In sintesi: un data provider alle prese con query COUNT(DISTINCT) enormi su 6,5 TB di dati ha trovato la soluzione nell'adozione di HyperLogLog (HLL). Lavorando insieme abbiamo ottenuto:
- Costi drasticamente ridotti: consumo di slot BigQuery passato da 2.000 slot on-demand a soli 135, eliminando la necessità di acquistare ulteriori reserved slot
- Prestazioni fulminee: tempi di esecuzione delle query crollati da diverse ore a soli 7 secondi
- Scalabilità efficiente: dati scansionati ridotti da 6,5 TB a 16,25 GB per query, senza compromettere l'accuratezza
- Crescita sostenibile: il nuovo approccio basato su HLL continua a scalare in modo efficiente man mano che i volumi di dati aumentano
Capire il comportamento dei singoli utenti è fondamentale per il successo delle aziende attive nell'e-commerce, nel digital marketing e nei servizi dati. Uno dei nostri clienti, un grande data provider con cui ho lavorato, monitora le interazioni utente uniche su finestre di 30 giorni per alimentare le campagne di marketing e i sistemi di raccomandazione prodotto.
Tuttavia, con la crescita dei dati fino a miliardi di record, le query COUNT(DISTINCT) usate per analizzare il comportamento dei singoli utenti hanno iniziato a richiedere ore, diventando esponenzialmente più costose — e talvolta fallendo del tutto.
Quella che era nata come una semplice attività di analisi si è trasformata in una sfida tecnica di rilievo, mettendo a rischio la capacità decisionale dell'azienda.
In questo articolo analizzerò:
- Perché la funzione COUNT(DISTINCT) diventa onerosa dal punto di vista computazionale su larga scala
- Quale impatto ha su prestazioni e costi delle query (il nostro cliente scansionava 6,5 TB di dati per ogni query!)
- Come abbiamo risolto il problema con HyperLogLog (HLL), riducendo i tempi di query da ore a secondi e tagliando del 93% l'uso delle risorse

Hyper City
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Il problema di COUNT(DISTINCT) su larga scala
COUNT DISTINCT serve a contare i valori univoci all'interno di una colonna specifica, ma quando entra in gioco la mole dei dati emergono problemi di prestazioni, perché la query deve elaborare l'intero dataset a ogni esecuzione.
Vediamo un esempio semplice:
- Dati Giorno 1
Utente A ha visitato
Utente B ha visitato
Utente C ha visitato
COUNT DISTINCT = 3 utenti
- Dati Giorno 2
Utente B ha visitato
Utente C ha visitato
Utente D ha visitato
COUNT DISTINCT = 3 utenti
Sommando questi conteggi giornalieri (3+3=6) per ottenere il totale degli utenti unici sui due giorni, otterremmo un risultato errato perché Utente B e Utente C verrebbero contati due volte.
Mentre molte funzioni di aggregazione — come SUM — possono essere ulteriormente aggregate, COUNT DISTINCT no. Per determinare correttamente il numero totale di valori distinti occorre unire i dati di entrambi i giorni e poi applicare la funzione COUNT DISTINCT all'intero set risultante.
Case study: quando le query COUNT(DISTINCT) da 6,5 TB diventano insostenibili
Nel caso del nostro cliente non c'era alternativa: ogni giorno bisognava analizzare tutti i dati grezzi su una finestra mobile di 30 giorni. Questo significava interrogare una tabella enorme con 18.570.335.647 record (dopo il filtro per partizione) — circa 6,5 TB scansionati a ogni esecuzione!
Il risultato era un collo di bottiglia per le operazioni del cliente:
- Consumo elevato di slot: i 2.000 slot venivano esauriti rapidamente, raggiungendo la quota slot di BigQuery per i job on-demand e provocando il fallimento del job.
- Tempi di esecuzione lunghi: quando il job non falliva, impiegava ore per essere completato. I dati non erano quindi disponibili in tempo utile per chi doveva prendere decisioni.
