Con il rilevamento delle anomalie a livello di SKU e gli alert mirati, può diffondere una cultura di spesa cloud responsabile e ridurre i tempi medi di risoluzione dei picchi di costo.

Nel tentativo di tenere sotto controllo la spesa cloud, molte aziende stanno coinvolgendo i team di engineering e di prodotto per renderli più responsabili della loro quota di costi cloud — e i motivi sono evidenti.
Quando engineer e product owner conoscono il costo del proprio lavoro, è più probabile che ne tengano conto già in fase di sviluppo delle funzionalità e nel monitoraggio post-lancio, con un impatto diretto e positivo sui conti.
E se il reporting in tempo reale resta una tattica di prim'ordine per chi vuole sensibilizzare gli stakeholder, da solo non basta a far reagire i team in fretta a comportamenti anomali o picchi di costo. Servono anche alert in tempo reale.
Fino a oggi, però, i sistemi di anomaly detection out-of-the-box offrivano in genere una visione sull'utilizzo cloud dell'intera organizzazione, con alert a livello di servizio. Un approccio così generico, però:
- La obbliga a individuare manualmente la SKU (o le SKU) e le risorse all'origine dell'anomalia di costo per un servizio
- Notifica ai team anomalie di costo che non riguardano direttamente le loro attività.
Per questo siamo entusiasti di annunciare gli alert specifici per SKU per DoiT Anomaly Detection, insieme alla possibilità di iscriversi agli alert relativi alle parti di infrastruttura di cui ciascuno è responsabile.
Vediamo i vantaggi di entrambi e come configurare alert di anomalia personalizzati in Cloud Intelligence™.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Ognuno è responsabile dei propri costi cloud
Un principio cardine del FinOps è: "Ognuno è responsabile dei propri costi."
Per costruire una cultura di ottimizzazione dei costi, il primo passo è far arrivare dati precisi e personalizzati alle persone giuste.
Come per i report e i dashboard, alert di anomalia precisi e personalizzati innescano conversazioni interne che portano a una migliore comprensione dei costi e delle decisioni infrastrutturali che li determinano, oltre che a una vera responsabilizzazione.
"Perché i nostri costi sono saliti? Era previsto? Cosa possiamo fare meglio la prossima volta?"
Come funziona il rilevamento delle anomalie a livello di SKU
Mentre molte aziende stanno ancora cercando di automatizzare gli alert sulle anomalie, DoiT Anomaly Detection è già pronta all'uso: monitora i picchi di costo in modo autonomo e La avvisa quando viene rilevata una spesa anomala, così può intervenire rapidamente e limitarne l'impatto in fattura. In questo modo, i Suoi engineer non devono sviluppare e mantenere uno strumento interno dedicato.
In passato, lo strumento osservava il modo in cui la Sua organizzazione consumava le risorse cloud, definendo un "comportamento normale" per ciascun servizio in ogni progetto/account.
Ma ogni minuto in cui un picco di costo non viene rilevato e risolto è come lasciare il rubinetto aperto sul Suo conto in banca. Più passa inosservato, maggiore sarà l'impatto economico e più pesanti le conseguenze. E più tempo si dedica a individuare manualmente l'origine del picco, più cresce l'impatto finanziario.
Con l'ultimo aggiornamento, DoiT Anomaly Detection analizza ora le anomalie SKU per SKU. Quando viene rilevato un comportamento anomalo, riceverà un'email (e un messaggio Slack, se l'ha configurato) che evidenzia la SKU coinvolta.
