SKU単位の異常検知とターゲット型アラートにより、コストスパイクの解決にかかる平均時間を短縮しつつ、責任あるクラウド利用の文化を醸成できます。

クラウド支出をコントロールしようとする企業の多くは、エンジニアやプロダクトチームに対し、自分たちが消費しているクラウドコストへの当事者意識を持つよう働きかけを強めています。それも当然のことです。
エンジニアやプロダクトオーナーが自らの仕事にかかるコストを把握していれば、機能開発やリリース後のモニタリングの段階でコスト意識が働きやすくなり、結果として収益にも直接プラスの影響を与えます。
関係者の意識を高めるうえでリアルタイムなレポーティングは依然として主要な手段ですが、それだけでは異常な挙動やコストスパイクに_素早く_対処することは難しいでしょう。リアルタイムの_アラート_もまた欠かせません。
しかしこれまでの標準的な異常検知の仕組みは、組織_全体_のクラウド利用状況をサービス単位のアラートで把握するものが主流でした。この大まかなアプローチには、次のような課題があります。
- あるサービスでコスト異常が発生した際、その原因となっているSKUやリソースを手作業で特定しなければならない
- 担当チームの業務に直接関係のないコスト異常まで通知されてしまう
こうした課題に応えるべく、DoiT Anomaly DetectionにSKU単位のアラート機能を追加しました。あわせて、自分が担当するインフラ領域に絞って異常アラートを受け取れるようになります。
本記事では、両機能のメリットと、Cloud Intelligence™でのカスタムアラートの設定方法をご紹介します。
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
