Com detecção de anomalias por SKU e alertas direcionados, você cria uma cultura de gastos responsáveis na nuvem e ainda reduz o tempo médio para resolver picos de custo.

Conforme as empresas tentam controlar os gastos com nuvem, muitas estão puxando os times de engenharia e produto para que assumam mais responsabilidade pela fatia de custos de nuvem que consomem — e tem motivo de sobra para isso.
Quando engenheiros e product owners enxergam o custo do que produzem, fica muito mais natural levar esse fator em conta na hora de desenvolver funcionalidades e acompanhar o pós-lançamento — o que se traduz em impacto direto e positivo no resultado.
E, embora os relatórios em tempo real sigam como uma tática de destaque entre quem quer engajar os stakeholders, eles não necessariamente ajudam os times a reagir rápido a comportamentos anômalos ou picos de custo. Você também precisa de alertas em tempo real.
Mas, até agora, os sistemas prontos de detecção de anomalias costumavam dar visibilidade sobre o uso de nuvem da organização inteira, com alertas em nível de serviço. O problema dessa abordagem genérica é que ela:
- Obriga você a garimpar manualmente o(s) SKU(s) e recurso(s) por trás da anomalia de custo de um serviço
- Dispara para os times alertas de anomalias de custo que não dizem respeito direto à operação deles.
Por isso estamos animados em anunciar os alertas específicos por SKU para o DoiT Anomaly Detection, junto com a possibilidade de assinar alertas voltados para as partes da infraestrutura sob sua responsabilidade.
Vamos ver os benefícios de cada novidade e como configurar alertas de anomalias personalizados no Cloud Intelligence™.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Cada um é dono dos próprios custos de nuvem
Um princípio central do FinOps é: "cada um é dono dos próprios custos".
Um pré-requisito para construir uma cultura de otimização de custos é levar dados precisos e personalizados às pessoas certas.
Assim como os relatórios e os dashboards, alertas de anomalias precisos e personalizados puxam conversas internas que, no fim das contas, geram mais clareza e responsabilização sobre os custos e as decisões de infraestrutura por trás deles.
"Por que nossos custos dispararam? Isso era esperado? O que dá pra fazer melhor da próxima vez?"
Como funciona a detecção de anomalias por SKU
Como muitas empresas ainda querem automatizar os alertas de anomalias, o DoiT Anomaly Detection já vem pronto para uso, monitorando picos de custo de forma autônoma e avisando você sempre que detecta gastos fora do padrão — para que você aja rápido e minimize o impacto na fatura. Assim, seus engenheiros não precisam construir nem manter uma ferramenta interna só para isso.
Antes, ele observava como sua organização consumia recursos de nuvem e definia o "comportamento normal" para cada serviço em cada projeto/conta.
Mas cada minuto em que um pico de custo passa sem ser detectado e resolvido é como deixar a torneira aberta na sua conta bancária. Quanto mais tempo isso passa despercebido, maior o impacto financeiro e as consequências em potencial. E quanto mais trabalho manual você tem para descobrir a origem do pico, maior o estrago no bolso.
Com a atualização mais recente, o DoiT Anomaly Detection passa a analisar anormalidades em cada SKU. Quando um comportamento fora do padrão é detectado, você recebe um e-mail (e uma mensagem no Slack, se tiver configurado) destacando o SKU em questão.