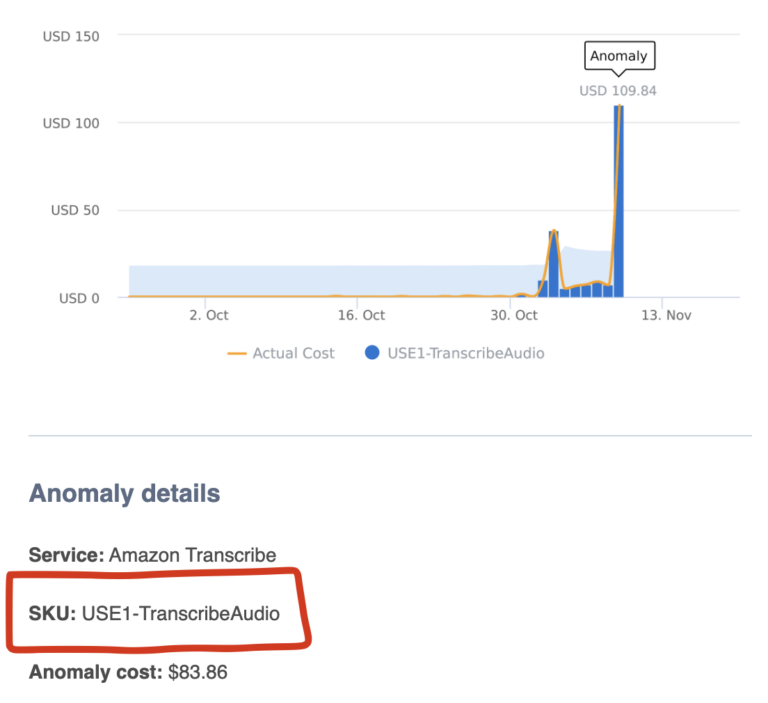
Alert di anomalia inviato via email
Se vuole approfondire in Cloud Intelligence™, potrà vedere anche le risorse che contribuiscono al picco di costo. Questo aiuta gli utenti a individuare con precisione la causa al massimo livello di dettaglio e riduce il tempo medio di risoluzione.
Nell'esempio qui sotto, in Cloud Intelligence™ vediamo che è stata rilevata un'anomalia su S3, e in particolare sulla SKU "DataTransfer-Out-Bytes". In basso si nota che a contribuire sono soprattutto tre bucket S3, con "bucket-1" come principale responsabile.
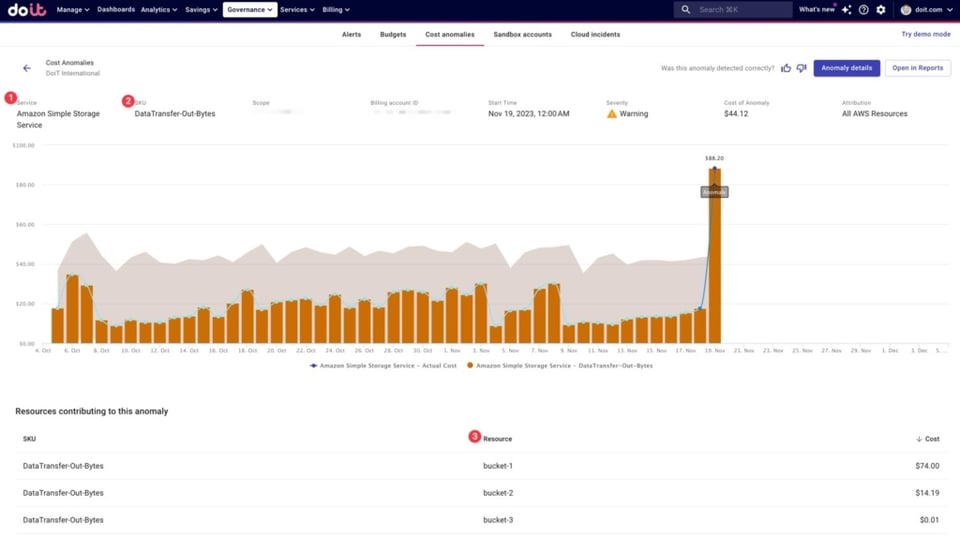
Esempio di picco di costo rilevato per una SKU in AWS S3
Riceve inoltre una spiegazione dell'anomalia e della SKU — che a volte non hanno nomi proprio intuitivi (es. "EUN1-LCUUsage") — accompagnata da suggerimenti di ottimizzazione pertinenti.
