Monitorare job Kubernetes brevi su larga scala
 Come abbiamo risolto la perdita di metriche, l'esplosione di cardinalità e le dashboard inaffidabili sui workloads effimeri grazie alla streaming aggregation di vmagent
Come abbiamo risolto la perdita di metriche, l'esplosione di cardinalità e le dashboard inaffidabili sui workloads effimeri grazie alla streaming aggregation di vmagent
Introduzione
Inizia a usare Kubernetes e a distribuire qualche applicazione qua e là. Espone le metriche, adotta Prometheus e tutto fila liscio. Va tutto bene.
Poi ha qualche job da eseguire. Stesso pacchetto Prometheus, stesse metriche esposte. All'improvviso scatta l'alert. Prometheus è in OOM. Apre le dashboard e in effetti compaiono moltissime nuove serie temporali, tutte univoche per job_id. Verifica di nuovo le dashboard e si accorge che, per i job brevi, i dati non tornano.
È una storia in cui, prima o poi, ci si imbatte tutti.
In questo articolo raccontiamo come l'abbiamo affrontata.
Contesto
I job di breve durata sono molto diffusi in Kubernetes:
- workloads batch
- CronJob
- Pipeline event-driven
- Compute ottimizzato per i costi
Sono efficienti e scalabili, ma mettono in difficoltà i sistemi di monitoraggio pensati per servizi di lunga durata.
Esistono due famiglie di sistemi di monitoraggio: pull-based e push-based. Con i sistemi push-based si inviano i dati quando si vuole. I sistemi pull-based effettuano lo scrape dei target a intervalli prefissati.
Prometheus (e altri) sono pull-based di default. Mantengono un inventario dei target, effettuano lo scrape delle metriche a intervalli T in formato Prometheus da un endpoint specificato e le archiviano in un database locale.
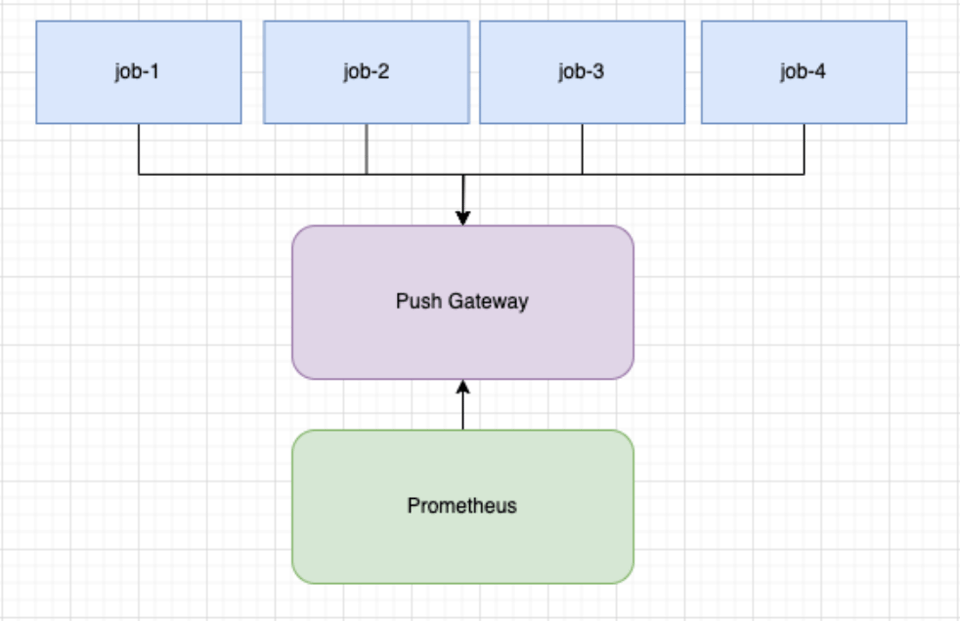
Per i job brevi questo meccanismo non regge sull'intervallo: se un job termina tra T1 e T2, le sue metriche non verranno mai raccolte. Un altro problema ricorrente è la cardinalità. Ogni job avrà un pod_name o un altro identificatore univoco, rendendo ogni serie temporale unica agli occhi di Prometheus.
Di job così ne abbiamo molti e sono mission critical. Perdere metriche non è accettabile: rischiamo di calcolare male gli SLO, di ricevere alert falsi negativi e di perdere dati cruciali per le decisioni. A ciò si aggiunge che la cardinalità dei pod name per questi job è notevole. Prometheus è diventato un divoratore di memoria nel nostro cluster e qualsiasi query basata su queste metriche risultava lenta e onerosa in termini di risorse.