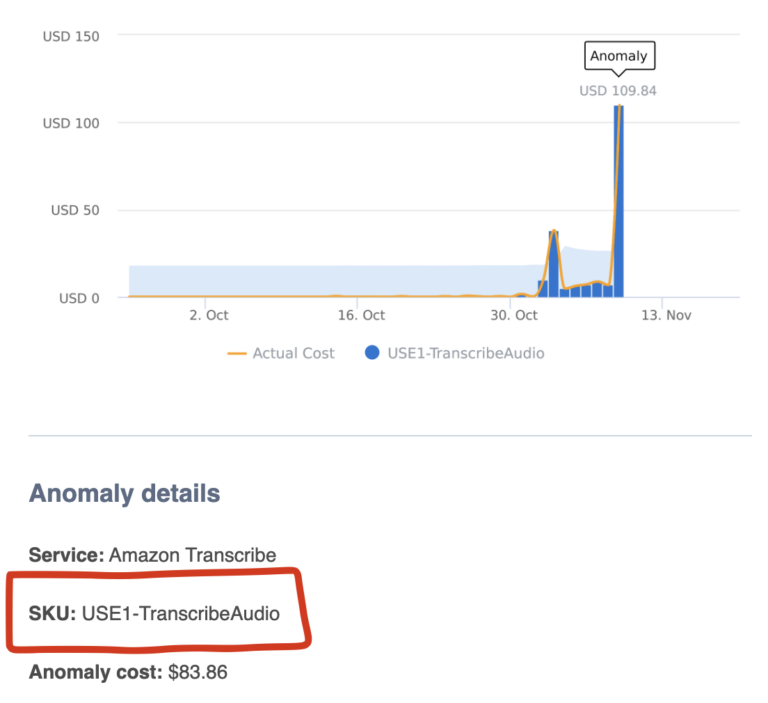
Alerta de anomalia enviado por e-mail
Se quiser ir mais fundo no Cloud Intelligence™, você também vê os recursos relevantes que estão contribuindo para o pico de custo. Isso ajuda a identificar exatamente o que causou o pico no nível mais granular e reduz o tempo médio para resolver a origem do problema.
No exemplo abaixo, vemos no Cloud Intelligence™ que uma anomalia foi detectada para o S3 — mais precisamente no SKU "DataTransfer-Out-Bytes". Dá para notar que basicamente três buckets do S3 estão por trás disso, com o "bucket-1" como principal responsável.
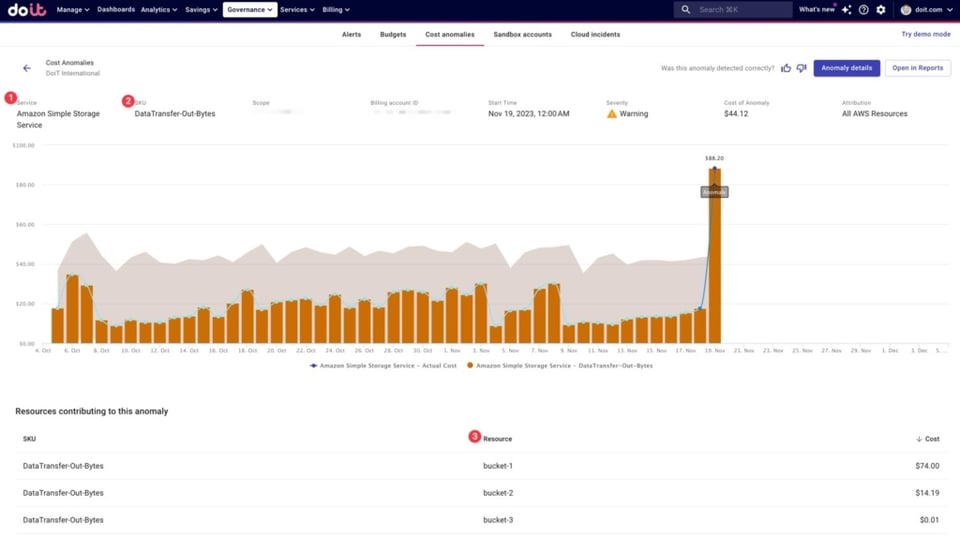
Exemplo de pico de custo detectado em um SKU do AWS S3
Além disso, você também recebe uma explicação sobre a anomalia e o SKU — afinal, nem sempre eles têm nomes amigáveis (ex.: "EUN1-LCUUsage") — junto com dicas relevantes de otimização.