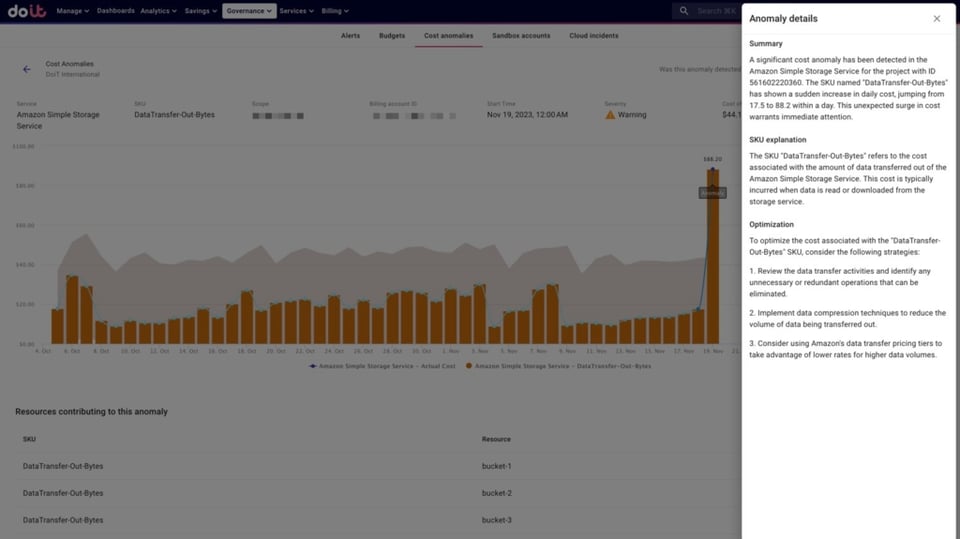
Spiegazione dettagliata di un'anomalia rilevata sui costi di Data Transfer di S3, con relativi consigli di ottimizzazione
Perché conviene personalizzare gli alert sulle anomalie in base alle parti di infrastruttura cloud di cui si è responsabili
Gli alert mirati sulle anomalie portano il rilevamento a livello di SKU un passo oltre, consentendo ai Suoi team di calibrare gli alert ricevuti e concentrarsi solo sui costi cloud di cui rispondono in prima persona.
A volte serve capire la varianza all'interno di un singolo contesto. La stagionalità del business, ad esempio, può mascherare i picchi di costo nei progetti R&S.
Ecco perché è così importante:
- Pertinenza e focus: calibrando gli alert sulle anomalie per i singoli team, garantisce che gli stakeholder ricevano notifiche solo sulle anomalie che impattano direttamente le loro attività. Si riduce così l'alert fatigue e i team possono concentrarsi sulle azioni che dipendono da loro.
- Risposta più rapida: quando i Suoi team ricevono alert relativi ai propri costi cloud, possono indagare subito sull'origine del problema e affrontare eventuali irregolarità. Questo approccio mirato accorcia i tempi di risposta agli incidenti, riducendo l'impatto che un picco di costo può avere sulla fattura mensile.
- Ottimizzazione precisa: l'anomaly detection mette a fuoco le aree in cui serve ottimizzare i costi. Quando i team vengono avvisati di picchi nel proprio dominio, sono più motivati a ottimizzare l'uso delle risorse e ad applicare le best practice, con risparmi complessivi e una gestione finanziaria più sana.
- Cultura della responsabilità: con il rilevamento mirato delle anomalie si rafforza il senso di ownership. I team diventano direttamente responsabili della propria spesa cloud, alimentando una cultura di consapevolezza e prudenza finanziaria.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Configurare alert di anomalia personalizzati con DoiT
Per prima cosa deve definire i costi di cui ciascun team o persona è responsabile. In Cloud Intelligence™ può farlo tramite le Attributions.
Cosa sono le Attributions?
Una "Attribution" è un raggruppamento logico di risorse cloud che definisce una categoria di costo specifica per la Sua azienda.
Le Attributions L'aiutano a mappare la spesa cloud su team, applicazioni, ambienti — qualsiasi categoria o raggruppamento rilevante per il Suo business.
Ipotizziamo, ad esempio, che la Sua azienda abbia tre prodotti diversi di cui vuole monitorare i costi. Le risorse di ciascun prodotto sono distribuite su più account AWS.
