要点:6.5TB規模のデータに対する巨大なCOUNT(DISTINCT)クエリに苦しんでいたあるデータプロバイダーが、HyperLogLog(HLL)の導入によって課題を解決しました。協働の成果は次のとおりです。
- 大幅なコスト削減:BigQueryのスロット使用量をオンデマンド2,000スロットからわずか135スロットへ縮小し、追加の予約スロット購入が不要に
- 圧倒的な高速化:クエリ時間が数時間からわずか7秒に短縮
- 効率的なスケーリング:1クエリあたりのスキャン量を6.5TBから16.25GBへ削減しつつ精度を維持
- 持続的な成長性:新しいHLLベースの手法は、データ量の増加にも効率的にスケール
ユニークな顧客行動を把握することは、Eコマース、デジタルマーケティング、データサービス分野の企業が成功するうえで欠かせません。私が担当していたあるお客様(大手データプロバイダー)は、マーケティング施策や商品レコメンドのため、30日間のウィンドウでユニークユーザーのインタラクションを追跡していました。
ところがデータが数十億レコードに膨らむにつれ、ユニークユーザー行動を把握するためのCOUNT(DISTINCT)クエリは完了までに数時間を要するようになり、コストも指数関数的に増大。ときにはクエリ自体が失敗することもありました。
当初は単純な分析タスクだったものが、意思決定の足かせになりかねない深刻な技術課題へと変貌したのです。
本記事では次のポイントを解説します。
- なぜCOUNT(DISTINCT)関数は大規模データになると計算コストが跳ね上がるのか
- それがクエリのパフォーマンスとコストにどう響くのか(このお客様はクエリごとに6.5TBものデータをスキャンしていました!)
- HyperLogLog(HLL)でどのように解決し、クエリ時間を数時間から数秒へ、リソース消費を93%削減したのか

Hyper City
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
大規模データにおけるCOUNT(DISTINCT)の課題
COUNT DISTINCTは指定したカラム内のユニーク値の数を数えるのに便利な関数ですが、データ規模が大きくなると、実行のたびにデータセット全体を処理する必要があるためパフォーマンス問題が顕在化します。
簡単な例で見てみましょう。
- 1日目のデータ
User A が訪問
User B が訪問
User C が訪問
COUNT DISTINCT = 3 users
- 2日目のデータ
User B が訪問
User C が訪問
User D が訪問
COUNT DISTINCT = 3 users
日次のカウントを単純に足し合わせて(3+3=6)2日間のユニークユーザー総数を求めようとすると、User BとUser Cが二重に数えられるため正しい結果になりません。
SUMのように再集計が可能な集計関数も多くありますが、COUNT DISTINCTはそうはいきません。ユニーク値の総数を正しく求めるには、両日のデータを結合したうえで、結合後のデータセット全体に対してCOUNT DISTINCTを適用する必要があります。
事例:6.5TB規模のCOUNT(DISTINCT)クエリが立ち行かなくなったとき
このお客様のケースでは、ローリング30日間にわたって毎日すべての生データを参照する以外に選択肢がありませんでした。18,570,335,647レコード(パーティションフィルタ後)の巨大なテーブルを毎回クエリし、約6.5TBをスキャンする運用です。
これが業務のボトルネックになっていました。
- スロットの大量消費:2,000スロットをすぐに使い切ってBigQueryのオンデマンドジョブのスロットクォータに達し、ジョブが失敗していました。
- 長いクエリ実行時間:失敗を免れた場合でも実行に数時間を要し、意思決定者に必要なタイミングでデータを届けられませんでした。
- 高コストなクエリ:毎日COUNT(DISTINCT)を再計算し、何十億ものレコードを繰り返しスキャンするため、当然ながら高額な費用が発生していました。
こうした状況から、COUNT DISTINCTのアプローチを続けるのは現実的でないことが明らかになりました。
BigQuery HLLによるユニークカウント近似の仕組み
そこで登場するのがHyperLogLog(HLL)です。HLLはデータセット内のユニーク要素数を推定する確率的アルゴリズムで、正確なユニーク数を毎回再計算する代わりに、はるかに少ないリソースで高精度な近似値を返します。
BigQueryでは、HLLをベースとしたAPPROX_COUNT_DISTINCT関数でこの機能を利用できます。今回はお客様の用途にとって近似精度は十分であり、わずかな精度の犠牲を、速度とコストの大幅な改善が大きく上回るものでした。
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
まずは即効策:APPROX\_COUNT\_DISTINCTでHLLを導入
標準的なCOUNT(DISTINCT)クエリ
30日間を対象にした典型的なCOUNT(DISTINCT)クエリは、次のようになります。
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
このクエリは過去30日間のユニークユーザーを算出しますが、次回実行時に前回の結果を活用することができず、低速かつ高コストになりがちです。
APPROX_COUNT_DISTINCTを使った最適化版HLLクエリ
BigQueryのAPPROX_COUNT_DISTINCT関数経由でHLLを利用すれば、はるかに高速・低コストで結果が得られます。
