TL;DR: Ein Datenanbieter kämpfte mit massiven COUNT(DISTINCT)-Abfragen über 6,5 TB Daten und fand mit HyperLogLog (HLL) die passende Lösung. Gemeinsam haben wir Folgendes erreicht:
- Drastische Kostensenkung: BigQuery-Slot-Verbrauch von 2.000 On-Demand-Slots auf nur 135 Slots reduziert – der Kauf zusätzlicher reservierter Slots wurde überflüssig.
- Blitzschnelle Performance: Abfragezeiten von Stunden auf nur 7 Sekunden verkürzt.
- Effiziente Skalierung: Datenscans pro Abfrage von 6,5 TB auf 16,25 GB reduziert – bei gleichbleibender Genauigkeit.
- Nachhaltiges Wachstum: Der neue HLL-basierte Ansatz skaliert auch bei steigenden Datenvolumina effizient weiter.
Wer einzelne Kunden und ihr Verhalten versteht, hat im E-Commerce, Digital Marketing und bei Datendiensten klar die Nase vorn. Einer unserer Kunden – ein großer Datenanbieter – wertet einzigartige Nutzerinteraktionen über rollierende 30-Tage-Fenster aus, um damit Marketingkampagnen und Produktempfehlungen zu steuern.
Mit dem Wachstum auf Milliarden Datensätzen brauchten die COUNT(DISTINCT)-Abfragen jedoch Stunden, wurden exponentiell teurer – und schlugen gelegentlich komplett fehl.
Was als unkomplizierte Analyseaufgabe begann, entwickelte sich zu einer ernsthaften technischen Herausforderung, die die Entscheidungsfähigkeit des Unternehmens zu beeinträchtigen drohte.
In diesem Beitrag zeige ich:
- Warum die COUNT(DISTINCT)-Funktion bei großen Datenmengen rechenintensiv wird
- Welche Auswirkungen das auf Abfrageleistung und Kosten hat (unser Kunde scannte 6,5 TB Daten pro Abfrage!)
- Wie wir das Problem mit HyperLogLog (HLL) gelöst haben – Abfragezeiten von Stunden auf Sekunden, Ressourcenverbrauch um 93 % reduziert

Hyper City
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Das Problem mit COUNT(DISTINCT) bei großen Datenmengen
COUNT DISTINCT zählt zwar zuverlässig die Anzahl eindeutiger Werte in einer Spalte – sobald aber große Datenmengen ins Spiel kommen, treten Performance-Probleme auf, weil bei jedem Lauf das gesamte Dataset verarbeitet werden muss.
Ein einfaches Beispiel:
- Daten Tag 1
User A besucht
User B besucht
User C besucht
COUNT DISTINCT = 3 User
- Daten Tag 2
User B besucht
User C besucht
User D besucht
COUNT DISTINCT = 3 User
Würde man diese Tageswerte einfach addieren (3+3=6), um die Gesamtzahl der eindeutigen User über zwei Tage zu erhalten, wäre das Ergebnis falsch – User B und User C würden doppelt gezählt.
Während sich viele Aggregatfunktionen – etwa SUM – weiter aggregieren lassen, ist das bei COUNT DISTINCT nicht möglich. Um die Gesamtzahl der eindeutigen Werte korrekt zu ermitteln, müssten wir die Daten beider Tage zusammenführen und COUNT DISTINCT auf das gesamte kombinierte Set anwenden.
Case Study: Als 6,5-TB-COUNT(DISTINCT)-Abfragen nicht mehr tragbar waren
Unser Kunde hatte keine Wahl: Er musste täglich sämtliche Rohdaten über ein rollierendes 30-Tage-Fenster auswerten. Das bedeutete Abfragen über eine riesige Tabelle mit 18.570.335.647 Datensätzen (nach Partitionsfilterung) – also rund 6,5 TB Scan pro Lauf!
Das wurde zum operativen Engpass:
- Hoher Slot-Verbrauch: Die 2.000 Slots waren schnell ausgeschöpft – das Slot-Kontingent von BigQuery für On-Demand-Jobs wurde erreicht und der Job schlug fehl.
- Lange Ausführungszeiten: Wenn der Job nicht fehlschlug, lief er stundenlang. Die Daten standen den Entscheidern damit nicht rechtzeitig zur Verfügung.
