TL;DR: um provedor de dados que penava com consultas COUNT(DISTINCT) gigantescas sobre 6,5 TB encontrou alívio ao adotar o HyperLogLog (HLL). Juntos, conseguimos:
- Redução drástica de custo: derrubamos o uso de slots no BigQuery de 2.000 slots on-demand para apenas 135, sem precisar comprar slots reservados adicionais
- Performance ultrarrápida: os tempos de consulta despencaram de horas para apenas 7 segundos
- Escala eficiente: o volume de dados escaneados caiu de 6,5 TB para 16,25 GB por consulta, sem perder precisão
- Crescimento sustentável: a nova abordagem baseada em HLL continua escalando bem conforme o volume de dados aumenta
Entender o comportamento individual dos clientes é essencial para o sucesso de empresas de e-commerce, marketing digital e serviços de dados. Um dos clientes com quem eu estava trabalhando, um grande provedor de dados, monitora interações únicas de usuários em janelas de 30 dias para alimentar suas campanhas de marketing e recomendações de produtos.
No entanto, à medida que os dados cresceram para bilhões de registros, as consultas COUNT(DISTINCT) usadas para entender o comportamento dos usuários começaram a levar horas, ficando exponencialmente mais caras — e, vez ou outra, falhando por completo.
O que começou como uma tarefa simples de analytics virou um desafio técnico de peso, ameaçando a capacidade de tomada de decisão da empresa.
Neste post, vou destrinchar:
- Por que a função COUNT(DISTINCT) fica computacionalmente cara em escala
- Como isso afeta a performance e o custo das consultas (nosso cliente estava escaneando 6,5 TB de dados a cada consulta!)
- Como resolvemos isso com HyperLogLog (HLL), reduzindo o tempo de consulta de horas para segundos e cortando o uso de recursos em 93%

Hyper City
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
O problema do COUNT(DISTINCT) em escala
O COUNT DISTINCT serve para contar quantos valores únicos existem em uma coluna, mas, quando entra a escala dos dados, surgem problemas de performance — afinal, a consulta precisa processar o conjunto inteiro a cada execução.
Vamos a um exemplo simples:
- Dados do Dia 1
Usuário A acessou
Usuário B acessou
Usuário C acessou
COUNT DISTINCT = 3 usuários
- Dados do Dia 2
Usuário B acessou
Usuário C acessou
Usuário D acessou
COUNT DISTINCT = 3 usuários
Se você somasse essas contagens diárias (3+3=6) para obter o total de usuários únicos nos dois dias, o resultado estaria errado, porque os Usuários B e C seriam contados duas vezes.
Muitas funções de agregação — como SUM — podem ser agregadas novamente, mas COUNT DISTINCT não. Para chegar ao número total de valores distintos, é preciso combinar os dados dos dois dias e aplicar a função COUNT DISTINCT ao conjunto inteiro
Estudo de caso: quando consultas COUNT(DISTINCT) de 6,5 TB se tornaram insustentáveis
No caso do nosso cliente, não havia outra saída: era preciso olhar para todos os dados brutos, todos os dias, em uma janela móvel de 30 dias. Isso significava consultar uma tabela enorme com 18.570.335.647 registros (depois do filtro de partição) — algo em torno de 6,5 TB de scan a cada execução!
Isso virou um gargalo nas operações:
- Alto consumo de slots: os 2.000 slots se esgotavam rapidamente, atingindo a cota de slots do BigQuery para jobs on-demand e fazendo o job falhar.
- Tempos de execução longos: quando o job não falhava, levava horas para rodar. Ou seja, os dados não chegavam a tempo para os tomadores de decisão.
- Consultas caras: recalcular o COUNT(DISTINCT) todos os dias e escanear bilhões de registros repetidamente, naturalmente, saía caro.
Ficou claro para nós que seguir com essa abordagem de COUNT DISTINCT não era viável.
Como o HLL no BigQuery aproxima contagens únicas
É aí que entra o HyperLogLog (HLL). O HLL é um algoritmo probabilístico que permite estimar o número de elementos distintos em um conjunto de dados. Em vez de recalcular o número exato de elementos distintos, o HLL entrega uma aproximação altamente precisa usando muito menos recursos.
O BigQuery oferece essa funcionalidade pela função APPROX_COUNT_DISTINCT, baseada em HLL. Essa aproximação foi precisa o bastante para as necessidades do cliente, e o trade-off de precisão foi mais do que compensado pelos enormes ganhos em velocidade e custo.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Ganhos rápidos: implementando HLL via APPROX\_COUNT\_DISTINCT
Consulta padrão com COUNT(DISTINCT)
Veja como costuma ser uma consulta típica de COUNT(DISTINCT) sobre 30 dias:
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Essa consulta calcula os usuários distintos dos últimos 30 dias, mas, na próxima execução, não aproveitamos os resultados que já obtivemos antes — o que pode ser lento e caro.
Consulta otimizada baseada em HLL com APPROX_COUNT_DISTINCT
Usando HLL pela função APPROX_COUNT_DISTINCT no BigQuery, conseguimos resultados muito mais rápidos e baratos:
SELECT
APPROX_COUNT_DISTINCT(user_id) AS approx_unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Mesmo com APPROX_COUNT_DISTINCT, ainda escaneamos 30 dias de dados a cada consulta. É aí que entram os HLL sketches — eles permitem pré-calcular e armazenar resumos diários que podem ser combinados depois com eficiência.
