Monitorer les jobs Kubernetes éphémères à grande échelle
 Comment nous avons résolu la perte de métriques, l'explosion de cardinalité et les dashboards cassés pour des workloads éphémères grâce à l'agrégation en streaming de vmagent
Comment nous avons résolu la perte de métriques, l'explosion de cardinalité et les dashboards cassés pour des workloads éphémères grâce à l'agrégation en streaming de vmagent
Introduction
Vous commencez à utiliser Kubernetes et déployez quelques applications par-ci par-là. Vous exposez des métriques, vous utilisez Prometheus et tout va pour le mieux dans le meilleur des mondes.
Vous avez quelques jobs à exécuter. Même package Prometheus, mêmes métriques exposées. Et soudain, une alerte se déclenche. Prometheus est en OOM. Vous regardez vos dashboards et, effectivement, une multitude de nouvelles séries temporelles sont apparues, toutes uniques par job_id. Vous vérifiez à nouveau et les dashboards semblent incorrects pour les jobs éphémères.
C'est une histoire que tout le monde finit par vivre, tôt ou tard.
Dans cet article, nous expliquons comment nous avons abordé le problème.
Contexte
Les jobs éphémères sont largement répandus dans Kubernetes :
- Workloads batch
- CronJobs
- Pipelines événementiels
- Compute optimisé en coût
Ils sont efficaces et scalables, mais ils posent des défis aux systèmes de monitoring conçus pour des services à longue durée de vie.
Il existe deux familles de systèmes de monitoring : ceux en pull et ceux en push. Avec un système push, vous envoyez les données quand bon vous semble. Les systèmes pull, eux, scrapent les cibles à intervalle régulier.
Prometheus (entre autres) fonctionne en pull par défaut. Il maintient un inventaire de cibles, scrape les métriques à intervalle T au format Prometheus depuis un endpoint donné, puis les stocke dans une base de données locale.
Pour les jobs éphémères, le problème vient de l'intervalle : si un job se termine entre T1 et T2, ses métriques ne seront jamais scrapées. Autre écueil fréquent : la cardinalité. Chaque job aura soit un pod_name, soit un autre identifiant unique, ce qui rend chaque série temporelle unique aux yeux de Prometheus.
Nous avons un grand nombre de ces jobs et ils sont mission-critical. Perdre des métriques est inacceptable : cela peut fausser le calcul de nos SLO, générer des faux négatifs sur les alertes et nous priver de données essentielles à la prise de décision. À cela s'ajoute la cardinalité des noms de pods, particulièrement élevée pour ces jobs. Prometheus est devenu gourmand en mémoire dans notre cluster, et toute requête s'appuyant sur ces métriques était lente et consommait énormément de ressources.
Énoncé du problème
- Collecter l'intégralité des métriques des jobs éphémères
- Garantir l'exactitude des métriques
- Maintenir un coût et des performances raisonnables
- Supporter à la fois le dashboarding et l'alerting
- Rendre l'ensemble engineer-friendly (package partagé, facile à réutiliser)
Nous avons commencé par les indispensables avant de nous attaquer à l'UX. Autrement dit : d'abord la collecte et l'exactitude, puis le coût, les performances et les packages partagés.
Point de départ
Approche brute :
- Utiliser Prometheus Pushgateway
- Enregistrer les métriques avec le registry par défaut
- Pousser les métriques à la fin du job
pusher := metric.NewPusher("reports", cfg.PromPushGatewayAddr)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Petite amélioration : ajouter un pusher périodique. Il s'agit d'une goroutine qui pousse les métriques dans la push gateway à intervalles réguliers.
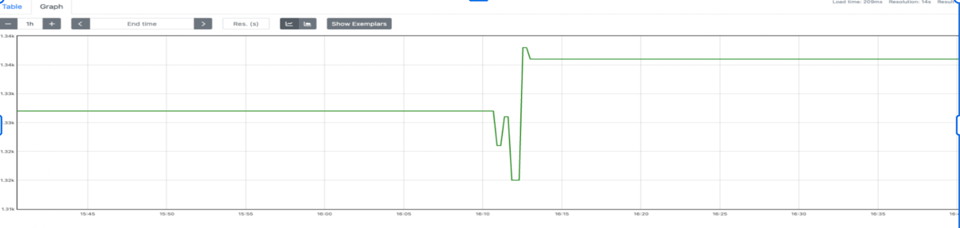
pusher := metric.NewPusher(jobName, cfg.PromPushGatewayAddr)pusher.PushPeriodicMetrics(logger.With(), 30*time.Second)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Cette approche valait mieux que rien, mais nous avons rapidement constaté des problèmes d'exactitude. À chaque push, des collisions de métriques se produisaient entre les jobs. Résultat : la valeur finale stockée dans Prometheus était écrasée, et les compteurs montaient puis redescendaient (un vrai problème d'exactitude).
