Si aún no la leíste, te recomendamos revisar la parte I de esta serie; de lo contrario, lo que sigue tendrá mucho menos sentido.

PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Cómo separar los datos malos de los buenos
Le sumé algunas funcionalidades nuevas a nuestro pipeline. Ahora tiene un tiempo configurable para los reintentos, registra el DateTime en que se recibieron los datos (processed_timestamp) y vuelca los datos que superaron el tiempo de reintento en una "tabla de datos malos".
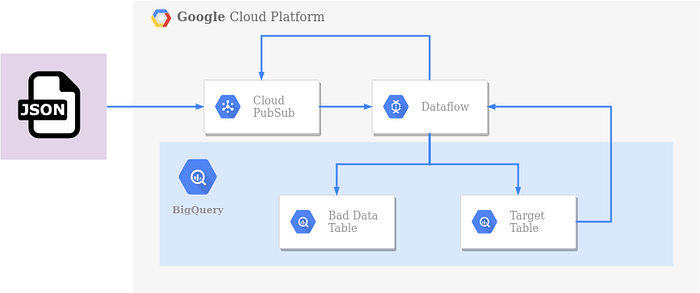
Veamos cómo se ve el nuevo DAG:
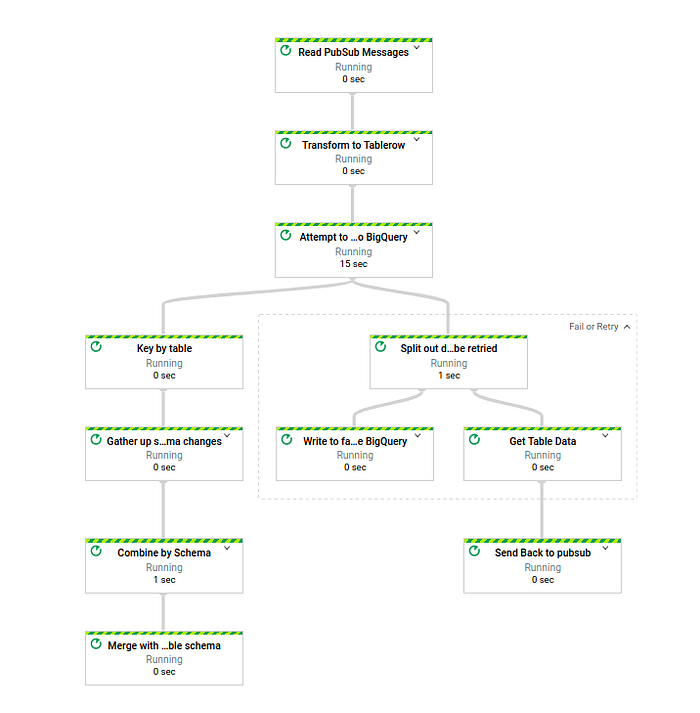
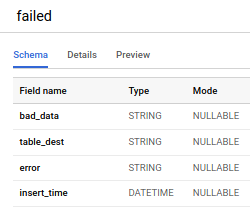
Como puedes ver, se agregó un paso que divide los datos en dos grupos: los que se reintentarán y los que se volcarán en la "tabla de datos malos". Esta tabla contiene los datos originales (bad_data); la tabla de destino en BigQuery (target_dest); el error específico con el que falló ese dato (error); y la hora en que se insertó en la tabla de datos malos (insert_time).
Cómo funciona el mecanismo de reintentos
El mecanismo de reintentos funciona definiendo un número entero que indica durante cuántos minutos se puede reintentar un mensaje. Cada vez que se reintenta, se actualiza el número de reintento almacenado en el mensaje. Ese número actualizado equivale a la diferencia en minutos entre la hora original de recepción (processed_timestamp) y la hora actual, dividida por el tamaño en minutos de la ventana de tiempo procesada. En la práctica, esto nos da la cantidad de veces que se intentó migrar el esquema en la tabla de destino de BigQuery.
Una salvedad: el mensaje puede haber pasado por el paso de reintento más de una vez; sin embargo, como solo se intenta migrar una cantidad fija de veces dentro de la ventana de tiempo procesada, ese número refleja con precisión cuántas veces se intentó modificar el esquema de la tabla de destino.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Define una ventana de tiempo para los cambios de esquema
La ventana de tiempo procesada para los cambios de esquema funciona creando una clave para la tabla de destino y un valor que corresponde al nuevo esquema combinado, es decir, la fusión del nuevo esquema entrante con el esquema actual de la tabla de destino. Esto ocurre en un incremento de tiempo configurable. Así se evita actualizar BigQuery con cada dato que tenga un esquema distinto y, en su lugar, se aplica una ventana combinada de cambios. Esta ventana combinada evita situaciones en las que una gran cantidad de objetos JSON recientes, todos con un nuevo esquema, intenten actualizar la tabla de destino al mismo tiempo. Como los procesos ocurren en paralelo, se pueden disparar muchas actualizaciones, de ahí la importancia de combinarlas. Para lograrlo en Dataflow se usa una ventana de tiempo fija (Fixed Time). Puedes leer sobre ellas en la documentación oficial de Beam o revisar el ejemplo sencillo a continuación.
Dado que los cambios de esquema se agrupan, el número de reintento equivale, en la práctica, a la cantidad de veces que el pipeline intentó actualizar el esquema de la tabla de destino. El objeto JSON que dispara este cambio pudo haber recorrido el pipeline muchas veces o casi ninguna. Si el pipeline procesa grandes volúmenes de datos, te recomendamos configurar un tamaño de ventana más chico (1–5). Con un volumen menor puedes usar un tamaño de ventana más grande, aunque ten en cuenta que esto aumentará el tiempo necesario para actualizar la tabla de destino. Si tienes dudas, quédate con el valor por defecto de 3.
Encontrarás más información en el repositorio de GitHub de este proyecto. Y si te gusta, pásate por mi repositorio personal.