TL;DR: Un proveedor de datos que lidiaba con consultas masivas de COUNT(DISTINCT) sobre 6.5TB de información encontró una salida implementando HyperLogLog (HLL). Trabajando en conjunto, conseguimos:
- Reducción drástica de costos: el uso de slots de BigQuery bajó de 2,000 slots on-demand a apenas 135, sin necesidad de comprar slots reservados adicionales.
- Rendimiento ultrarrápido: los tiempos de consulta se desplomaron de horas a apenas 7 segundos.
- Escalamiento eficiente: el escaneo de datos se redujo de 6.5TB a 16.25GB por consulta, sin sacrificar precisión.
- Crecimiento sostenible: el nuevo enfoque basado en HLL sigue escalando con eficiencia a medida que crece el volumen de datos.
Entender el comportamiento único de los clientes es clave para que las empresas de e-commerce, marketing digital y servicios de datos tengan éxito. Uno de los clientes con los que trabajé, un gran proveedor de datos, hace seguimiento de las interacciones únicas de usuarios en ventanas de 30 días para potenciar sus campañas de marketing y recomendaciones de producto.
Sin embargo, a medida que sus datos crecieron a miles de millones de registros, las consultas COUNT(DISTINCT) que ejecutaban para entender ese comportamiento empezaron a tardar horas, se volvieron exponencialmente más costosas y, por momentos, fallaban por completo.
Lo que comenzó como una tarea de analítica sencilla se transformó en un desafío técnico considerable que amenazaba con afectar su capacidad de tomar decisiones.
En este post voy a desglosar:
- Por qué la función COUNT(DISTINCT) se vuelve costosa en términos computacionales a gran escala.
- Cómo esto afecta el rendimiento y los costos de las consultas (¡nuestro cliente escaneaba 6.5TB de datos en cada consulta!).
- Cómo lo resolvimos con HyperLogLog (HLL), reduciendo los tiempos de consulta de horas a segundos y recortando el uso de recursos en 93%.

Hyper City
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
El problema de COUNT(DISTINCT) a gran escala
Si bien COUNT DISTINCT permite contar la cantidad de valores únicos dentro de una columna específica, cuando entra en juego la escala de los datos surgen problemas de rendimiento, ya que la consulta tiene que procesar todo el dataset en cada ejecución.
Veamos un ejemplo simple:
- Datos del Día 1
Usuario A visitó
Usuario B visitó
Usuario C visitó
COUNT DISTINCT = 3 usuarios
- Datos del Día 2
Usuario B visitó
Usuario C visitó
Usuario D visitó
COUNT DISTINCT = 3 usuarios
Si sumaras estos conteos diarios (3+3=6) para obtener el total de usuarios únicos en dos días, te equivocarías, porque los Usuarios B y C se contarían dos veces.
Aunque muchas funciones de agregación —como SUM— se pueden volver a agregar, COUNT DISTINCT no. Para determinar correctamente el total de valores distintos habría que combinar los datos de ambos días y recién entonces aplicar la función COUNT DISTINCT al conjunto completo.
Caso de estudio: cuando las consultas COUNT(DISTINCT) sobre 6.5TB se volvieron insostenibles
En el caso de nuestro cliente, no había más opción que revisar todos los datos en bruto cada día sobre una ventana móvil de 30 días. Esto implicaba consultar una tabla enorme con 18,570,335,647 registros (después del filtrado por partición), aproximadamente un escaneo de 6.5 TB cada vez.
Esto generó un cuello de botella en sus operaciones:
- Alto consumo de slots: agotaban rápidamente los 2,000 slots, alcanzando la cuota de slots de BigQuery para trabajos on-demand y haciendo que el job fallara.
- Tiempos de ejecución prolongados: si el job no fallaba, tardaba horas en correr. Esto significaba que sus datos no estaban disponibles a tiempo para quienes tomaban decisiones.
- Consultas costosas: recalcular COUNT(DISTINCT) todos los días y escanear miles de millones de registros una y otra vez tenía, naturalmente, un precio elevado.
Como resultado, nos quedó claro que no era viable seguir con este enfoque de COUNT DISTINCT.
Cómo BigQuery HLL aproxima los conteos únicos
Aquí entra en escena HyperLogLog (HLL). HLL es un algoritmo probabilístico que permite estimar la cantidad de elementos distintos en un dataset. En lugar de recalcular la cifra exacta, HLL ofrece una aproximación muy precisa que consume muchísimos menos recursos.
BigQuery expone esta funcionalidad mediante la función APPROX_COUNT_DISTINCT, basada en HLL. Esta aproximación era lo bastante precisa para las necesidades del cliente, y la pequeña pérdida de exactitud quedó más que compensada por las mejoras sustanciales en velocidad y costo.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Ganancias rápidas: implementar HLL con APPROX\_COUNT\_DISTINCT
Consulta estándar con COUNT(DISTINCT)
Veamos cómo se vería una consulta típica de COUNT(DISTINCT) sobre 30 días:
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Esta consulta calcula los usuarios distintos de los últimos 30 días, pero en la siguiente ejecución no se aprovechan los resultados que ya obtuvimos en la corrida anterior, lo que puede ser lento y costoso.
Consulta optimizada con HLL usando APPROX_COUNT_DISTINCT
Al usar HLL mediante la función APPROX_COUNT_DISTINCT en BigQuery, los resultados se obtienen mucho más rápido y a menor costo:
SELECT
APPROX_COUNT_DISTINCT(user_id) AS approx_unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Sin embargo, incluso con APPROX_COUNT_DISTINCT, seguimos escaneando 30 días de datos en cada consulta. Aquí es donde entran los sketches de HLL: permiten precalcular y almacenar resúmenes diarios que después se pueden combinar de forma eficiente.
