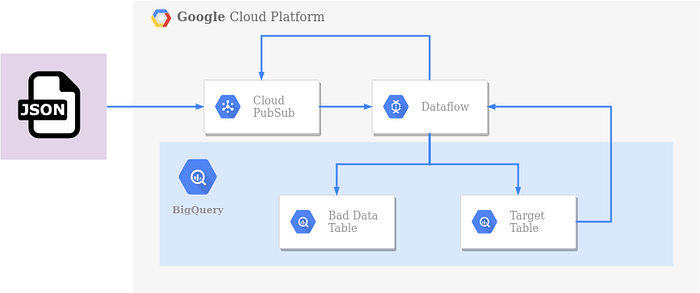
Vamos ver como ficou o novo DAG:
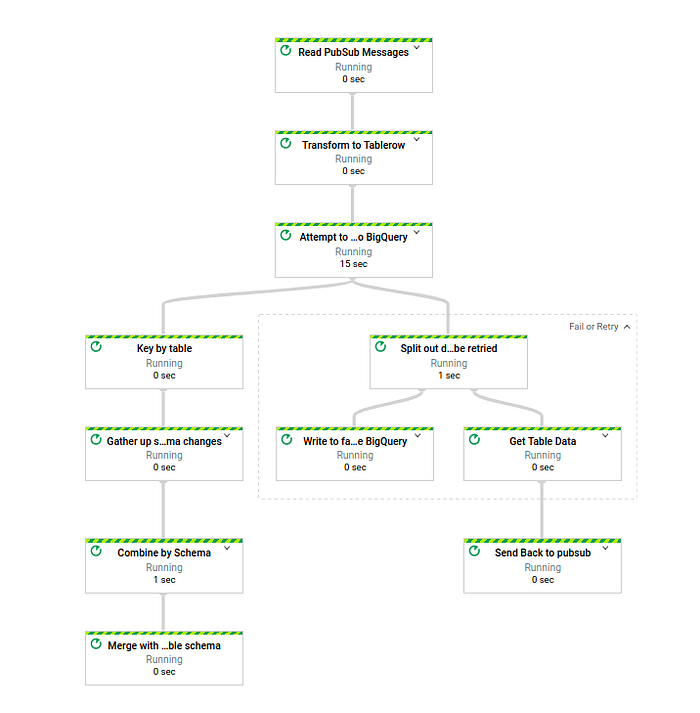
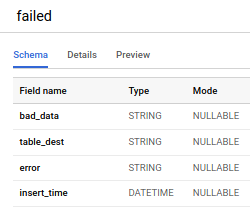
Como você pode ver, há uma nova etapa que separa os dados em dois grupos: os que serão reprocessados e os que vão para a "tabela de dados ruins". Essa tabela contém os dados originais, bad_data; a tabela de destino no BigQuery, target_dest; o erro específico que aquele dado gerou, error; e o momento em que o dado foi inserido na tabela de dados ruins, insert_time.
Como funciona o mecanismo de retry
O mecanismo de retry funciona assim: você define um número inteiro com a quantidade de minutos em que uma mensagem pode ser reprocessada. Sempre que isso acontece, o número de retry guardado na mensagem é atualizado. Esse valor atualizado é igual à diferença, em minutos, entre o horário de recebimento original (processed_timestamp) e o horário atual, dividida pelo tamanho, em minutos, da janela de tempo de processamento. Na prática, isso mostra quantas vezes tentamos migrar o schema na tabela de destino do BigQuery.
Vale uma ressalva: a mensagem pode ter passado pela etapa de retry mais de uma vez. Mas, como a tentativa de migração só ocorreu um número fixo de vezes por causa da janela de tempo de processamento, esse valor representa com precisão quantas vezes se tentou alterar o schema da tabela de destino.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Defina uma janela de tempo para mudanças de schema
A janela de tempo de processamento para mudanças de schema funciona criando uma chave (referente à tabela de destino) e um valor que é o novo schema combinado — ou seja, a mescla do schema novo que está chegando com o schema atual da tabela de destino. Isso acontece em um intervalo de tempo configurável. Assim, em vez de atualizar o BigQuery a cada dado com um schema diferente, trabalhamos com uma janela combinada de mudanças. Essa janela combinada evita situações em que um grande número de objetos JSON recentes, todos com um novo schema, tenta atualizar a tabela de destino ao mesmo tempo. Como tudo acontece em paralelo, muitas atualizações podem ser disparadas — daí a necessidade de combiná-las. Para isso, no Dataflow usamos uma Fixed Time window. Saiba mais na documentação oficial do Beam ou veja abaixo um exemplo simples.
Considerando o agrupamento das mudanças de schema, o número de retry corresponde, na prática, à quantidade de vezes que o pipeline tentou atualizar o schema da tabela de destino. O objeto JSON que disparou essa mudança pode ter passado pelo pipeline várias vezes ou pouquíssimas vezes. Se o pipeline lida com um grande volume de dados, defina um tamanho de janela menor (1–5). Com um volume menor de dados, dá para usar uma janela maior — mas lembre-se: quanto maior a janela, mais tempo leva para atualizar a tabela de destino. Na dúvida, fique com o valor padrão de 3.
Mais informações no repositório do projeto no GitHub. Se você curtiu este projeto, dá uma olhada também no meu repositório git pessoal.