- Teure Abfragen: COUNT(DISTINCT) jeden Tag neu zu berechnen und Milliarden Datensätze immer wieder zu scannen, hatte naturgemäß seinen Preis.
Schnell war klar: Mit dem COUNT DISTINCT-Ansatz konnte es so nicht weitergehen.
Wie BigQuery HLL eindeutige Zählungen approximiert
Hier kommt HyperLogLog (HLL) ins Spiel. HLL ist ein probabilistischer Algorithmus, mit dem sich die Anzahl eindeutiger Elemente in einem Dataset schätzen lässt. Statt die exakte Zahl jedes Mal neu zu berechnen, liefert HLL eine hochgenaue Näherung – mit deutlich weniger Ressourcenaufwand.
BigQuery stellt diese Funktionalität über die auf HLL basierende Funktion APPROX_COUNT_DISTINCT bereit. Die Näherung war für die Anforderungen des Kunden mehr als genau genug – die kleinen Einbußen bei der Präzision wurden durch die enormen Verbesserungen bei Geschwindigkeit und Kosten mehr als aufgewogen.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Quick Wins: HLL über APPROX\_COUNT\_DISTINCT umsetzen
Standard-COUNT(DISTINCT)-Abfrage
So sieht eine typische COUNT(DISTINCT)-Abfrage über 30 Tage aus:
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Diese Abfrage ermittelt die eindeutigen User der letzten 30 Tage – beim nächsten Lauf lassen sich die Ergebnisse des vorherigen Laufs aber nicht wiederverwenden, was langsam und teuer ist.
Optimierte HLL-basierte Abfrage mit APPROX_COUNT_DISTINCT
Mit HLL über die Funktion APPROX_COUNT_DISTINCT in BigQuery erhalten wir Ergebnisse deutlich schneller und günstiger:
SELECT
APPROX_COUNT_DISTINCT(user_id) AS approx_unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Auch mit APPROX_COUNT_DISTINCT scannen wir bei jeder Abfrage aber weiterhin 30 Tage Daten. Genau hier kommen HLL-Sketches ins Spiel – sie ermöglichen es, tägliche Zusammenfassungen vorzuberechnen und zu speichern, die sich später effizient kombinieren lassen.
BigQuery HLL Sketches: Tagesaggregation auf höherem Niveau
HLL-Sketches sind kompakte Datenstrukturen, die Informationen per Hashing zusammenfassen. Statt jeden einzelnen Nutzerbesuch zu speichern (das können Millionen von Datensätzen sein), legen Sie eine wenige Kilobyte große, komprimierte Repräsentation ab – den Sketch –, mit dem sich später eindeutige Zählungen über mehrere Zeiträume schätzen lassen.
Im Fall unseres Kunden haben wir tägliche HLL-Sketches aufgesetzt:
- Das System erzeugte täglich einen HLL-Sketch, der die eindeutigen Nutzergruppen nach den für den Kunden relevanten Werten zusammenfasste.
- Diese Sketches wurden anschließend aggregiert, um eindeutige User über beliebige Zeiträume – etwa die letzten 30 Tage – zu berechnen, ohne alles neu durchzurechnen.
Genau diese Aggregation ist der entscheidende Vorteil: HLL-Sketches lassen sich über Zeiträume hinweg effizient kombinieren – ohne Doppelzählungen und ohne dass ein vollständiger Datenscan nötig wäre. So konnte unser Kunde eindeutige Nutzerzahlen über 30 Tage abfragen und brauchte dafür nur einen Bruchteil der Ressourcen und Zeit.
Beispielabfrage: Tägliche HLL-Sketches erstellen
So lassen sich tägliche HLL-Sketches in BigQuery speichern:
CREATE OR REPLACE TABLE project.dataset.daily_sketches AS
SELECT
event_date,
HLL_COUNT.INIT(user_id) AS hll_sketch
FROM
project.dataset.user_interactions
GROUP BY
event_date;
Mit dieser Abfrage erstellen wir eine tägliche Tabelle aus HLL-Sketches – einen pro Tag –, die die eindeutigen User der Tabelle user_interactions zusammenfassen.