クラウドコストは全員で持つ
FinOpsの重要な原則のひとつに「Everyone owns their costs(全員が自らのコストに責任を持つ)」があります。
コスト最適化の文化を根付かせるには、精度が高くパーソナライズされたデータを、然るべき担当者に届けることが前提となります。
レポートやダッシュボードと同じように、的確でパーソナライズされた異常アラートは社内の対話を生み、コストとその背景にあるインフラ判断への理解と説明責任を深めるきっかけとなります。
「なぜコストが急増したのか?想定どおりだったのか?次回はどう改善できるか?」
SKU単位の異常検知の仕組み
多くの企業がいまも異常アラートの自動化を模索するなか、DoiT Anomaly Detectionは導入してすぐに使えます。コストスパイクを自律的に監視し、異常な支出を検知すると通知するため、迅速に対応して請求への影響を最小限に抑えられます。Engineersが社内ツールを自前で構築・運用する必要はありません。
従来は、組織全体のクラウドリソース利用状況を観測し、プロジェクトやアカウントごとに_サービス単位_で「通常の挙動」を定義していました。
しかし、コストスパイクが検知・解決されないまま1分が経つたびに、銀行口座の蛇口を開けっ放しにしているのと同じ状態が続きます。気づくのが遅れるほど、財務面の影響と被害は大きくなり、原因特定に手作業が増えるほど損失も拡大していきます。
今回のアップデートにより、DoiT Anomaly DetectionはSKUごとに異常をスキャンするようになりました。異常な挙動が検知されると、該当のSKUを示すメール(設定済みであればSlackメッセージも)が届きます。
