Monitorando Kubernetes Jobs de Curta Duração em Escala
 Como resolvemos perda de métricas, explosão de cardinalidade e dashboards quebrados em workloads efêmeros usando a streaming aggregation do vmagent
Como resolvemos perda de métricas, explosão de cardinalidade e dashboards quebrados em workloads efêmeros usando a streaming aggregation do vmagent
Introdução
Você começa a usar Kubernetes e sobe algumas aplicações aqui e ali. Passa a expor métricas, usa o Prometheus e está tudo lindo. Tudo certo.
Aí surgem alguns jobs que você precisa rodar. Mesmo pacote do Prometheus, expõe as métricas. De repente, o alerta começa a apitar. O Prometheus está em OOM. Você abre os dashboards e, de fato, há um monte de novas time series, todas únicas por job_id. Confere os dashboards de novo e eles aparentam estar incorretos para jobs de curta duração.
Essa é uma história que todo mundo vive mais cedo ou mais tarde.
Neste artigo, vamos compartilhar como encontramos uma forma de lidar com isso.
Contexto
Jobs de curta duração são amplamente usados no Kubernetes:
- workloads em batch
- CronJobs
- Pipelines orientados a eventos
- Compute otimizado para custo
São eficientes e escaláveis, mas trazem desafios para sistemas de monitoramento pensados para serviços de longa duração.
Existem duas classes de sistemas de monitoramento: pull-based e push-based. Em sistemas push-based, você envia os dados quando quiser. Sistemas pull-based fazem scrape dos targets em um intervalo de tempo definido.
O Prometheus (e outros) é pull-based por padrão. Ele mantém um inventário de targets, faz scrape das métricas em um intervalo T no formato Prometheus a partir de um endpoint especificado e armazena tudo em um banco de dados local.
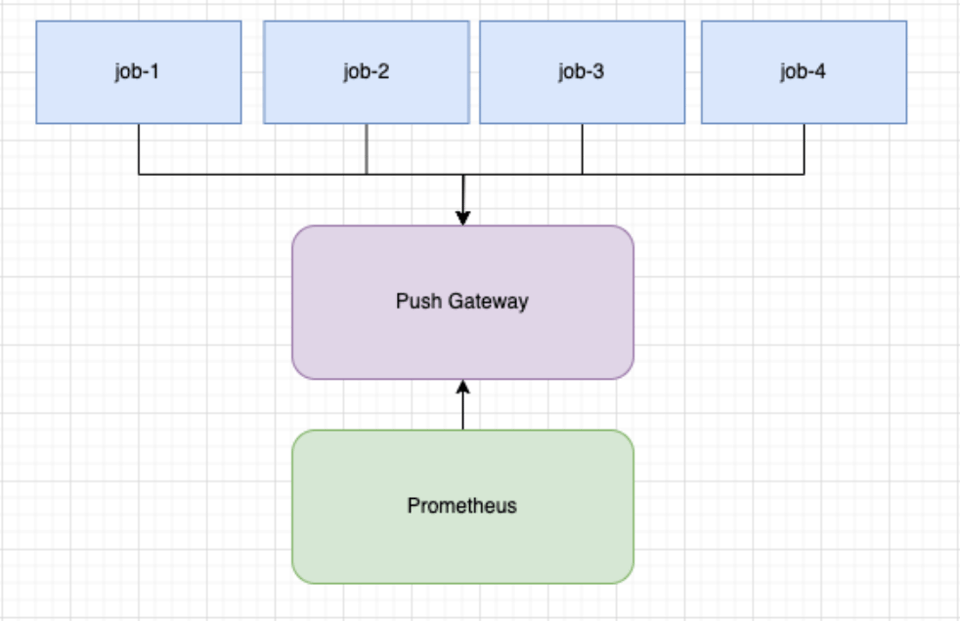
Para jobs de curta duração, o problema está no intervalo: se um job morre entre T1 e T2, suas métricas não serão coletadas. Outro problema comum é a cardinalidade. Cada job vai ter um pod_name ou algum outro identificador único, fazendo com que cada time series seja única aos olhos do Prometheus.
Temos muitos jobs assim e eles são críticos para o negócio. Perder qualquer métrica não é aceitável, pois podemos calcular SLOs de forma incorreta, ter alertas falso-negativos e ficar sem dados importantes para tomar decisões. Além disso, a cardinalidade dos nomes de pod desses jobs é enorme. O Prometheus virou um devorador de memória no nosso cluster, e qualquer query usando essas métricas ficava lenta e consumia muitos recursos.