- Query costose: ricalcolare COUNT(DISTINCT) ogni giorno e scansionare ripetutamente miliardi di record aveva inevitabilmente un prezzo elevato.
Era quindi evidente che proseguire con l'approccio COUNT DISTINCT non era sostenibile.
Come BigQuery HLL approssima i conteggi univoci
È qui che entra in gioco HyperLogLog (HLL). HLL è un algoritmo probabilistico che permette di stimare il numero di elementi distinti in un dataset. Invece di ricalcolare il numero esatto di elementi distinti, HLL fornisce un'approssimazione molto accurata utilizzando una frazione delle risorse.
BigQuery offre questa funzionalità tramite la funzione APPROX_COUNT_DISTINCT, basata su HLL. L'approssimazione si è rivelata abbastanza accurata per le esigenze del cliente e il piccolo compromesso sulla precisione è stato ampiamente ripagato dai grandi miglioramenti in termini di velocità e costi.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Risultati immediati: implementare HLL con APPROX\_COUNT\_DISTINCT
Query COUNT(DISTINCT) standard
Vediamo come potrebbe presentarsi una tipica query COUNT(DISTINCT) su 30 giorni:
SELECT
COUNT(DISTINCT user_id) AS unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Questa query calcola gli utenti distinti negli ultimi 30 giorni, ma all'esecuzione successiva non riutilizza i risultati delle esecuzioni precedenti, risultando lenta e costosa.
Query ottimizzata con HLL tramite APPROX_COUNT_DISTINCT
Usando HLL tramite la funzione APPROX_COUNT_DISTINCT in BigQuery, otteniamo risultati molto più rapidi ed economici:
SELECT
APPROX_COUNT_DISTINCT(user_id) AS approx_unique_users
FROM
project.dataset.user_interactions
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Tuttavia, anche con APPROX_COUNT_DISTINCT continuiamo a scansionare 30 giorni di dati a ogni query. È qui che entrano in scena gli sketch HLL: ci permettono di pre-calcolare e memorizzare riepiloghi giornalieri da combinare poi in modo efficiente.
BigQuery HLL Sketches: un metodo avanzato di aggregazione giornaliera
Gli sketch HLL sono strutture dati compatte che usano l'hashing per riassumere le informazioni. Invece di conservare l'elenco di ogni singola visita utente (che può comportare milioni di record), si memorizza una rappresentazione compressa di pochi kilobyte — lo sketch — utilizzabile in seguito per stimare i conteggi distinti su più periodi temporali.
Nel caso del nostro cliente, lo abbiamo aiutato a creare sketch HLL giornalieri:
- Ogni giorno il sistema generava uno sketch HLL che riassumeva i gruppi di utenti unici in base ai valori richiesti dal cliente.
- Questi sketch venivano poi aggregati per calcolare gli utenti distinti su qualsiasi intervallo temporale, ad esempio gli ultimi 30 giorni, senza dover ricalcolare tutto da zero.
Questa aggregazione è il vantaggio decisivo: gli sketch HLL si possono combinare in modo efficiente tra periodi diversi senza introdurre errori da doppio conteggio né richiedere una scansione completa dei dati. Ha permesso al nostro cliente di interrogare i conteggi degli utenti unici su 30 giorni utilizzando una frazione delle risorse e dei tempi.
Esempio di query: creare sketch HLL giornalieri
Ecco come si possono memorizzare gli sketch HLL giornalieri in BigQuery:
CREATE OR REPLACE TABLE project.dataset.daily_sketches AS
SELECT
event_date,
HLL_COUNT.INIT(user_id) AS hll_sketch
FROM
project.dataset.user_interactions
GROUP BY
event_date;
In questa query creiamo una tabella giornaliera di sketch HLL, uno per ciascun giorno, che riassume gli utenti distinti nella tabella user_interactions.