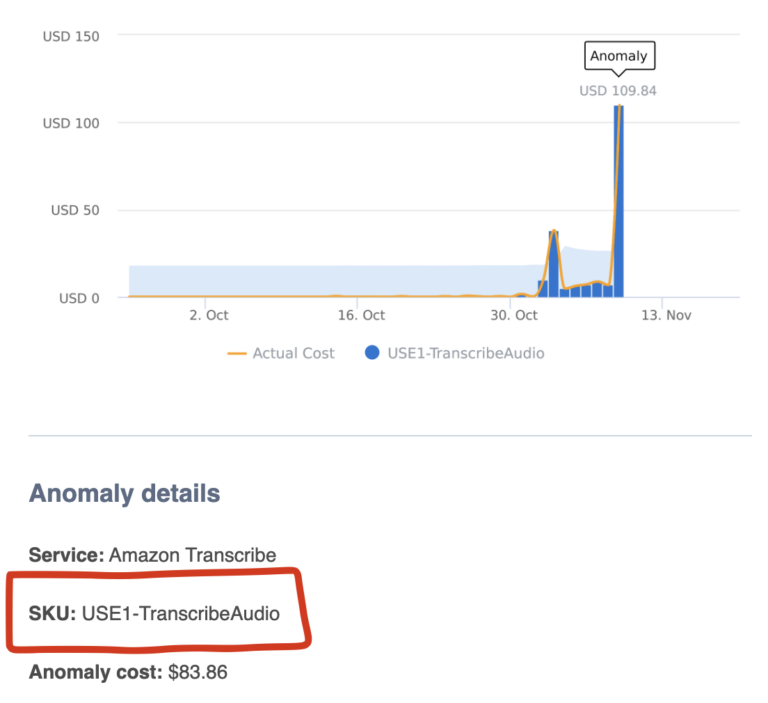
メールで届く異常アラート
Cloud Intelligence™でさらに掘り下げれば、コストスパイクに寄与している関連リソースまで確認できます。最も細かい粒度で原因をピンポイントに特定できるため、原因究明にかかる平均時間を短縮できます。
下の例では、Cloud Intelligence™上でS3、特に「DataTransfer-Out-Bytes」というSKUに異常が検知されたことがわかります。画面下部には主に3つのS3バケットが原因として表示されており、なかでも「bucket-1」が最大の要因と判明しています。
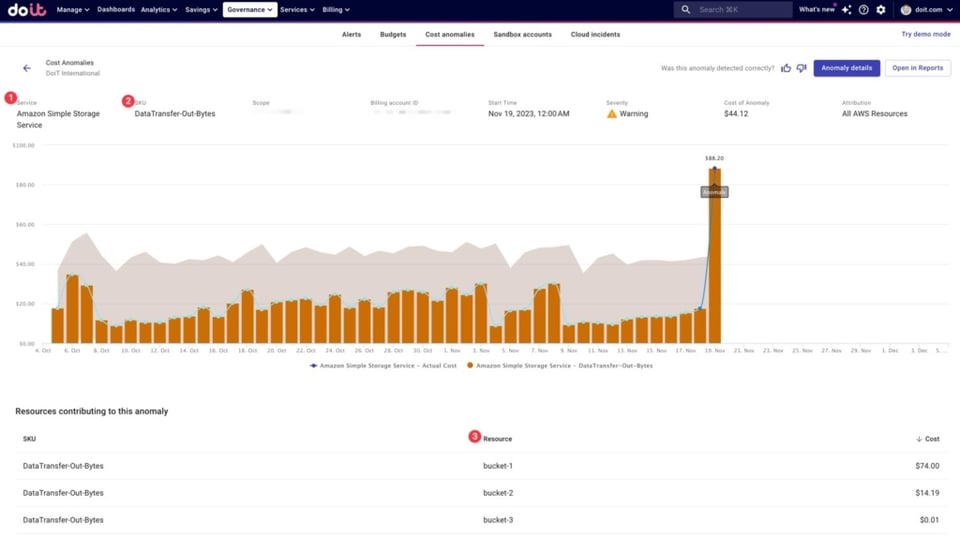
AWS S3のSKUで検知されたコストスパイクの例
さらに、異常そのものとSKUに関する解説も得られます。「EUN1-LCUUsage」のように、SKU名だけでは内容が分かりにくいことも少なくないためです。あわせて、関連する最適化のヒントも提示されます。
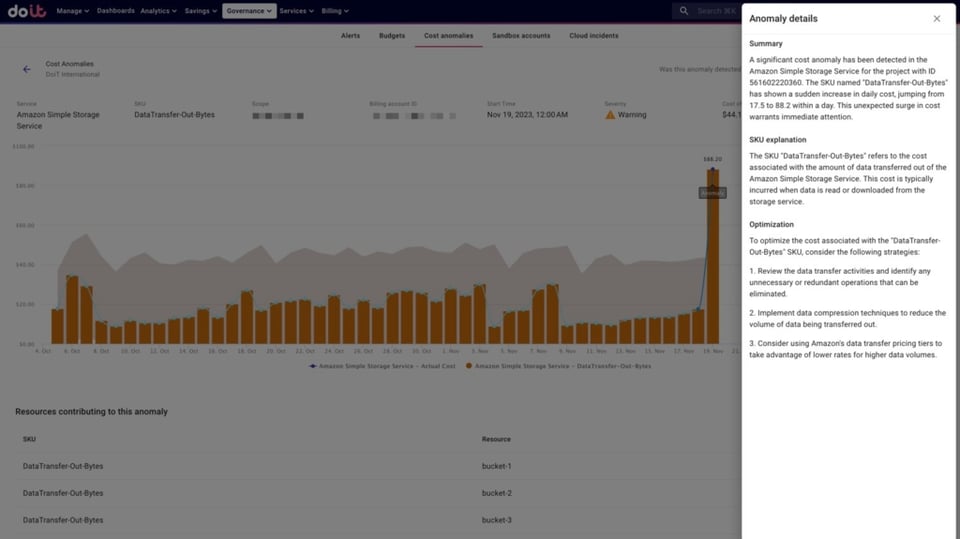
S3のデータ転送コストで検知された異常の詳細解説と最適化の推奨事項
担当インフラに合わせて異常アラートをパーソナライズすべき理由
ターゲット型の異常アラートは、SKU単位の検知をさらに一歩進めるものです。各チームが受け取るアラートを、自分たちが責任を負うクラウドコストに絞り込んでチューニングできます。
単一のコンテキスト内での変動を把握したい場面もあるはずです。たとえば、ビジネスの季節要因によってR&Dプロジェクトのコストスパイクが見えにくくなることがあります。
これが重要な理由は次のとおりです。