Nous avons décidé d'ajouter pod_name pour éviter ces collisions et garantir l'exactitude. POD_NAME provient de la Downward API de Kubernetes.
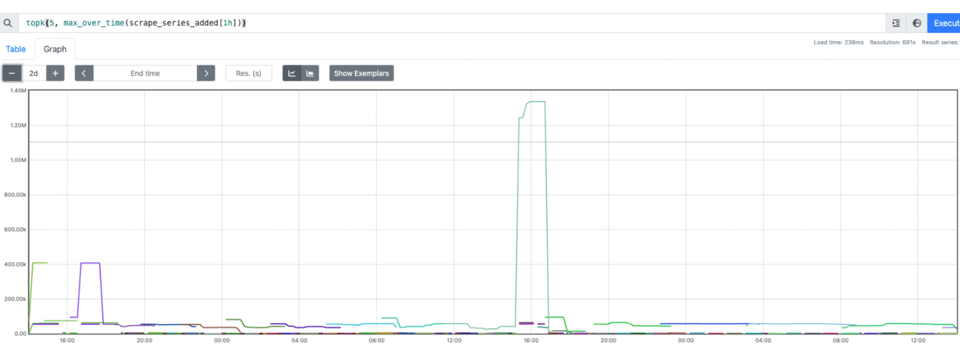
podName, exists := os.LookupEnv("POD_NAME")if !exists { podName = cfg.Conf.SvcID}pusher := metric.NewPusher(podName, cfg.PromPushGatewayAddr)Après vérification, les données semblaient correctes. Mais impossible de construire des dashboards ou des alertes. En clair : increase ne fonctionnait pas. Pour qu'increase fonctionne, il faut calculer le delta entre T1 et T2. Or les données n'arrivaient qu'à T2 ; donc si la métrique était absente lors du premier scrape (le premier push n'ayant pas eu lieu), pas de delta, pas d'increase. Nous avons aussi observé que Prometheus consommait énormément de mémoire. Les jobs éphémères sont par nature éphémères, nous en avons beaucoup, chacun avec son propre nom de pod unique, ce qui fait exploser la cardinalité.
Nous avions donc des données correctes et un package partagé simple d'utilisation. Restait à couvrir la construction des dashboards et des alertes, l'amélioration des performances et la réduction des coûts.
Amélioration
Nous avons commencé par l'évidence : utiliser les recording rules natives de Prometheus. Nous avons ajouté ceci :
record: metric_name:aggrexp: sum(metric_name) without (job)
Problème : increase ne fonctionnait toujours pas. Pour les métriques poussées fréquemment, ça passait, mais pour les jobs éphémères et peu fréquents, la valeur initiale 0 (pourtant essentielle) faisait défaut.
Problème plus sérieux : la mémoire de Prometheus continuait de grimper. Et en plus, nous recalculions et stockions cette expression à chaque intervalle N, ce qui entraînait une forte consommation CPU.
Affinage final
Voici ce que nous recherchions : avant que Prometheus ne stocke quoi que ce soit, effectuer d'abord l'agrégation et ne stocker que le résultat. En bonus, pousser un 0 avant l'apparition de la valeur réelle. Autre bonus : pouvoir définir d'autres règles d'agrégation avec un impact minimal sur les dashboards et les alertes, et faciles à adopter pour les équipes d'engineering. Quelque chose comme ceci, mais en langage Prometheus :
SELECT *, SUM(value)FROM METRICSWHERE METRIC_NAME LIKE 'COUNT'GROUP BY * WITHOUT JOB;Entre en scène l'agrégation en streaming de vmagent. vmagenthttps://docs.victoriametrics.com/victoriametrics/vmagent/ est un agent de collecte de métriques léger et haute performance, conçu par VictoriaMetrics pour scraper, traiter et ingérer des données issues de sources variées vers les systèmes de monitoring. Il fait exactement ce qu'on attend de lui : il joue le rôle de push gateway et pousse des métriques agrégées dans Prometheus.