Definição do problema
- Coletar todas as métricas dos jobs de curta duração
- Garantir a corretude das métricas
- Manter custo e performance razoáveis
- Suportar tanto dashboards quanto alertas em cima disso
- Ser amigável para os engenheiros (pacote compartilhado, fácil de reutilizar)
Começaríamos pelos itens "obrigatórios" e depois trabalharíamos na UX. Ou seja: coleta e corretude primeiro, depois custo, performance e pacotes compartilhados.
Ponto de partida
Abordagem inicial:
- Usar o Prometheus Pushgateway
- Registrar as métricas no registry padrão
- Fazer push das métricas ao finalizar o job
pusher := metric.NewPusher("reports", cfg.PromPushGatewayAddr)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Como uma pequena melhoria, podemos adicionar um pusher periódico. Trata-se de uma goroutine que faz push das métricas para o push gateway de tempos em tempos.
pusher := metric.NewPusher(jobName, cfg.PromPushGatewayAddr)pusher.PushPeriodicMetrics(logger.With(), 30*time.Second)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Era melhor do que nada, mas apareceram problemas de corretude. A cada push havia colisões de métricas entre os jobs. Isso fazia com que o valor final fosse sobrescrito no Prometheus, deixando os counters subindo e descendo (um problema de corretude).
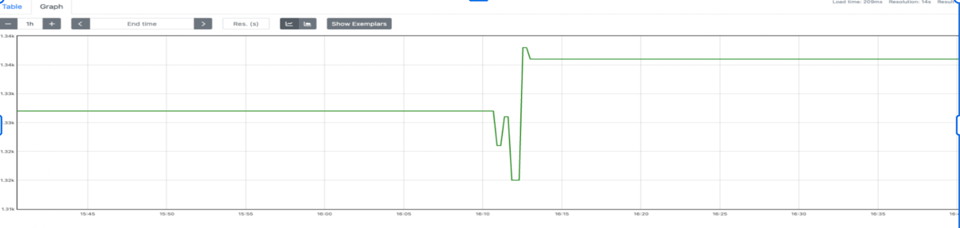
Decidimos adicionar o pod_name para evitar essas colisões e garantir a corretude. O POD_NAME viria da Downward API do Kubernetes.
podName, exists := os.LookupEnv("POD_NAME")if !exists { podName = cfg.Conf.SvcID}pusher := metric.NewPusher(podName, cfg.PromPushGatewayAddr)Depois de conferir, os dados pareciam corretos. Só que não dava para montar dashboards nem alertas. Resumindo: o increase não funcionava. Para o increase funcionar, é preciso calcular o delta entre T1 e T2. Como os dados só chegavam em T2, se a métrica estivesse ausente no primeiro scrape (quando o primeiro push ainda não aconteceu), não havia delta e nem increase. Também notamos que o Prometheus passou a consumir muita memória. Jobs de curta duração são, bem, curtos, e temos vários deles, cada um com seu pod_name único, acumulando cardinalidade rapidinho.
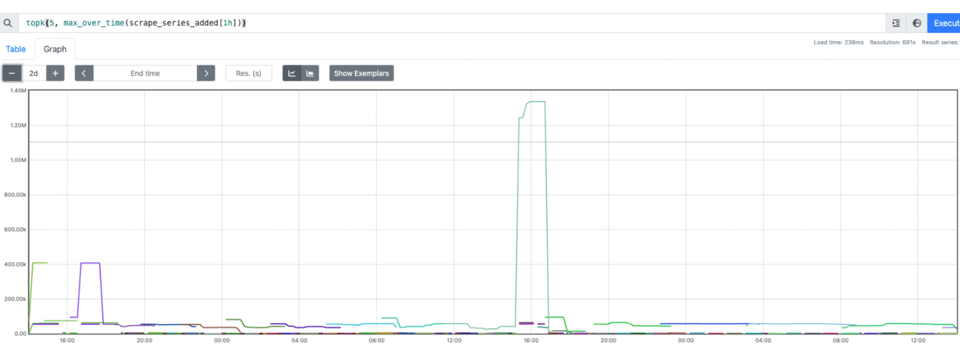
Então tínhamos dados corretos e um pacote compartilhado fácil de usar. Ainda precisávamos resolver dashboards, alertas, melhorar a performance e reduzir o custo.