HLL Sketches no BigQuery: método avançado de agregação diária
Os sketches HLL são estruturas de dados compactas que usam hashing para resumir informações. Em vez de manter uma lista com cada visita de usuário (que pode ter milhões de registros), você guarda uma representação comprimida de poucos kilobytes — o sketch — que pode ser usada depois para estimar contagens distintas em vários períodos.
No caso do nosso cliente, ajudamos a criar sketches HLL diários:
- Todos os dias, o sistema gerava um sketch HLL que resumia os grupos únicos de usuários por valores conforme as necessidades do cliente.
- Esses sketches eram então agregados para calcular usuários distintos em qualquer intervalo de tempo, como os últimos 30 dias, sem precisar recalcular tudo do zero.
Essa agregação é o grande benefício: os sketches HLL podem ser combinados com eficiência ao longo de períodos sem introduzir erros de dupla contagem nem exigir um scan completo dos dados. Foi isso que permitiu ao nosso cliente consultar contagens de usuários únicos em 30 dias usando uma fração dos recursos e do tempo.
Exemplo de consulta: criando sketches HLL diários
Veja como armazenar sketches HLL diários no BigQuery:
CREATE OR REPLACE TABLE project.dataset.daily_sketches AS
SELECT
event_date,
HLL_COUNT.INIT(user_id) AS hll_sketch
FROM
project.dataset.user_interactions
GROUP BY
event_date;
Nessa consulta, criamos uma tabela diária de sketches HLL, um para cada dia, resumindo os usuários distintos da tabela user_interactions.
Agregando sketches HLL em janelas de 30 dias
SELECT
HLL_COUNT.MERGE(hll_sketch) AS approx_unique_users
FROM
project.dataset.daily_sketches
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Aqui, usamos o HLL_COUNT.MERGE para combinar os sketches HLL diários, estimando a contagem de usuários distintos em todo o período de 30 dias sem recalcular do zero.
Resultados reais com HLL no BigQuery
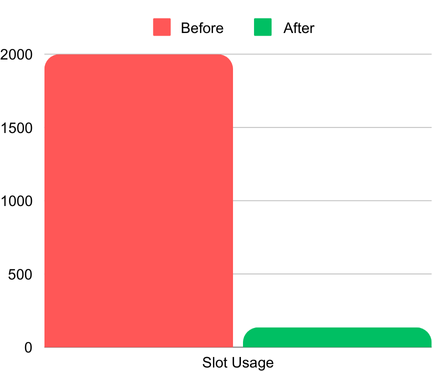
Utilização de slots antes e depois do uso de sketches HLL. (2 mil slots representam a alocação máxima; o consumo real antes do HLL era muito maior)
Ganhos de performance
A migração para sketches HLL trouxe uma vantagem enorme para o cliente:
- Custo de consulta menor: no início, a consulta consumia todos os 2.000 slots alocados no modelo on-demand. A alternativa do cliente era comprar slots reservados adicionais (BigQuery Editions), o que aumentaria bastante os custos. Depois de implementar os sketches HLL e criar uma tabela agregada, o consumo de slots caiu para apenas 135, reduzindo drasticamente tempo e custo das consultas.
- Consultas mais rápidas: os tempos de consulta caíram de horas para segundos (7 segundos), o que permitiu gerar relatórios mais rápido e atender à necessidade de decisões em tempo real.
- Escalabilidade: conforme o dataset crescia, a abordagem baseada em HLL continuava escalando sem precisar de scans completos da tabela ou recálculos, mantendo os custos baixos.
- Precisão "suficiente": embora o HLL ofereça uma aproximação dos dados de visitantes únicos, o cliente percebeu que a precisão configurável era mais do que suficiente para as necessidades de relatório, sem qualquer impacto perceptível nos resultados de negócio.
Redução de custo
Os resultados foram expressivos:
- Performance (tempo de execução) melhorou em mais de 99%.
- Slots: o consumo de slots por consulta caiu de mais de 2.000 para apenas 135.
- Tempo: o tempo de consulta para contagens distintas em 30 dias caiu de várias horas para poucos segundos.
- Dados escaneados: de 6,5 TB por consulta para 16,25 GB.
- Economia de custo: o cliente conseguiu reduzir a quantidade de slots consumidos e o volume de dados escaneados por consulta e, depois da implementação, não foi necessário comprar slots.
- Decisões mais orientadas a dados: com acesso mais rápido a insights-chave, o cliente pôde reagir ao comportamento dos usuários e ajustar suas estratégias de marketing com muito mais eficácia.
Para empresas que enfrentam gargalos de performance ao contar valores únicos com consultas COUNT(DISTINCT) no BigQuery — especialmente em datasets grandes e períodos longos — os sketches HLL são uma solução altamente eficiente. Ao migrar para contagens distintas aproximadas e armazenar sketches diários, dá para reduzir bastante os custos das consultas e turbinar a performance em mais de 99%, como mostra esse caso real.
Se o seu negócio depende de relatórios de contagem distinta ágeis e econômicos, vale considerar a adoção do HLL para alcançar melhorias parecidas nos seus fluxos de dados.
Se você quer otimizar o uso da nuvem, o custo e — o mais importante — o tempo, entre em contato com a gente e vamos explorar juntos como transformar seus desafios de dados em oportunidades de crescimento.