Exemple de règle pour les métriques de type count que nous poussons :
- match: '{__name__=~".+_count"}' interval: 2m outputs: ["total"] without: ["pod_name"] staleness_interval: 15m keep_metric_names: true flush_on_shutdown: trueEt nos graphiques se sont mis à ressembler exactement à ce que nous attendions.
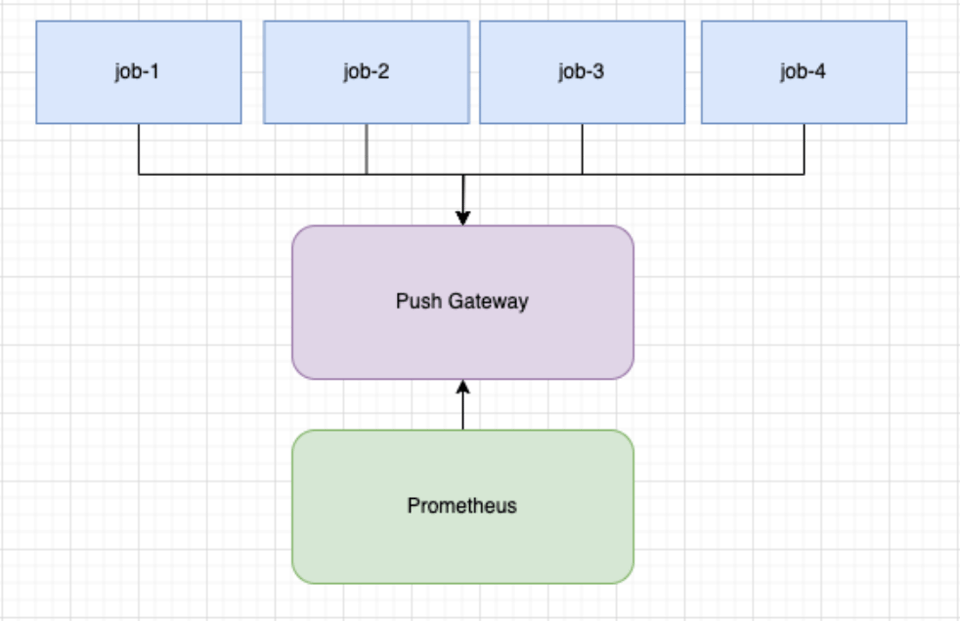
Solution finale
+-----------------------------+| K8s Jobs || (shared metrics package) |+-------------+---------------+ | | push metrics v+-----------------------------+| Push Endpoint || (e.g. Pushgateway) |+-------------+---------------+ | | metrics flow v+-----------------------------+| vmagent || (streaming aggregation) || - reduce cardinality || - aggregate counters |+-------------+---------------+ | | push v+-----------------------------+| Prometheus || (stores aggregated data) |+-----------------------------+Pour résumer le flux : un package partagé pousse périodiquement les métriques dans vmagent. Il inclut pod_name comme label. En fin d'exécution, il effectue un dernier push.
Les données arrivent dans vmagent, qui maintient l'état d'agrégation. Il additionne les compteurs entrants par nom de métrique. À chaque intervalle, il pousse le résultat vers Prometheus.
Nous avons désormais satisfait toutes nos exigences.
Limites
Pré-agréger les données implique de perdre la donnée brute. Impossible, par exemple, de récupérer les métriques d'un pod spécifique.
vmagent conserve un état. En cas de redémarrage, on repart de 0. C'est acceptable pour les dashboards et les alertes, et un simple sum() permet de combler les écarts. En revanche, pendant l'indisponibilité de vmagent, des données seront perdues.
En outre, nous exploitons désormais un composant supplémentaire qu'il faut configurer et maintenir.
Monitorer des workloads éphémères à grande échelle exige bien plus que les outils par défaut : cela demande des choix d'architecture délibérés. Si votre équipe se heurte à des défis similaires d'observabilité Kubernetes, nos ingénieurs peuvent vous aider à concevoir et déployer des solutions adaptées à votre stack. En savoir plus sur https://www.doit.com/solutions/forward-deployed-engineering.