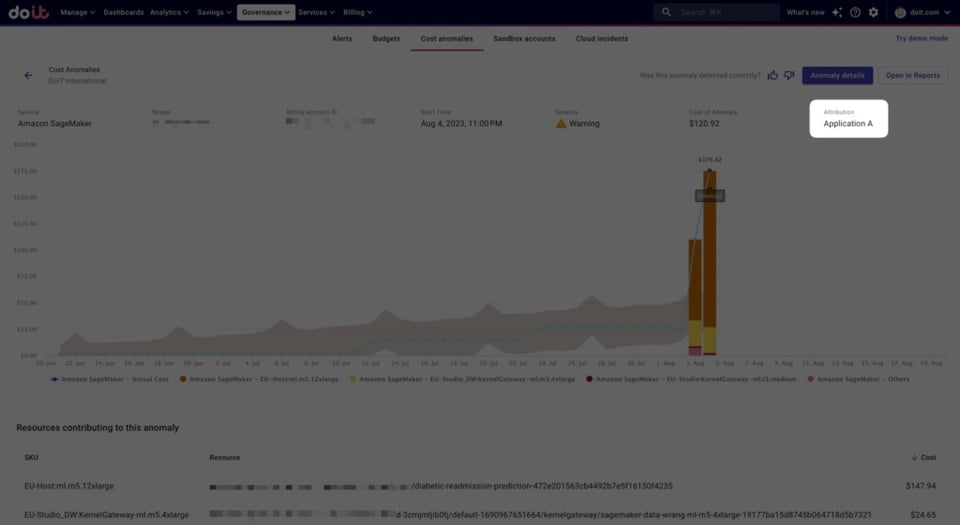
Con le Attributions possiamo raggruppare più account AWS e dare a quel gruppo il nome dell'applicazione. Qui sotto vede un esempio di "Application A" definita in questo modo.
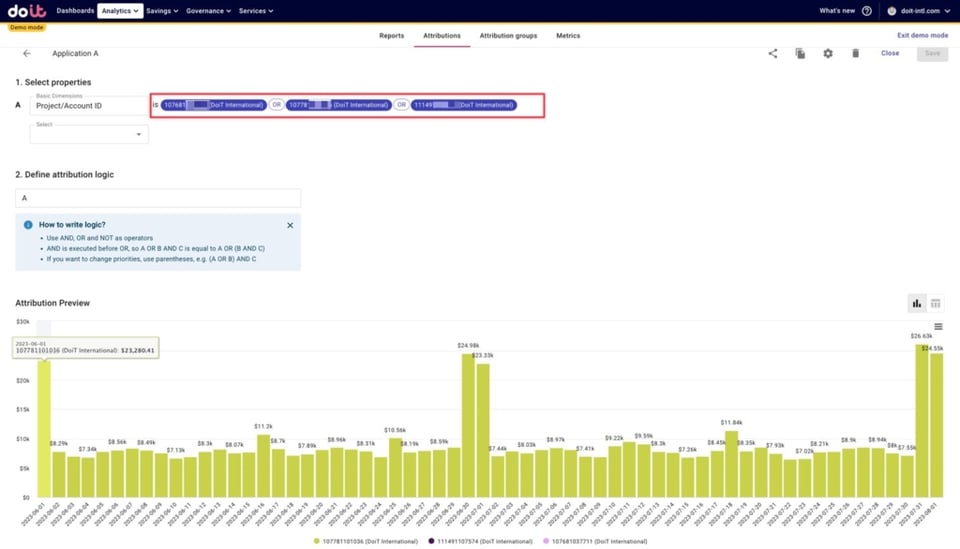
Esempio di Attribution per un'applicazione ipotetica
Ora supponiamo che voglia che gli engineer e i product manager che lavorano su Application A vengano avvisati solo quando viene rilevata un'anomalia relativa a questa applicazione.
Una volta creata l'Attribution, basta attivare l'Anomaly Detection per quella Attribution.
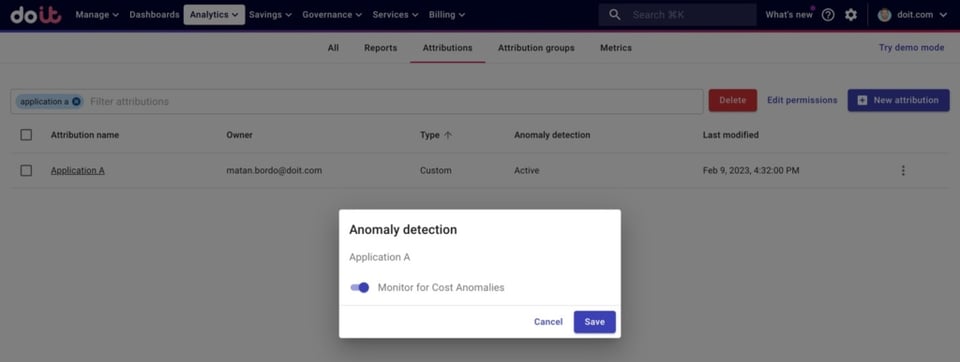
Attivazione dell'Anomaly Detection per un'Attribution
Poi può accedere alle impostazioni di notifica delle persone responsabili di Application A e iscriverle agli alert relativi a quell'Attribution (oppure possono farlo loro stesse).
