En bref : un fournisseur de données confronté à des requêtes COUNT(DISTINCT) massives sur 6,5 To a trouvé la parade en implémentant HyperLogLog (HLL). Ensemble, nous avons obtenu :
- Une baisse drastique des coûts : consommation de slots BigQuery ramenée de 2 000 slots on-demand à 135 seulement, sans avoir à acheter de slots réservés supplémentaires.
- Des performances éclair : temps de requête passés de plusieurs heures à 7 secondes.
- Un passage à l'échelle maîtrisé : volume scanné réduit de 6,5 To à 16,25 Go par requête, sans perte de précision.
- Une croissance pérenne : la nouvelle approche HLL continue de tenir la charge à mesure que les volumes de données augmentent.
Comprendre le comportement unique des clients est essentiel pour les acteurs de l'e-commerce, du marketing digital et des services de données. L'un de nos clients, un grand fournisseur de données, suit les interactions utilisateurs uniques sur des fenêtres glissantes de 30 jours pour alimenter ses campagnes marketing et ses recommandations produit.
Mais à mesure que ses données ont atteint plusieurs milliards d'enregistrements, les requêtes COUNT(DISTINCT) qu'il utilisait pour analyser le comportement utilisateur se sont mises à durer des heures, devenant exponentiellement plus coûteuses — quand elles n'échouaient pas purement et simplement.
Ce qui n'était au départ qu'une tâche analytique ordinaire s'est mué en un défi technique majeur, menaçant sa capacité à prendre des décisions éclairées.
Dans cet article, je décrypte :
- Pourquoi la fonction COUNT(DISTINCT) devient gourmande en calcul à grande échelle.
- L'impact sur les performances et les coûts des requêtes (notre client scannait 6,5 To de données à chaque requête !).
- Comment nous avons résolu ce problème avec HyperLogLog (HLL), en faisant passer les temps de requête de plusieurs heures à quelques secondes et en réduisant la consommation de ressources de 93 %.

Hyper City
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Le problème de COUNT(DISTINCT) à grande échelle
COUNT DISTINCT permet de compter le nombre de valeurs uniques dans une colonne donnée, mais dès que le volume de données entre en jeu, les performances se dégradent : la requête doit traiter l'intégralité du jeu de données à chaque exécution.
Prenons un exemple simple :
- Données du jour 1
Utilisateur A connecté
Utilisateur B connecté
Utilisateur C connecté
COUNT DISTINCT = 3 utilisateurs
- Données du jour 2
Utilisateur B connecté
Utilisateur C connecté
Utilisateur D connecté
COUNT DISTINCT = 3 utilisateurs
Si vous additionniez ces totaux journaliers (3+3=6) pour obtenir le nombre d'utilisateurs uniques sur deux jours, le résultat serait faux : les utilisateurs B et C seraient comptés deux fois.
De nombreuses fonctions d'agrégation — comme SUM — peuvent elles-mêmes être agrégées, mais ce n'est pas le cas de COUNT DISTINCT. Pour obtenir le nombre exact de valeurs distinctes, il faut combiner les données des deux jours, puis appliquer COUNT DISTINCT à l'ensemble fusionné.
Étude de cas : quand des requêtes COUNT(DISTINCT) sur 6,5 To deviennent intenables
Notre client n'avait pas d'autre choix que de parcourir l'ensemble des données brutes chaque jour, sur une fenêtre glissante de 30 jours. Cela impliquait d'interroger une table massive de 18 570 335 647 enregistrements (après filtrage par partition) — soit environ 6,5 To scannés à chaque exécution !
Un véritable goulot d'étranglement opérationnel :
- Forte consommation de slots : les 2 000 slots étaient rapidement saturés, atteignant le quota BigQuery pour les jobs on-demand et provoquant l'échec du job.
- Temps d'exécution interminables : lorsque le job ne plantait pas, il tournait pendant plusieurs heures. Les données n'étaient donc pas disponibles à temps pour les décideurs.
- Requêtes coûteuses : recalculer COUNT(DISTINCT) chaque jour en scannant des milliards d'enregistrements à répétition se traduisait par une facture salée.
Il est rapidement devenu évident qu'il n'était plus viable de poursuivre avec cette approche COUNT DISTINCT.
Comment HLL approxime les comptages uniques dans BigQuery
C'est ici qu'entre en scène HyperLogLog (HLL). HLL est un algorithme probabiliste qui permet d'estimer le nombre d'éléments distincts dans un jeu de données. Plutôt que de recalculer le nombre exact d'éléments distincts, HLL fournit une approximation très précise tout en consommant nettement moins de ressources.
BigQuery propose cette fonctionnalité via la fonction APPROX_COUNT_DISTINCT, basée sur HLL. Cette approximation s'est révélée suffisamment précise pour les besoins du client, et le compromis sur la précision était largement compensé par les gains en vitesse et en coût.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Gains rapides : implémenter HLL via APPROX\_COUNT\_DISTINCT
Requête COUNT(DISTINCT) classique
Voici à quoi ressemble une requête COUNT(DISTINCT) typique sur 30 jours :
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Cette requête calcule le nombre d'utilisateurs distincts sur les 30 derniers jours, mais à chaque nouvelle exécution, elle ne tire aucun parti des résultats déjà obtenus précédemment, ce qui peut être lent et coûteux.
Requête optimisée avec APPROX_COUNT_DISTINCT
En utilisant HLL via la fonction APPROX_COUNT_DISTINCT de BigQuery, on obtient les mêmes résultats bien plus vite et à moindre coût :
SELECT
APPROX_COUNT_DISTINCT(user_id) AS approx_unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Toutefois, même avec APPROX_COUNT_DISTINCT, on continue de scanner 30 jours de données à chaque requête. C'est là qu'interviennent les sketches HLL : ils permettent de pré-calculer et de stocker des résumés journaliers que l'on peut ensuite combiner efficacement.