Definizione del problema
- Raccogliere tutte le metriche dei job brevi
- Garantire la correttezza delle metriche
- Mantenere costi e prestazioni ragionevoli
- Supportare sia dashboarding sia alerting
- Renderlo engineer friendly (pacchetto condiviso, facile da riutilizzare)
Saremmo partiti dai requisiti irrinunciabili e poi ci saremmo concentrati sulla UX. Significa prima raccolta e correttezza, poi costi, prestazioni e pacchetti condivisi.
Punto di partenza
Approccio grezzo:
- Usare Prometheus Pushgateway
- Registrare le metriche con il registry di default
- Inviare le metriche al completamento del job
pusher := metric.NewPusher("reports", cfg.PromPushGatewayAddr)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Come piccolo miglioramento possiamo aggiungere un pusher periodico. Si tratta di una goroutine che invia periodicamente le metriche al push gateway.
pusher := metric.NewPusher(jobName, cfg.PromPushGatewayAddr)pusher.PushPeriodicMetrics(logger.With(), 30*time.Second)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Meglio di niente, ma abbiamo riscontrato problemi di correttezza. A ogni push si verificavano collisioni di metriche tra job diversi. Il risultato era che il valore finale veniva sovrascritto in Prometheus, facendo oscillare i contatori in alto e in basso (un problema di correttezza).
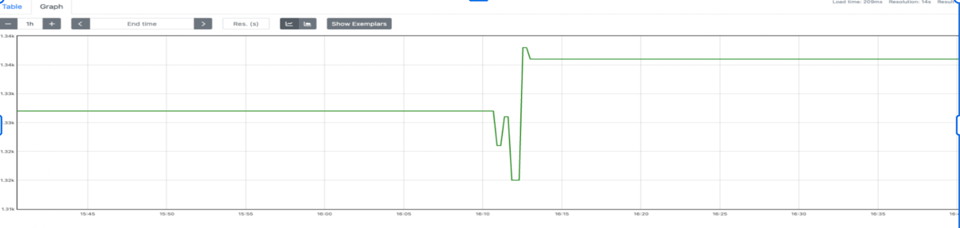
Abbiamo deciso di aggiungere pod_name per evitare queste collisioni e garantire la correttezza. POD_NAME sarebbe stato fornito dalla Downward API di Kubernetes.
podName, exists := os.LookupEnv("POD_NAME")if !exists { podName = cfg.Conf.SvcID}pusher := metric.NewPusher(podName, cfg.PromPushGatewayAddr)Verificando i dati, sembravano corretti. Tuttavia non riuscivamo a costruire dashboard né alert. In poche parole, increase non funzionava. Perché increase funzioni serve calcolare il delta tra T1 e T2. I dati però arrivavano solo a T2, quindi se la metrica era assente al primo scrape (il primo push non avviene) non c'è delta e non c'è increase. Abbiamo notato inoltre che Prometheus iniziava a consumare moltissima memoria. I job brevi sono brevi, ne abbiamo tanti, ognuno con il proprio pod name univoco, e la cardinalità schizza in alto.
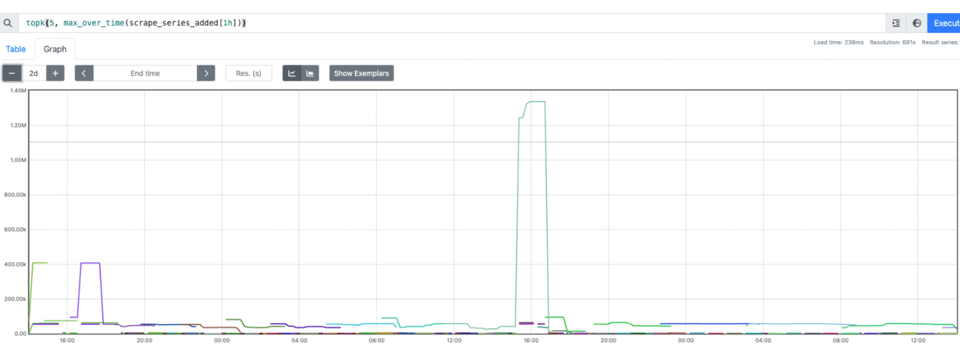
Avevamo quindi dati corretti e un pacchetto condiviso facile da usare. Restavano da risolvere la costruzione di dashboard e alert, il miglioramento delle prestazioni e la riduzione dei costi.