- 関連性とフォーカス: 異常検知アラートを特定のチーム向けに最適化することで、関係者は自分たちの業務に直接影響する異常_のみ_通知を受け取れます。アラート疲れを抑え、自分たちがコントロールできる対応に集中できます。
- 迅速な対応: 各チームが自分たちのクラウドコストに関するアラートを受け取れれば、原因をすぐに調査し、問題に対処できます。このターゲット型のアプローチによりインシデント対応時間が短縮され、月次請求への影響も最小限に抑えられます。
- 精緻な最適化: 異常検知は、コスト最適化が必要な領域を映し出すレンズになります。自分たちの担当領域内のコストスパイクに気づけば、リソース利用の最適化やベストプラクティスの実践への意欲も高まり、全体的なコスト削減と健全な財務習慣につながります。
- 説明責任の醸成: ターゲット型の異常検知により、オーナーシップと説明責任の意識が強まります。各チームが自分たちのクラウド支出を直接管理する立場となり、コスト意識と慎重さを大切にする文化が育っていきます。
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
DoiTでパーソナライズした異常アラートを設定する
まずは、各チームや個人が責任を負うコストを定義します。Cloud Intelligence™では、これをAttributionsを使って行います。
Attributionsとは?
「Attribution」とは、自社独自のコストカテゴリを定義する、クラウドリソースの論理的なグループのことです。
Attributionsを使えば、クラウド支出をチーム、アプリケーション、環境など、自社のビジネスに合った任意のカテゴリやグループにマッピングできます。