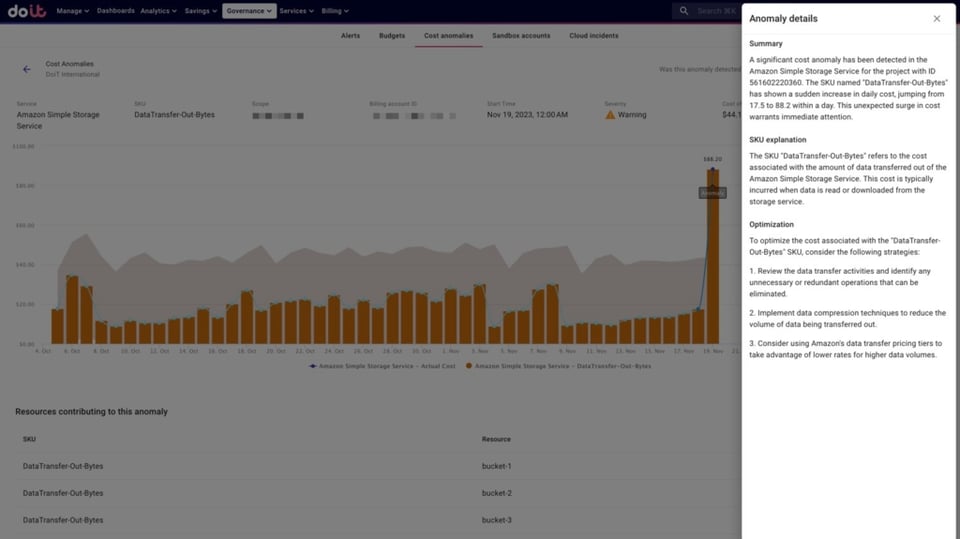
Explicação detalhada de uma anomalia detectada nos custos de transferência de dados do S3, junto com recomendações de otimização
Por que vale a pena personalizar os alertas para as partes da infraestrutura sob sua responsabilidade
O alerta de anomalias direcionado leva a detecção por SKU um passo adiante: seus times conseguem refinar os alertas que recebem e focar só nos custos de nuvem pelos quais respondem.
Em alguns casos, faz sentido entender a variação dentro de um único contexto. Por exemplo, a sazonalidade do negócio pode mascarar picos de custo em projetos de P&D.
Veja por que isso é tão importante:
- Relevância e foco: ao direcionar os alertas de detecção de anomalias para times específicos, você garante que cada stakeholder seja notificado apenas sobre anomalias que afetam diretamente a operação dele. Isso reduz a fadiga de alertas e ajuda os times a se concentrarem em ações sob seu controle.
- Resposta mais rápida: quando os times recebem alertas ligados aos próprios custos de nuvem, conseguem investigar a origem do problema rapidamente e tratar qualquer irregularidade. Essa abordagem direcionada acelera a resposta a incidentes e diminui o impacto que um pico de custo pode ter na fatura mensal.
- Otimização precisa: a detecção de anomalias funciona como uma lupa para apontar onde a otimização de custos é necessária. Quando os times são alertados sobre picos no próprio domínio, ficam mais motivados a otimizar o uso de recursos e aplicar boas práticas — o que gera economia geral e bons hábitos financeiros.
- Cultivar a responsabilização: com a detecção de anomalias direcionada, o senso de ownership e responsabilidade ganha força. Os times passam a ser diretamente responsáveis pelos próprios gastos de nuvem, alimentando uma cultura de consciência e prudência financeira.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Como configurar alertas de anomalias personalizados com a DoiT
Primeiro, você precisa definir os custos pelos quais cada time ou pessoa responde. No Cloud Intelligence™, isso é feito por meio das Attributions.
O que são Attributions?
Uma "Attribution" é um agrupamento lógico de recursos de nuvem que define uma categoria de custo específica para a sua empresa.
As Attributions ajudam a mapear os gastos de nuvem por times, aplicações, ambientes — qualquer categoria ou agrupamento que faça sentido para o seu negócio.
Por exemplo, digamos que sua empresa tenha três produtos distintos cujos custos você queira acompanhar. Nesse caso, os recursos de cada produto estão espalhados por várias contas AWS.