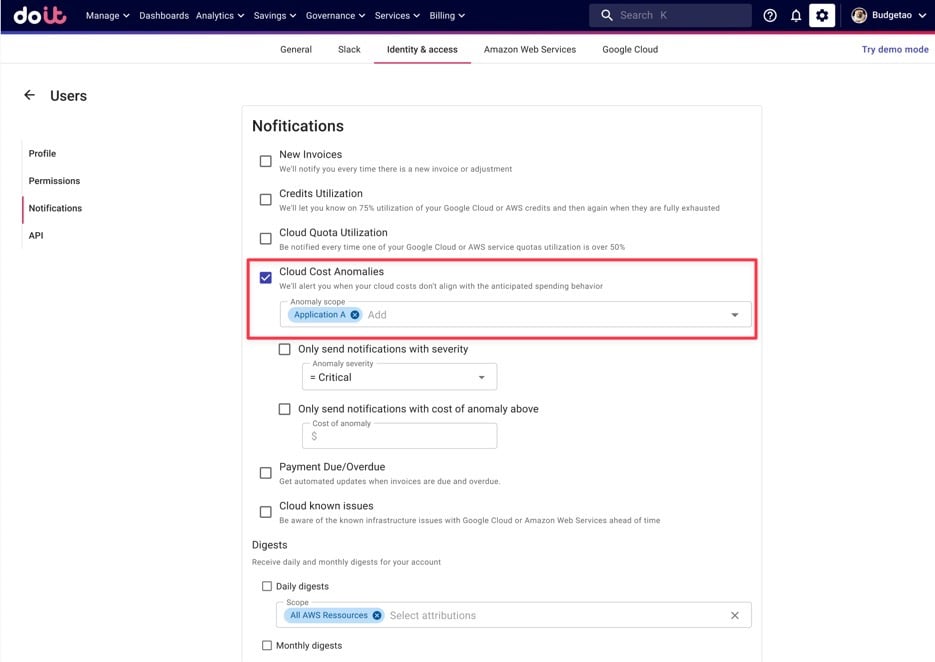
Iscrizione agli alert di anomalia per una specifica Attribution
Possono anche inoltrare gli alert a un canale Slack di team, se lo hanno.
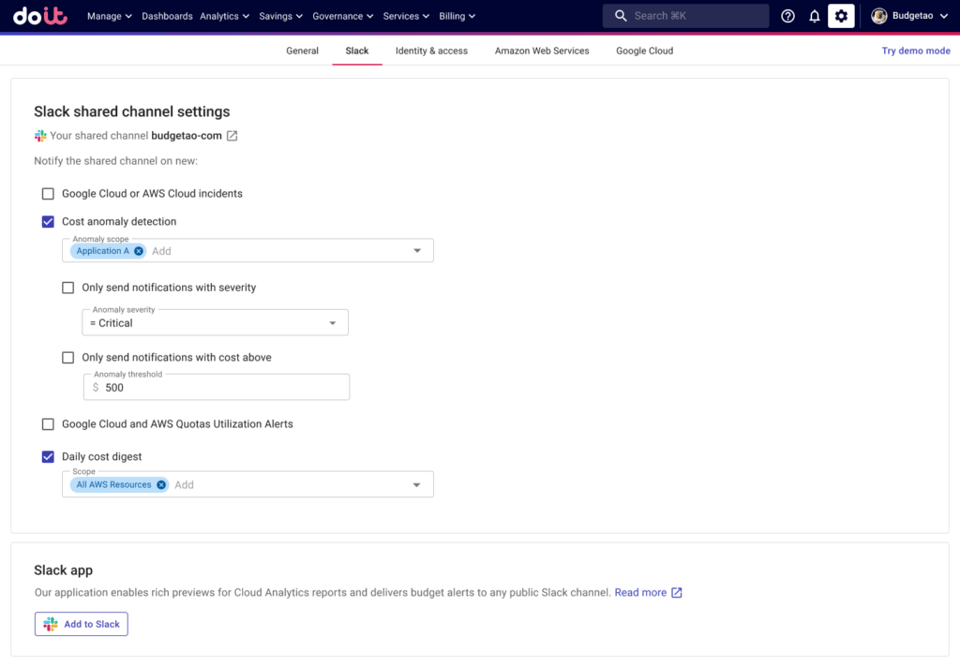 Inoltrare gli alert di anomalia di un'Attribution a un canale Slack condiviso
Inoltrare gli alert di anomalia di un'Attribution a un canale Slack condiviso
Quando un alert di anomalia arriva su Slack, è possibile valutarlo per affinare il nostro algoritmo, oppure approfondire l'analisi in Cloud Intelligence™.