SELECT
APPROX_COUNT_DISTINCT(user_id) AS approx_unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
とはいえ、APPROX_COUNT_DISTINCTを使ってもクエリのたびに30日分のデータをスキャンする点は変わりません。そこで真価を発揮するのがHLLスケッチです。日次サマリーをあらかじめ計算・保存しておけば、後から効率的に結合できます。
BigQuery HLLスケッチ:高度な日次集計の手法
HLLスケッチは、ハッシュを使って情報を要約するコンパクトなデータ構造です。すべてのユーザー訪問のリスト(数百万件にのぼることもあります)を保持する代わりに、数キロバイト程度の圧縮された表現であるスケッチを保存し、これを後から複数の期間にわたるユニーク数の推定に活用します。
このお客様のケースでは、日次のHLLスケッチを生成する仕組みを構築しました。
- 毎日、お客様のニーズに合わせて値ごとのユニークユーザーグループを要約したHLLスケッチを生成
- これらのスケッチを集約することで、過去30日間など任意の期間のユニークユーザー数を、ゼロから再計算せずに算出
この集約こそが最大のメリットです。HLLスケッチは二重カウントによる誤差を生じさせず、全データのスキャンも必要とせずに、期間をまたいで効率よく結合できます。これにより、お客様は30日間のユニークユーザー数を、わずかなリソースと時間で算出できるようになりました。
クエリ例:日次HLLスケッチの作成
BigQueryで日次HLLスケッチを格納する例は次のとおりです。
CREATE OR REPLACE TABLE project.dataset.daily_sketches AS
SELECT
event_date,
HLL_COUNT.INIT(user_id) AS hll_sketch
FROM
project.dataset.user_interactions
GROUP BY
event_date;
このクエリでは、user_interactionsテーブルのユニークユーザーを日ごとに要約した、日次HLLスケッチのテーブルを作成しています。
30日ウィンドウでのHLLスケッチの集約
SELECT
HLL_COUNT.MERGE(hll_sketch) AS approx_unique_users
FROM
project.dataset.daily_sketches
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
ここではHLL_COUNT.MERGEで日次のHLLスケッチを結合し、ゼロから再計算することなく30日間全体のユニークユーザー数を推定しています。
BigQuery HLLで得られた実際の成果
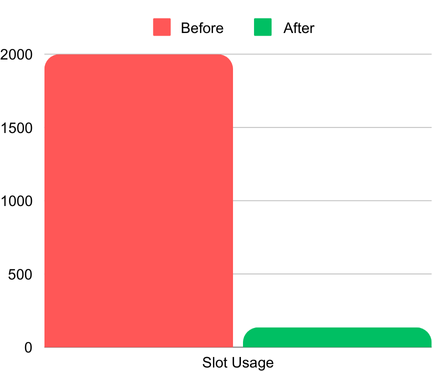
HLLスケッチ導入前後のスロット使用率(2Kスロットは最大割り当て値で、HLL導入前の実消費はそれを大きく上回っていました)
パフォーマンスの向上
HLLスケッチへの移行は、お客様に大きなメリットをもたらしました。
- クエリコストの削減:当初、クエリはオンデマンド料金モデルで割り当てられた2,000スロットをすべて消費していました。代替策は予約スロット(BigQuery Editions)の追加購入でしたが、それではコストが大幅に増えてしまいます。HLLスケッチを導入し集約テーブルを作成した結果、スロット消費はわずか135スロットに激減し、クエリ時間とコストの双方を劇的に削減できました。
- クエリの高速化:クエリ時間は数時間から数秒(7秒)へ短縮され、お客様はレポートをより早く生成し、リアルタイムの意思決定ニーズに応えられるようになりました。
- スケーラビリティ:データセットが拡大してもHLLベースの手法は全テーブルスキャンや再計算なしにスケールし続け、コストを低く抑えられました。
- 「十分な」精度:HLLが返すのはユニーク訪問者データの近似値ですが、設定可能な精度はお客様のレポーティング要件にとって十分以上であり、ビジネス成果に目立った影響はありませんでした。
コスト削減効果
結果は目覚ましいものでした。
- パフォーマンス(実行時間)が99%以上改善。
- スロット:クエリのスロット消費が2,000超から135へ削減。
- 時間:30日間のユニーク数算出にかかるクエリ時間が数時間から数秒に短縮。
- スキャンデータ量:1クエリあたり6.5TBから16.25GBに。
- コスト削減:各クエリで消費するスロット数とスキャンデータ量を削減でき、導入後はスロットの追加購入も不要に。
- データドリブンな意思決定の強化:重要なインサイトに素早くアクセスできるようになり、ユーザー行動への対応やマーケティング戦略の調整がはるかに効果的になりました。
BigQueryのCOUNT(DISTINCT)によるユニーク値カウントでパフォーマンスのボトルネックに直面している企業、とりわけ大規模データセットや長期間の集計を扱う場合、HLLスケッチはきわめて効率的な解決策となります。近似ユニークカウントに切り替え、日次スケッチを保存しておくことで、本事例のようにクエリコストを大幅に削減し、パフォーマンスを99%以上向上させることが可能です。
タイムリーかつコスト効率の高いユニークカウントレポーティングがビジネスに不可欠であれば、HLLの導入をぜひ検討し、ご自身のデータワークフローでも同様の改善を体感してみてください。
クラウドの利用状況、コスト、そして何より時間を最適化したいとお考えなら、お気軽にお問い合わせください。データの課題を成長機会へと変える方法を、一緒に探っていきましょう。