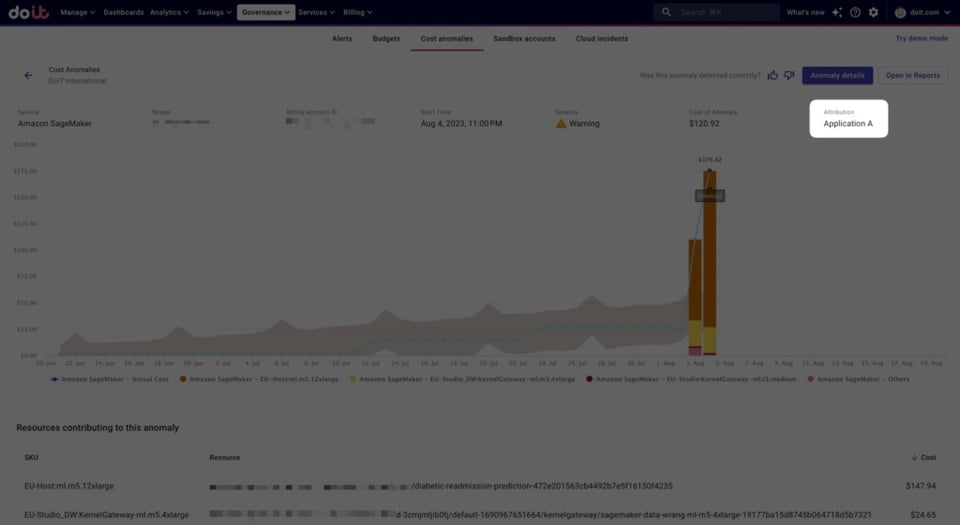
Com as Attributions, dá para agrupar várias contas AWS e dar a esse agrupamento o nome da nossa aplicação. Abaixo, um exemplo de "Application A" definida dessa forma.
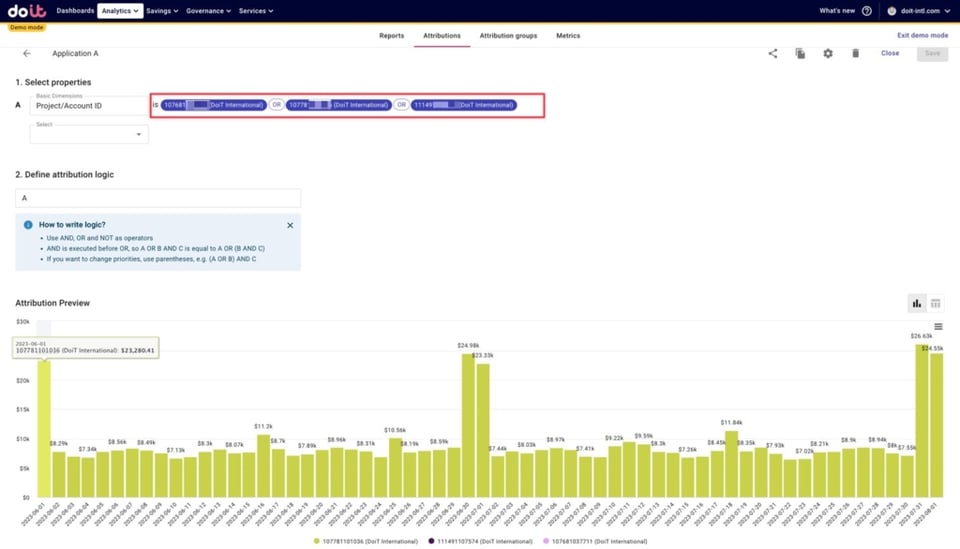
Exemplo de Attribution para uma aplicação hipotética
Agora, digamos que você queira que o pessoal de engenharia e produto que trabalha na Application A só seja alertado quando aparecer uma anomalia ligada a essa aplicação.
Depois que a Attribution é criada, basta ativar a Anomaly Detection para ela.
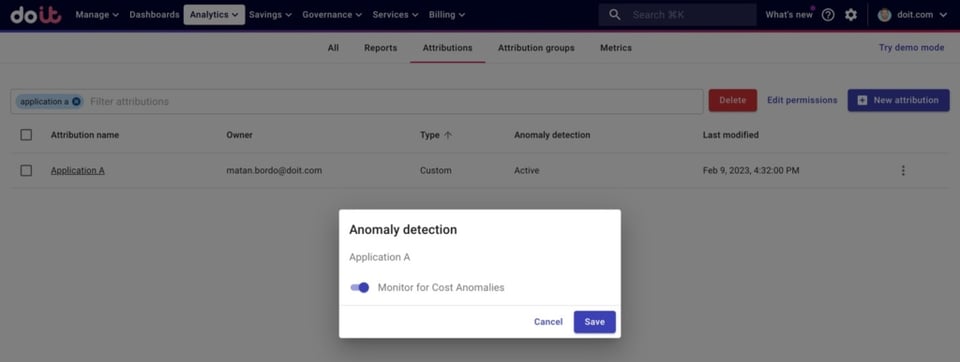
Ativando a Anomaly Detection para uma Attribution
Em seguida, é só entrar nas configurações de notificação dos responsáveis pela Application A e inscrevê-los nos alertas dessa Attribution (ou eles mesmos podem fazer isso).