Miglioramento
Abbiamo iniziato dalla soluzione più ovvia: usare le recording rule integrate di Prometheus. Abbiamo aggiunto questo:
record: metric_name:aggrexp: sum(metric_name) without (job)
Il limite di questo approccio era che increase continuava a non funzionare. Per le metriche inviate di frequente andava bene, ma per i job brevi e poco frequenti mancava l'importante valore iniziale di 0.
Problema ancora più grave: la memoria di Prometheus continuava a crescere. Oltre alla memoria, l'espressione veniva ricalcolata e memorizzata una volta ogni N intervalli, generando anche un consumo elevato di CPU.
Affinamento finale
Ciò che volevamo era questo: prima che Prometheus memorizzi qualunque cosa, eseguire l'aggregazione e solo dopo archiviare il risultato. Un plus sarebbe stato inviare uno 0 prima della comparsa del valore effettivo. Un ulteriore plus poter contare su altre regole di aggregazione, con modifiche minime a dashboard e alert e di facile adozione per i team di engineering. Qualcosa di simile a questo, ma in linguaggio Prometheus:
SELECT *, SUM(value)FROM METRICSWHERE METRIC_NAME LIKE 'COUNT'GROUP BY * WITHOUT JOB;Entra in scena la streaming aggregation di vmagent. vmagenthttps://docs.victoriametrics.com/victoriametrics/vmagent/ è un agente di raccolta metriche leggero e ad alte prestazioni, progettato da VictoriaMetrics per effettuare lo scrape, elaborare e ingerire dati da diverse sorgenti nei sistemi di monitoraggio. Fa esattamente questo: si comporta come un push gateway e invia metriche aggregate a Prometheus.
Esempio di regola per le metriche count che inviamo:
- match: '{__name__=~".+_count"}' interval: 2m outputs: ["total"] without: ["pod_name"] staleness_interval: 15m keep_metric_names: true flush_on_shutdown: trueE i nostri grafici hanno iniziato ad apparire esattamente come ce li aspettavamo.
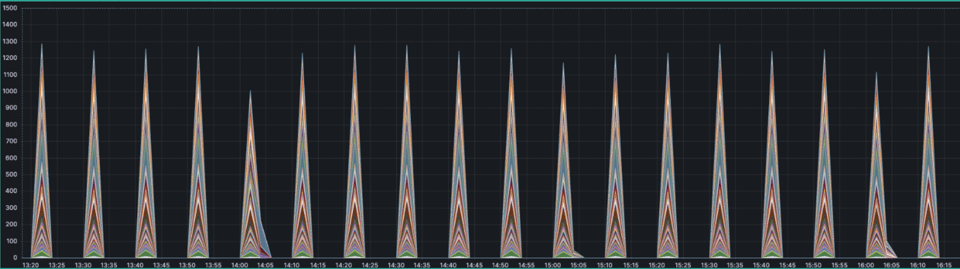
Soluzione finale
+-----------------------------+| K8s Jobs || (shared metrics package) |+-------------+---------------+ | | push metrics v+-----------------------------+| Push Endpoint || (e.g. Pushgateway) |+-------------+---------------+ | | metrics flow v+-----------------------------+| vmagent || (streaming aggregation) || - reduce cardinality || - aggregate counters |+-------------+---------------+ | | push v+-----------------------------+| Prometheus || (stores aggregated data) |+-----------------------------+Per evidenziare il flusso: un pacchetto condiviso invia periodicamente le metriche a vmagent, includendo pod_name come label. A fine esecuzione esegue un push finale.
I dati arrivano a vmagent, che mantiene lo stato dell'aggregazione. Somma i contatori in ingresso per nome metrica. Una volta per intervallo invia il risultato a Prometheus.
A questo punto abbiamo soddisfatto tutti i nostri requisiti.
Problemi
Pre-aggregare i dati significa perdere i dati grezzi. Se qualcuno vuole recuperare le metriche di un pod specifico, non è più possibile.
vmagent mantiene lo stato. In caso di reset si riparte da 0. Per dashboard e alert va bene e si può usare una normale sum() per coprire le lacune. Tuttavia, durante l'indisponibilità di vmagent perdiamo dati.
A tutto questo si aggiunge un componente in più da configurare e gestire.
Monitorare workloads brevi su larga scala richiede ben più degli strumenti predefiniti: servono scelte architetturali consapevoli. Se il suo team sta affrontando sfide simili di observability su Kubernetes, i nostri engineer possono aiutarla a progettare e implementare soluzioni su misura per il suo stack. Scopra di più su https://www.doit.com/solutions/forward-deployed-engineering.