Melhoria
Começamos pelo óbvio: usar as recording rules nativas do Prometheus. Adicionamos o seguinte:
record: metric_name:aggrexp: sum(metric_name) without (job)
O problema é que o increase continuava sem funcionar. Para métricas com push frequente até estava ok, mas para jobs de curta duração com push pouco frequente faltava o importante valor inicial 0.
Um problema maior: a memória do Prometheus seguia crescendo. Além da memória, recalculávamos e armazenávamos essa expressão a cada intervalo N, gerando também alto uso de CPU.
Refinamento final
O que queríamos era o seguinte: antes de o Prometheus armazenar qualquer coisa, fazer a agregação primeiro e só então guardar o resultado. Um bônus seria enviar um 0 antes do valor real aparecer. Outro bônus seria poder ter outras regras de agregação, com o mínimo de mudanças em dashboards e alertas e fácil de ser adotado pelos times de engenharia. Algo assim, mas falando Prometheus:
SELECT *, SUM(value)FROM METRICSWHERE METRIC_NAME LIKE 'COUNT'GROUP BY * WITHOUT JOB;Entra em cena a streaming aggregation do vmagent. O vmagenthttps://docs.victoriametrics.com/victoriametrics/vmagent/ é um agente de coleta de métricas leve e de alta performance, criado pela VictoriaMetrics para fazer scrape, processar e ingerir dados de diversas fontes em sistemas de monitoramento. É exatamente isso que ele faz: atua como push gateway e envia métricas agregadas para o Prometheus.
Exemplo de regra para as métricas de count que enviamos:
- match: '{__name__=~".+_count"}' interval: 2m outputs: ["total"] without: ["pod_name"] staleness_interval: 15m keep_metric_names: true flush_on_shutdown: trueE os gráficos passaram a aparecer exatamente como a gente esperava.
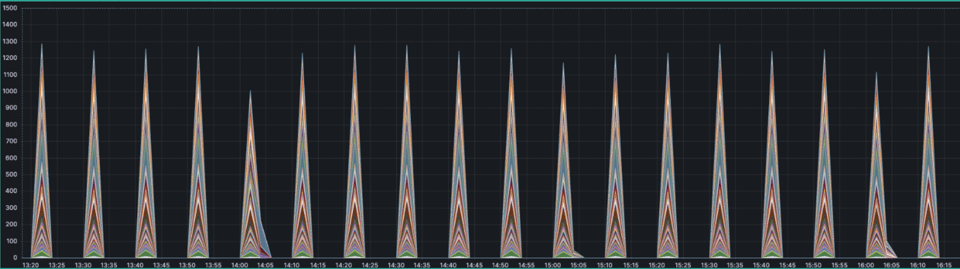
Solução final
+-----------------------------+| K8s Jobs || (shared metrics package) |+-------------+---------------+ | | push metrics v+-----------------------------+| Push Endpoint || (e.g. Pushgateway) |+-------------+---------------+ | | metrics flow v+-----------------------------+| vmagent || (streaming aggregation) || - reduce cardinality || - aggregate counters |+-------------+---------------+ | | push v+-----------------------------+| Prometheus || (stores aggregated data) |+-----------------------------+Resumindo o fluxo: temos um pacote compartilhado que envia métricas periodicamente para o vmagent. Ele inclui o pod_name como label. Ao final da execução, faz um push final.
Os dados chegam ao vmagent, que mantém o estado da agregação. Ele soma os counters recebidos por nome de métrica. Uma vez por intervalo, envia o resultado para o Prometheus.
Agora atendemos a todos os nossos requisitos.
Problemas
Pré-agregar os dados significa que perdemos os dados brutos. Se alguém quiser buscar métricas de um pod específico, não vai conseguir.
O vmagent armazena estado. Se ele resetar, começamos do 0. Isso é aceitável para dashboards e alertas, e dá para usar um sum() comum para cobrir as lacunas. Porém, durante uma indisponibilidade do vmagent, vamos perder dados.
Além disso, estamos rodando um componente a mais que precisamos configurar e gerenciar.
Monitorar workloads de curta duração em escala exige mais do que o tooling padrão. Exige escolhas arquiteturais deliberadas. Se o seu time enfrenta desafios parecidos de observabilidade no Kubernetes, nossos engenheiros podem ajudar a desenhar e implementar soluções sob medida para a sua stack. Saiba mais em https://www.doit.com/solutions/forward-deployed-engineering.