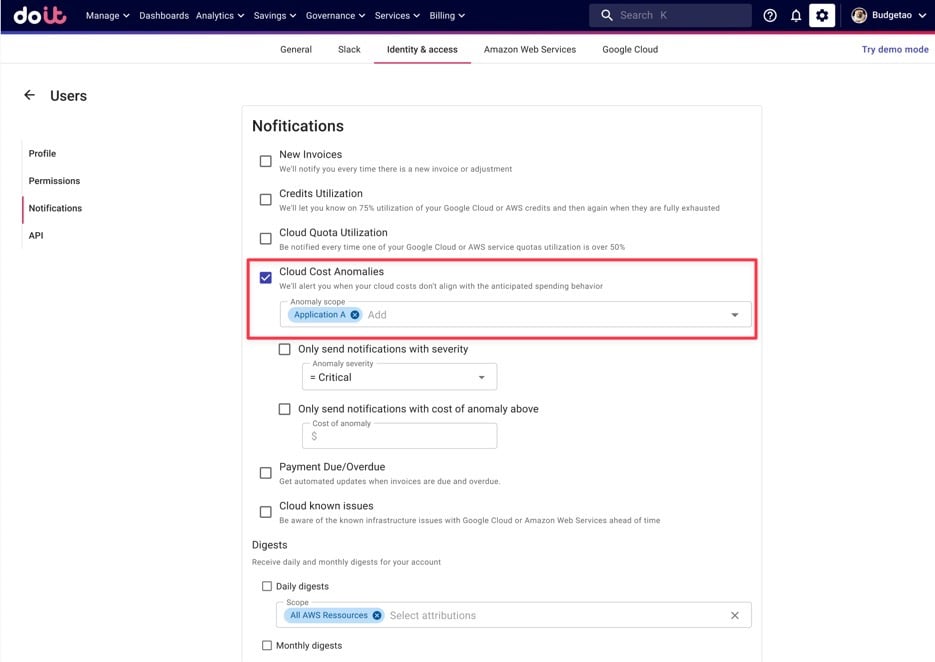
Inscrevendo-se nos alertas de anomalias para uma Attribution específica
Também dá para mandar esses alertas para um canal do Slack do time, caso ele tenha um.
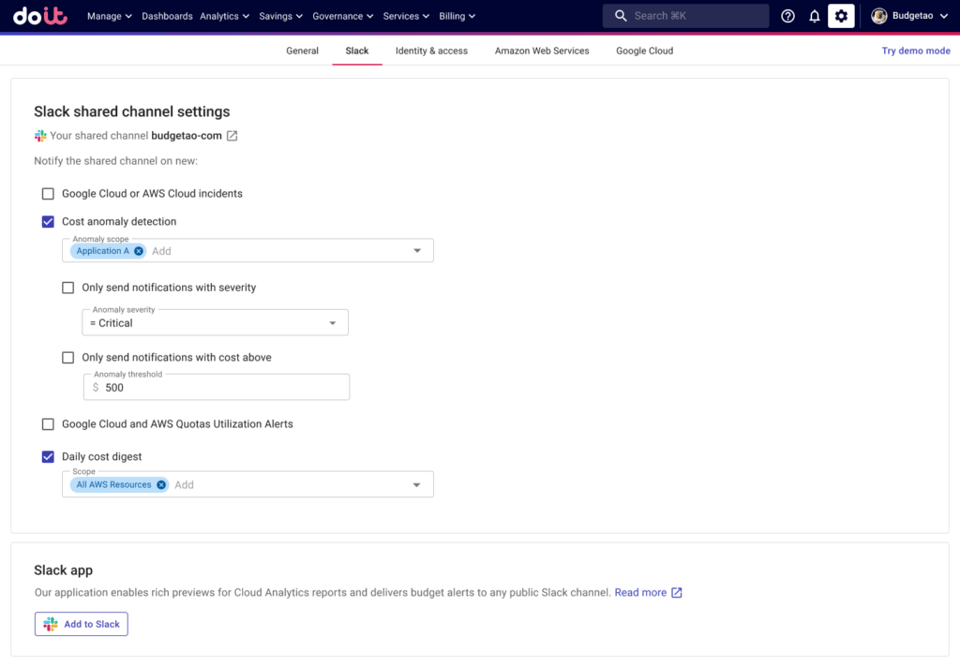 Envie os alertas de anomalias detectadas em uma Attribution para um canal compartilhado do Slack
Envie os alertas de anomalias detectadas em uma Attribution para um canal compartilhado do Slack
Quando um alerta de anomalia cai no Slack, você pode avaliá-lo para refinar nosso algoritmo ou abrir o caso no Cloud Intelligence™ para investigar mais a fundo.