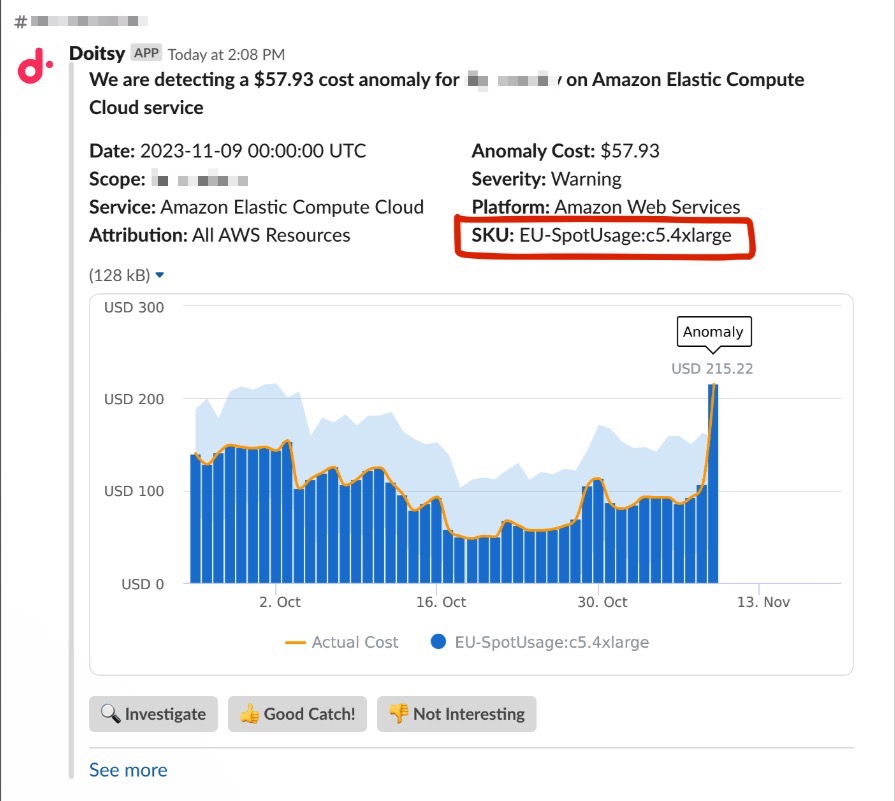
Alert di anomalia inviato a un canale Slack condiviso
Quando viene rilevata un'anomalia per un'Attribution, il nome dell'Attribution compare nella pagina dell'anomalia.
Quando si parla di gestione dei costi cloud, alert in tempo reale precisi e personalizzati sono determinanti per responsabilizzare il team sui costi.
Gli alert a livello di SKU di DoiT Anomaly Detection rappresentano un passo avanti decisivo per ridurre concretamente il tempo medio di risoluzione dei picchi di costo.
Uniti ad alert sulle anomalie più precisi e mirati, aiutano la Sua azienda a costruire una cultura di spesa cloud responsabile, mettendo i team nelle condizioni di prendere decisioni informate in autonomia, reagire rapidamente a qualsiasi irregolarità e contribuire in modo proattivo al successo delle Sue iniziative cloud.
Man mano che la Sua azienda adotterà le pratiche FinOps, queste funzionalità diventeranno strumenti preziosi per migliorare la visibilità sui costi, ottimizzare l'allocazione delle risorse e raggiungere l'eccellenza finanziaria nel cloud.
Se è già cliente DoiT, può iniziare a iscrivere se stesso e gli stakeholder agli alert sulle anomalie specifici per le parti di infrastruttura di cui sono responsabili in Cloud Intelligence™. Non è ancora cliente DoiT ma vuole sfruttare questa funzionalità insieme al più ampio portfolio di prodotti DoiT? Ci contatti qui.