Sketches HLL BigQuery : la méthode d'agrégation journalière avancée
Les sketches HLL sont des structures de données compactes qui s'appuient sur le hachage pour résumer l'information. Au lieu de conserver la liste complète des visites utilisateurs (qui peut représenter des millions d'enregistrements), vous stockez une représentation compressée de quelques kilo-octets — le sketch — qui pourra ensuite servir à estimer les comptages distincts sur plusieurs périodes.
Pour notre client, nous avons mis en place des sketches HLL journaliers :
- Chaque jour, le système générait un sketch HLL résumant les groupes d'utilisateurs uniques selon les valeurs pertinentes pour ses besoins.
- Ces sketches étaient ensuite agrégés pour calculer les utilisateurs distincts sur n'importe quelle période, par exemple les 30 derniers jours, sans avoir à tout recalculer depuis le début.
C'est tout l'intérêt de cette approche : les sketches HLL peuvent être combinés efficacement sur plusieurs périodes sans introduire d'erreurs de double comptage et sans nécessiter un scan complet des données. Notre client a ainsi pu interroger les comptages d'utilisateurs uniques sur 30 jours en n'utilisant qu'une fraction des ressources et du temps habituels.
Exemple de requête : créer des sketches HLL journaliers
Voici comment stocker des sketches HLL journaliers dans BigQuery :
CREATE OR REPLACE TABLE project.dataset.daily_sketches AS
SELECT
event_date,
HLL_COUNT.INIT(user_id) AS hll_sketch
FROM
project.dataset.user_interactions
GROUP BY
event_date;
Cette requête crée une table journalière de sketches HLL, un par jour, qui résume les utilisateurs distincts de la table user_interactions.
Agréger les sketches HLL sur des fenêtres de 30 jours
SELECT
HLL_COUNT.MERGE(hll_sketch) AS approx_unique_users
FROM
project.dataset.daily_sketches
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Ici, nous utilisons HLL_COUNT.MERGE pour combiner les sketches HLL journaliers, ce qui permet d'estimer le nombre d'utilisateurs distincts sur l'ensemble de la période de 30 jours sans tout recalculer.
HLL sur BigQuery : les résultats concrets
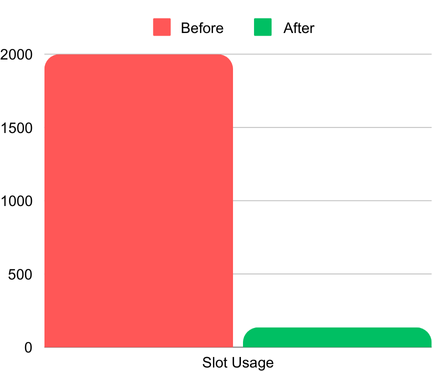
L'utilisation des slots avant et après l'adoption des sketches HLL. (les 2 000 slots représentent l'allocation maximale ; la consommation réelle avant HLL était bien supérieure)
Gains de performance
Le passage aux sketches HLL a apporté un avantage majeur à notre client :
- Coûts de requête réduits : au départ, la requête saturait les 2 000 slots alloués sous le modèle on-demand. La seule alternative aurait été d'acheter des slots réservés supplémentaires (BigQuery Editions), au prix d'une hausse considérable de la facture. Après la mise en place des sketches HLL et la création d'une table d'agrégation, la consommation de slots est tombée à 135, faisant chuter à la fois les temps et les coûts de requête.
- Requêtes plus rapides : les temps d'exécution sont passés de plusieurs heures à quelques secondes (7 secondes), permettant au client de générer ses rapports plus vite et de répondre à ses besoins de décision en temps réel.
- Scalabilité : à mesure que le jeu de données grandissait, l'approche HLL a continué de tenir la charge sans nécessiter de scans complets ni de recalculs, gardant les coûts sous contrôle.
- Précision suffisante : bien que HLL fournisse une approximation des données de visiteurs uniques, le client a constaté que la précision configurable dépassait largement ses besoins de reporting, sans impact perceptible sur ses résultats métier.
Réduction des coûts
Les résultats sont sans appel :
- Performances (temps d'exécution) améliorées de plus de 99 %.
- Slots : la consommation par requête est passée de plus de 2 000 slots à 135 seulement.
- Temps : les temps de requête pour les comptages distincts sur 30 jours sont passés de plusieurs heures à quelques secondes.
- Données scannées : de 6,5 To par requête à 16,25 Go.
- Économies réalisées : le client a réduit le nombre de slots consommés et le volume de données scannées par requête, et l'achat de slots supplémentaires n'a plus été nécessaire après l'implémentation.
- Décisions data-driven plus efficaces : grâce à un accès plus rapide aux insights clés, le client a pu réagir au comportement des utilisateurs et ajuster ses stratégies marketing avec bien plus d'agilité.
Pour les entreprises confrontées à des goulots d'étranglement lors du comptage de valeurs uniques avec COUNT(DISTINCT) dans BigQuery — en particulier sur de grands jeux de données et de longues périodes — les sketches HLL offrent une solution d'une grande efficacité. En passant à des comptages distincts approximés et en stockant des sketches journaliers, vous réduisez sensiblement les coûts de requête et améliorez les performances de plus de 99 %, comme le démontre cet exemple concret.
Si votre activité repose sur un reporting de comptages distincts rapide et économique, adoptez HLL et constatez par vous-même des améliorations comparables dans vos workflows de données.
Vous cherchez à optimiser votre consommation cloud, vos coûts et — surtout — votre temps ? Contactez-nous et explorons ensemble comment transformer vos défis data en leviers de croissance.