Aggregare gli sketch HLL su finestre di 30 giorni
SELECT
HLL_COUNT.MERGE(hll_sketch) AS approx_unique_users
FROM
project.dataset.daily_sketches
WHERE
event_date BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) AND CURRENT_DATE();
Qui usiamo HLL_COUNT.MERGE per combinare gli sketch HLL giornalieri, stimando il conteggio degli utenti distinti sull'intero periodo di 30 giorni senza ricalcolare da zero.
Risultati concreti con BigQuery HLL
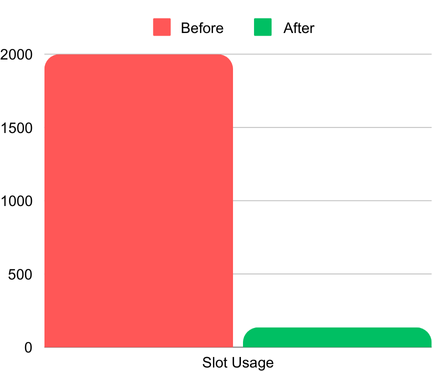
L'utilizzo degli slot prima e dopo l'adozione degli sketch HLL. ( 2K slot rappresentano l'allocazione massima; il consumo effettivo prima di HLL era molto più alto)
Miglioramenti nelle prestazioni
Il passaggio agli sketch HLL ha portato un vantaggio enorme per il nostro cliente:
- Costi delle query ridotti: inizialmente la query consumava tutti i 2.000 slot allocati nel modello di pricing on-demand. L'unica alternativa per il cliente era acquistare ulteriori reserved slot ( BigQuery Editions), con un aumento significativo dei costi. Tuttavia, dopo aver implementato gli sketch HLL e creato una tabella aggregata, il consumo di slot è sceso a soli 135, riducendo drasticamente sia i tempi di esecuzione sia i costi.
- Query più veloci: i tempi di query sono passati da ore a secondi (7 secondi), permettendo al cliente di generare report più rapidamente e di rispondere a esigenze decisionali in tempo reale.
- Scalabilità: con la crescita del dataset, l'approccio basato su HLL ha continuato a scalare senza richiedere scansioni complete della tabella o ricalcoli, mantenendo i costi contenuti.
- Sufficientemente accurato: sebbene HLL fornisca un'approssimazione dei dati sui visitatori unici, il cliente ha riscontrato che l'accuratezza configurabile era più che adeguata per le proprie esigenze di reporting, senza alcun impatto percepibile sui risultati di business.
Riduzione dei costi
I risultati sono stati notevoli:
- Le prestazioni (tempi di esecuzione) sono migliorate di oltre il 99%.
- Slot: il consumo di slot per query è sceso da oltre 2.000 a soli 135.
- Tempo: i tempi di query per i conteggi distinti su 30 giorni sono passati da diverse ore a pochi secondi.
- Dati scansionati: da 6,5 TB per query a 16,25 GB.
- Risparmio sui costi: il cliente ha ridotto sia il numero di slot consumati sia i dati scansionati per ogni query e, dopo l'implementazione, non è più stato necessario acquistare slot.
- Decisioni data-driven più efficaci: con un accesso più rapido agli insight chiave, il cliente ha potuto reagire al comportamento degli utenti e affinare le proprie strategie di marketing in modo molto più tempestivo.
Per le aziende che si scontrano con colli di bottiglia di prestazioni nel conteggio dei valori univoci tramite query COUNT(DISTINCT) in BigQuery — soprattutto su dataset di grandi dimensioni e su finestre temporali estese — gli sketch HLL rappresentano una soluzione estremamente efficiente. Passando ai conteggi distinti approssimati e memorizzando sketch giornalieri è possibile ridurre in modo significativo i costi delle query e migliorare le prestazioni di oltre il 99%, come dimostra questo caso reale.
Se la sua attività dipende da un reporting tempestivo ed economico dei conteggi distinti, valuti l'adozione di HLL: potrà ottenere miglioramenti analoghi nei suoi flussi dati.
Se vuole ottimizzare l'utilizzo del cloud, i costi e — soprattutto — il tempo, ci contatti: insieme possiamo trasformare le sue sfide sui dati in opportunità di crescita.