HLL-Sketches über 30-Tage-Fenster aggregieren
SELECT
HLL_COUNT.MERGE(hll_sketch) AS approx_unique_users
FROM
project.dataset.daily_sketches
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Mit HLL_COUNT.MERGE kombinieren wir hier die täglichen HLL-Sketches und schätzen so die Anzahl eindeutiger User über den gesamten 30-Tage-Zeitraum – ohne alles von Grund auf neu zu berechnen.
BigQuery HLL: Die Ergebnisse aus der Praxis
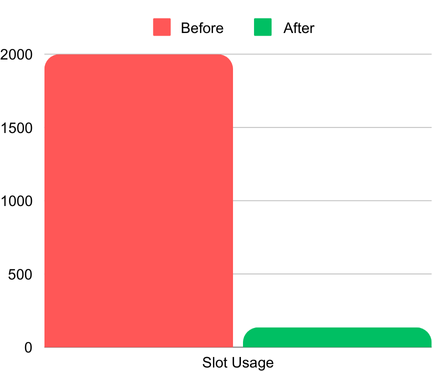
Slot-Auslastung vor und nach dem Einsatz von HLL-Sketches. (Die 2.000 Slots stehen für die maximale Zuteilung; der tatsächliche Verbrauch vor HLL lag deutlich höher)
Performance-Verbesserungen
Der Wechsel zu HLL-Sketches brachte unserem Kunden entscheidende Vorteile:
- Geringere Abfragekosten: Anfangs verbrauchte die Abfrage sämtliche der 2.000 zugewiesenen Slots im On-Demand-Preismodell. Die Alternative wäre der Kauf zusätzlicher reservierter Slots gewesen (BigQuery Editions) – mit deutlich höheren Kosten. Nach der Einführung von HLL-Sketches und einer Aggregationstabelle sank der Slot-Verbrauch auf nur 135 Slots, was Abfragezeit und Kosten drastisch reduzierte.
- Schnellere Abfragen: Die Laufzeiten sanken von Stunden auf Sekunden (7 Sekunden) – Reports waren schneller fertig, und Echtzeit-Entscheidungen wurden möglich.
- Skalierbarkeit: Mit wachsendem Dataset skaliert der HLL-basierte Ansatz weiter, ohne Full-Table-Scans oder Neuberechnungen – die Kosten bleiben niedrig.
- "Genau genug": HLL liefert zwar eine Näherung der eindeutigen Besucherzahlen, aber die konfigurierbare Genauigkeit war für die Reporting-Anforderungen des Kunden mehr als ausreichend – ohne erkennbare Auswirkungen auf die Geschäftsergebnisse.
Kostenreduktion
Die Ergebnisse können sich sehen lassen:
- Performance (Laufzeit) um über 99 % verbessert.
- Slots: Slot-Verbrauch von über 2.000 auf nur 135 reduziert.
- Zeit: Abfragezeiten für eindeutige Zählungen über 30 Tage von mehreren Stunden auf wenige Sekunden gesenkt.
- Gescannte Daten: von 6,5 TB pro Abfrage auf 16,25 GB.
- Kosteneinsparungen: Der Kunde konnte sowohl den Slot-Verbrauch als auch die gescannte Datenmenge pro Abfrage senken – nach der Umsetzung war kein Slot-Kauf mehr nötig.
- Bessere datengetriebene Entscheidungen: Mit schnellerem Zugriff auf zentrale Insights konnte der Kunde auf das Nutzerverhalten reagieren und seine Marketingstrategie deutlich effektiver anpassen.
Für Unternehmen, die in BigQuery mit Performance-Engpässen bei COUNT(DISTINCT)-Abfragen kämpfen – besonders bei großen Datasets und langen Zeiträumen – sind HLL-Sketches eine hocheffiziente Lösung. Wer auf approximierte Distinct Counts umsteigt und tägliche Sketches speichert, senkt die Abfragekosten deutlich und steigert die Performance um über 99 % – wie das reale Beispiel zeigt.
Wenn Ihr Unternehmen auf zeitnahes und kostengünstiges Distinct-Count-Reporting angewiesen ist, lohnt sich ein Blick auf HLL – mit dem Potenzial für vergleichbare Verbesserungen in Ihren Daten-Workflows.
Sie möchten Ihre Cloud-Nutzung, Kosten und – noch wichtiger – Ihre Zeit optimieren? Sprechen Sie mit uns – gemeinsam loten wir aus, wie wir Ihre Datenherausforderungen in Wachstumschancen verwandeln.