たとえば、自社で3つの異なるプロダクトのコストを追跡したいとします。各プロダクトのリソースは複数のAWSアカウントにまたがっているとしましょう。
Attributionsを使えば、複数のAWSアカウントをまとめて、そのグループにアプリケーション名を付けられます。下記は「Application A」をこのように定義した例です。
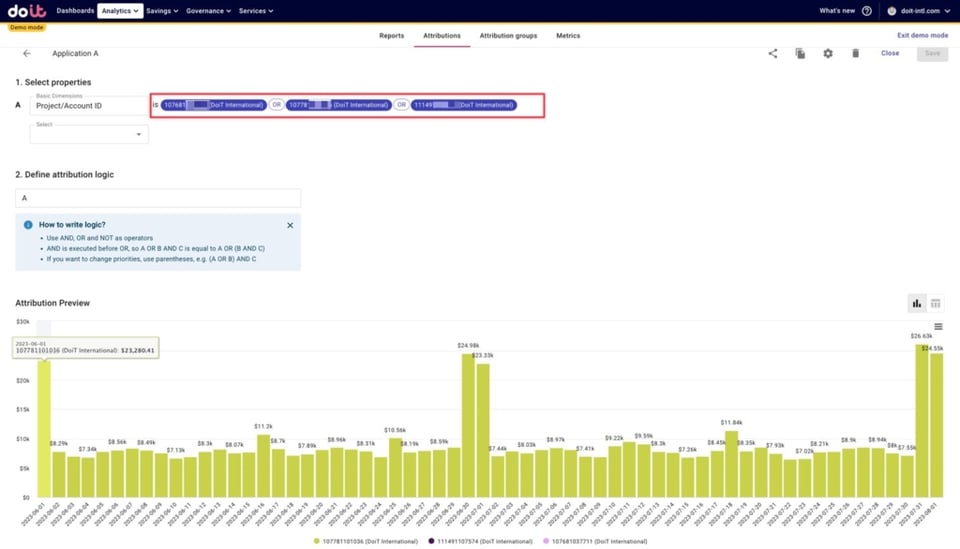
仮想アプリケーションのAttribution例
次に、Application Aを担当するEngineersやプロダクト担当者には、_このアプリケーション_に関連する異常が検知されたときだけアラートが届くようにしたいとします。
Attributionを作成したら、そのAttributionに対してAnomaly Detectionをオンに切り替えるだけです。
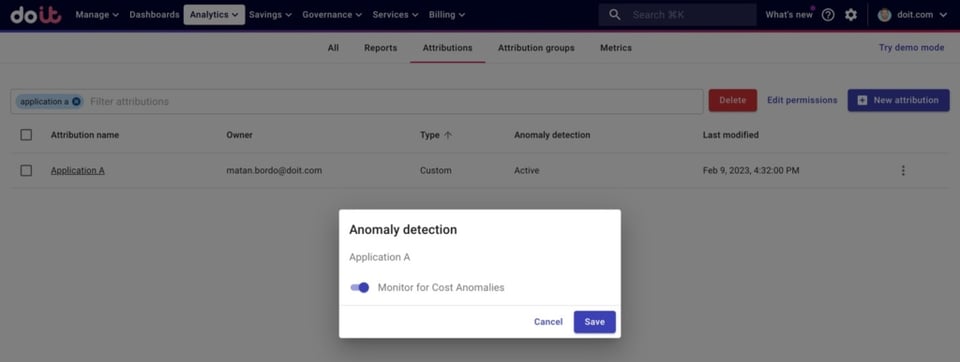
AttributionのAnomaly Detectionをオンにする
そのうえで、Application Aの担当者の通知設定を開き、そのAttributionに紐づくアラートを購読させます(本人が自分で設定することもできます)。
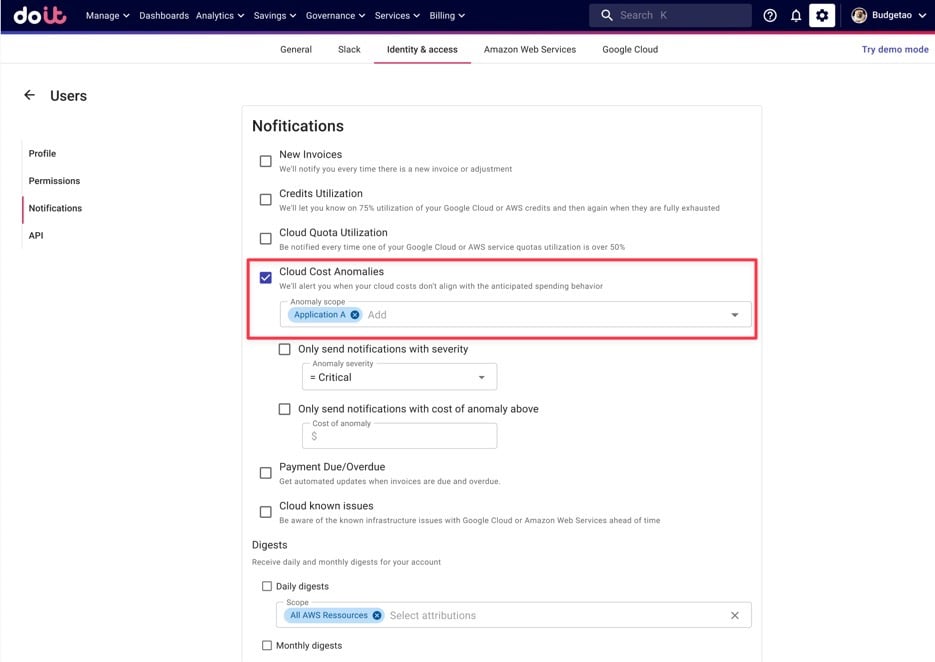
特定のAttributionの異常アラートを購読する
さらに、チーム共有のSlackチャンネルがあれば、そこへアラートを送ることもできます。
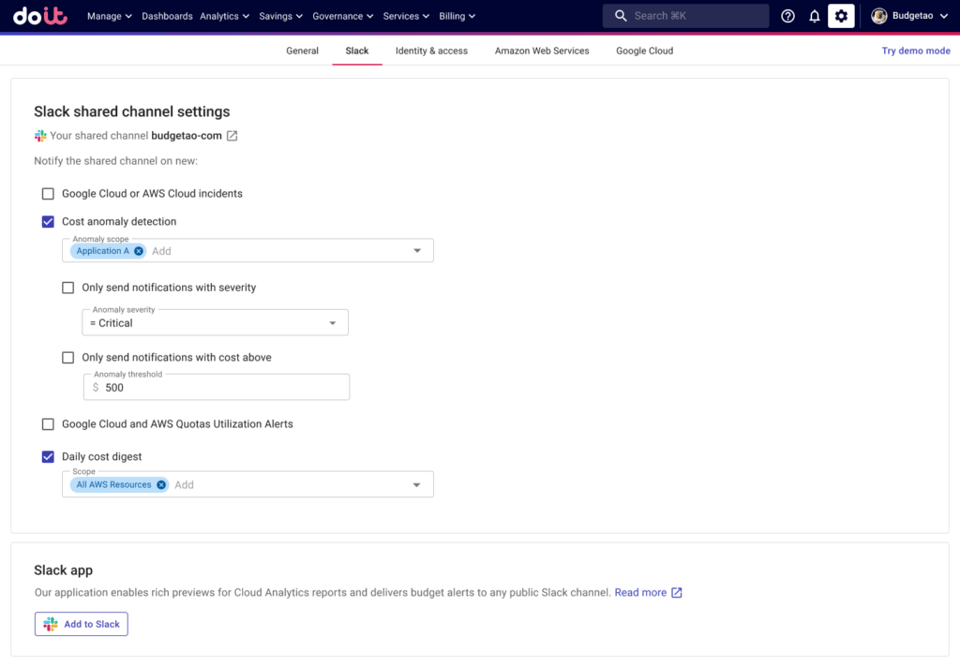 Attributionで検知された異常アラートを共有Slackチャンネルへ送信する