Sketches de BigQuery HLL: método avanzado de agregación diaria
Los sketches de HLL son estructuras de datos compactas que usan hashing para resumir información. En lugar de guardar una lista con cada visita individual de usuario (que pueden ser millones de registros), se almacena una representación comprimida de unos pocos kilobytes —el sketch— que después puede usarse para estimar conteos distintos a lo largo de varios períodos de tiempo.
En el caso de nuestro cliente, lo ayudamos a crear sketches HLL diarios:
- Cada día, el sistema generaba un sketch HLL que resumía los grupos únicos de usuarios por valores, según las necesidades del cliente.
- Esos sketches después se agregaban para calcular los usuarios distintos en cualquier rango de tiempo —por ejemplo, los últimos 30 días— sin recalcular todo desde cero.
Esa agregación es el beneficio clave: los sketches HLL se combinan de forma eficiente a lo largo de períodos de tiempo, sin introducir errores por doble conteo ni requerir un escaneo completo de los datos. Esto le permitió a nuestro cliente consultar conteos de usuarios únicos sobre 30 días usando una fracción de los recursos y del tiempo.
Consulta de ejemplo: crear sketches HLL diarios
Así puedes almacenar sketches HLL diarios en BigQuery:
CREATE OR REPLACE TABLE project.dataset.daily_sketches AS
SELECT
event_date,
HLL_COUNT.INIT(user_id) AS hll_sketch
FROM
project.dataset.user_interactions
GROUP BY
event_date;
En esta consulta creamos una tabla diaria de sketches HLL —uno por cada día— que resume los usuarios distintos de la tabla user_interactions.
Agregación de sketches HLL en ventanas de 30 días
SELECT
HLL_COUNT.MERGE(hll_sketch) AS approx_unique_users
FROM
project.dataset.daily_sketches
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Aquí usamos HLL_COUNT.MERGE para combinar los sketches HLL diarios, lo que nos permite estimar el conteo de usuarios distintos a lo largo de los 30 días sin recalcular desde cero.
Resultados reales con BigQuery HLL
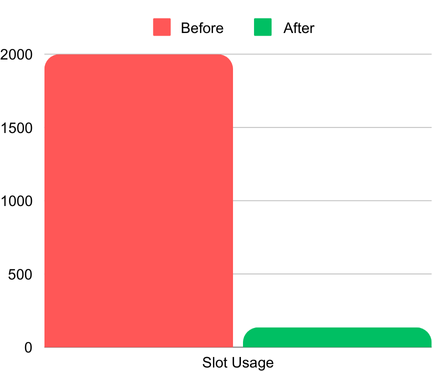
Utilización de slots antes y después de usar sketches HLL. (Los 2K slots representan la asignación máxima; el consumo real antes de HLL era mucho mayor).
Mejoras de rendimiento
El cambio a sketches HLL trajo una ventaja enorme para nuestro cliente:
- Menores costos de consulta: al inicio, la consulta consumía la totalidad de los 2,000 slots asignados bajo el modelo on-demand. La alternativa del cliente era comprar slots reservados adicionales (BigQuery Editions), lo que habría aumentado significativamente sus costos. Sin embargo, tras implementar sketches HLL y crear una tabla agregada, el consumo de slots cayó a apenas 135, reduciendo drásticamente tanto el tiempo como el costo de las consultas.
- Consultas más rápidas: los tiempos pasaron de horas a segundos (7 segundos), lo que le permitió al cliente generar reportes más rápido y atender necesidades de toma de decisiones en tiempo real.
- Escalabilidad: a medida que el dataset creció, el enfoque basado en HLL siguió escalando sin necesidad de escaneos completos de tabla ni recálculos, manteniendo los costos bajos.
- Lo suficientemente preciso: aunque HLL ofrece una aproximación de los datos de visitantes únicos, el cliente comprobó que la precisión configurable era más que suficiente para sus necesidades de reporte, sin un impacto perceptible en los resultados del negocio.
Reducción de costos
Los resultados fueron contundentes:
- El rendimiento (tiempo de ejecución) mejoró más de 99%.
- Slots: el consumo de slots por consulta se redujo de más de 2,000 a apenas 135.
- Tiempo: los tiempos de consulta para conteos distintos sobre 30 días pasaron de varias horas a apenas segundos.
- Datos escaneados: de 6.5TB por consulta a 16.25GB.
- Ahorro en costos: el cliente logró reducir la cantidad de slots consumidos y de datos escaneados en cada consulta y, tras la implementación, ya no fue necesario comprar slots.
- Mejor toma de decisiones basada en datos: con acceso más rápido a los insights clave, el cliente pudo reaccionar al comportamiento de los usuarios y ajustar sus estrategias de marketing con mucha mayor efectividad.
Para empresas que enfrentan cuellos de botella de rendimiento al contar valores únicos con consultas COUNT(DISTINCT) en BigQuery —sobre todo en datasets grandes y períodos extendidos—, los sketches HLL son una solución altamente eficiente. Al pasar a conteos distintos aproximados y almacenar sketches diarios, se reducen significativamente los costos de consulta y el rendimiento mejora más de 99%, como se ve en este ejemplo real.
Si tu negocio depende de reportes de conteo distinto oportunos y costo-eficientes, considera adoptar HLL y verás mejoras similares en tus flujos de datos.
Si buscas optimizar tu uso de la nube, los costos y —lo más importante— el tiempo, contáctanos y exploremos juntos cómo transformar tus desafíos de datos en oportunidades de crecimiento.