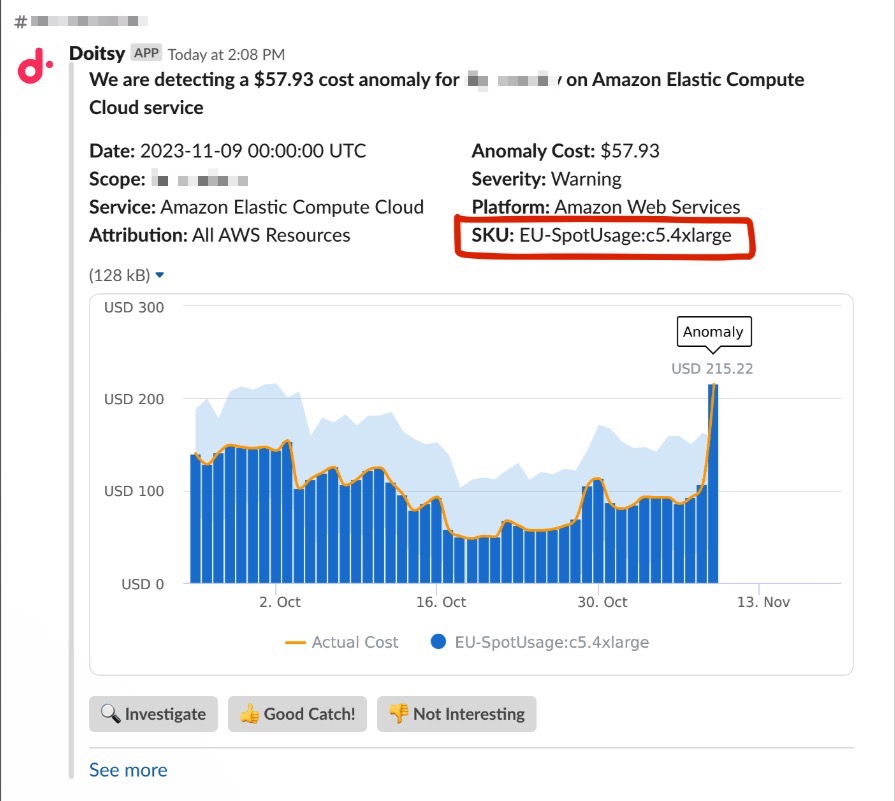
Alerta de anomalia enviado para um canal compartilhado do Slack
Quando uma anomalia é detectada em uma Attribution, o nome dela aparece na página da anomalia.
Quando o assunto é gestão de custos de nuvem, alertas em tempo real precisos e personalizados são essenciais para que seu time assuma de fato a responsabilidade pelos gastos.
O alerta por SKU no DoiT Anomaly Detection é um salto enorme rumo à redução real do tempo médio de resolução de picos de custo.
Combinado com alertas de anomalias mais precisos e direcionados, ele ajuda sua empresa a construir uma cultura de gastos responsáveis na nuvem, dando autonomia para que os times tomem decisões embasadas, respondam rápido a qualquer irregularidade e contribuam de forma proativa para o sucesso das suas iniciativas de nuvem.
Conforme sua empresa adota práticas de FinOps, esses recursos se tornam ferramentas indispensáveis para ampliar a visibilidade dos custos, otimizar a alocação de recursos e, no fim das contas, alcançar a excelência financeira na nuvem.
Se você já é cliente DoiT, é só começar a inscrever a si mesmo e aos stakeholders nos alertas de anomalias das partes da infraestrutura que cada um gerencia, direto no Cloud Intelligence™. Ainda não é cliente DoiT, mas quer aproveitar esse recurso junto com todo o portfólio de produtos da DoiT? Fale com a gente aqui.