Attributionで検知された異常アラートを共有Slackチャンネルへ送信する
Slackに送信された異常アラートには、その場で評価を付けてアルゴリズムをチューニングすることも、Cloud Intelligence™でさらに詳しく調査することもできます。
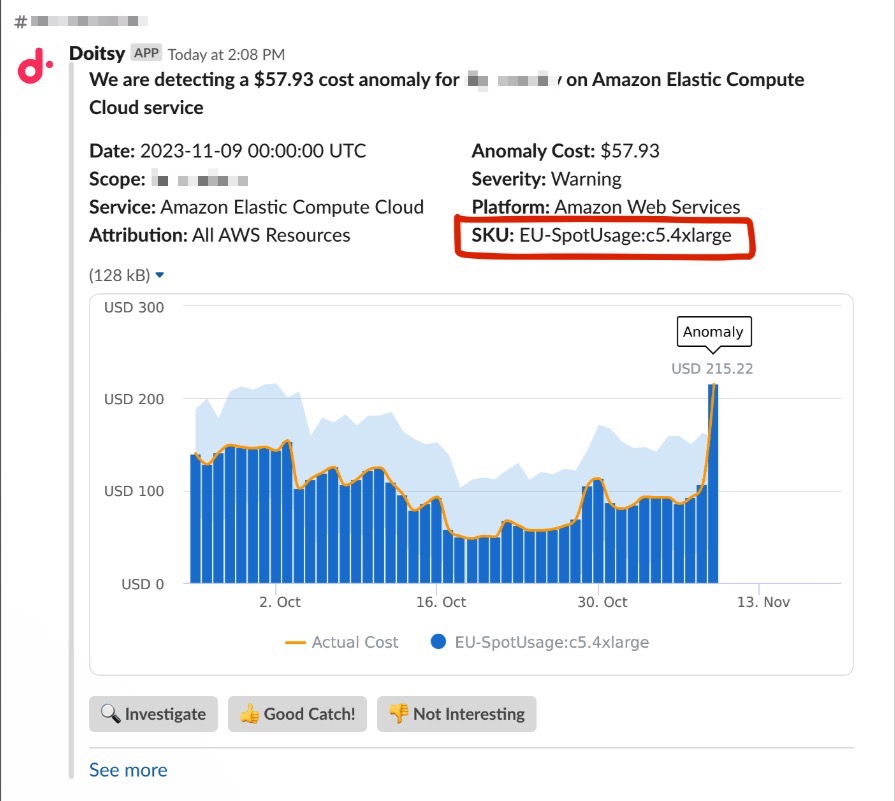
共有Slackチャンネルに届いた異常アラート
Attributionに対して異常が検知されると、その異常のページにAttribution名が表示されます。
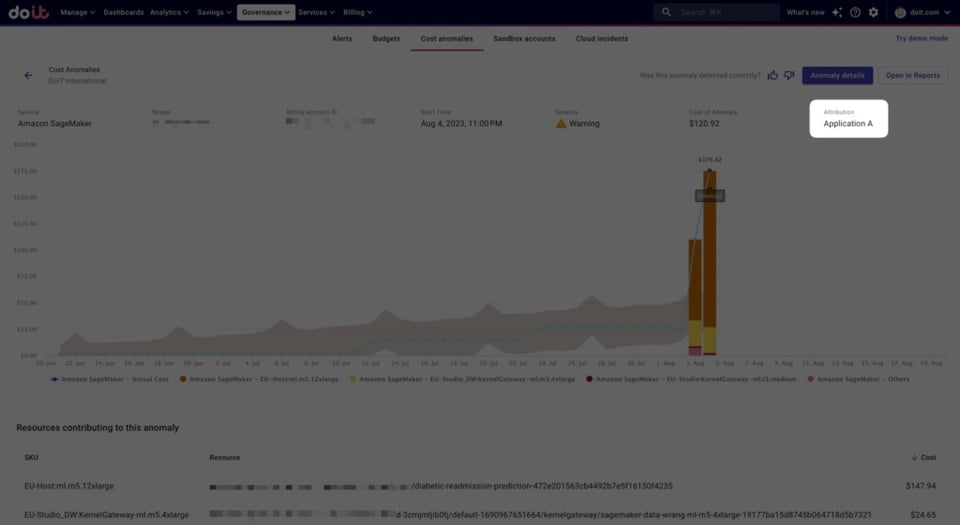
クラウドコスト管理において、_精緻_かつ_パーソナライズされた_リアルタイムアラートは、チームのコスト責任を確立するうえで欠かせない要素です。
DoiT Anomaly DetectionのSKU単位アラートは、コストスパイクの解決にかかる平均時間を実質的に短縮するための大きな前進です。
これにより精緻でターゲットを絞ったアラートが組み合わさることで、責任あるクラウド利用の文化が育ち、各チームが自律的に判断し、異常に素早く対応し、クラウド施策全体の成功に主体的に貢献できるようになります。
FinOpsの実践を進める企業にとって、これらの機能はコストの可視性を高め、リソース配分を最適化し、最終的にクラウドでの財務的な卓越性を実現するための強力なツールとなるはずです。
DoiTをご利用中のお客様は、Cloud Intelligence™から、ご自身や関係者が担当するインフラ領域に絞った異常アラートの購読をすぐに始められます。まだDoiTをご利用でない方で、本機能をはじめDoiTの幅広いプロダクトポートフォリオの活用にご関心がある方は、こちらからお問い合わせください。