Kurzlebige Kubernetes Jobs at Scale überwachen
 Wie wir Metrikverluste, Cardinality-Explosionen und fehlerhafte Dashboards für ephemere Workloads mit vmagent Streaming Aggregation in den Griff bekommen haben
Wie wir Metrikverluste, Cardinality-Explosionen und fehlerhafte Dashboards für ephemere Workloads mit vmagent Streaming Aggregation in den Griff bekommen haben
Einleitung
Sie steigen in Kubernetes ein und deployen ein paar Anwendungen. Sie exponieren Metriken, setzen Prometheus ein – und alles läuft rund.
Dann kommen ein paar Jobs dazu, die regelmäßig laufen sollen. Gleiches Prometheus-Paket, Metriken werden exponiert. Plötzlich schrillt der Alert: Prometheus ist OOM. Sie schauen in Ihre Dashboards und sehen tatsächlich jede Menge neuer Time Series, alle eindeutig über die job_id. Bei genauerem Hinsehen wirken die Dashboards für kurzlebige Jobs zudem fehlerhaft.
Eine Geschichte, die früher oder später jeden trifft.
In diesem Artikel zeigen wir, wie wir das Problem angegangen sind.
Hintergrund
Kurzlebige Jobs sind in Kubernetes weit verbreitet:
- Batch-Workloads
- CronJobs
- Event-getriebene Pipelines
- Kostenoptimierte Compute-Aufgaben
Sie sind effizient und skalierbar, stellen aber Monitoring-Systeme, die auf langlebige Services ausgelegt sind, vor Herausforderungen.
Es gibt zwei Klassen von Monitoring-Systemen: Pull-basiert und Push-basiert. Bei Push-basierten Systemen senden Sie Daten, wann immer Sie möchten. Pull-basierte Systeme scrapen Targets in einem festen Zeitintervall.
Prometheus (und andere) arbeitet standardmäßig Pull-basiert. Es führt ein Inventar von Targets, scraped Metriken im Intervall T im Prometheus-Format von einem definierten Endpoint und legt sie in einer lokalen Datenbank ab.
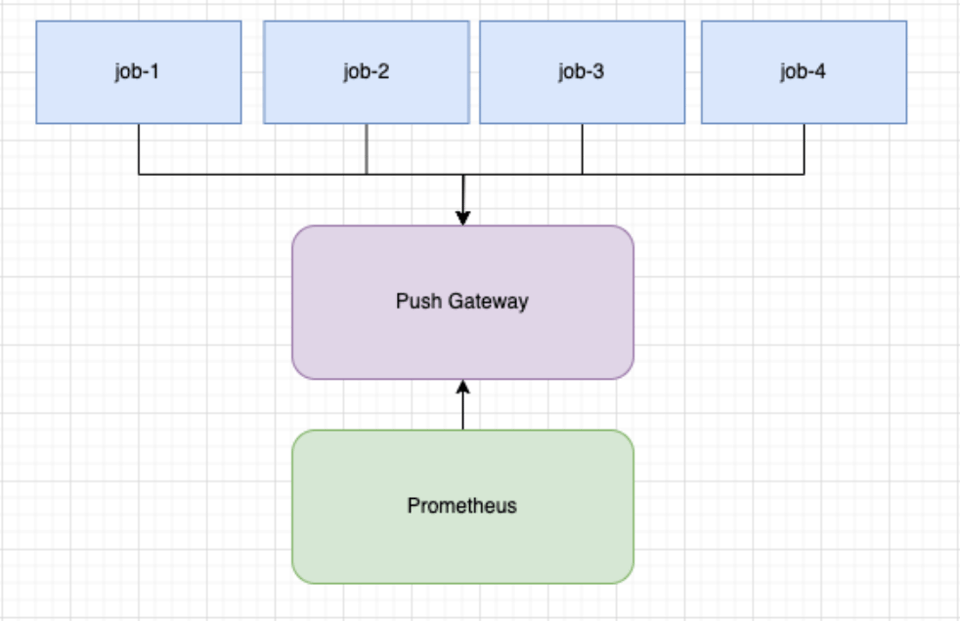
Für kurzlebige Jobs scheitert dieser Ansatz am Intervall: Stirbt ein Job zwischen T1 und T2, werden seine Metriken nicht gescraped. Ein weiteres häufiges Problem ist die Cardinality. Jeder Job bringt entweder einen pod_name oder einen anderen eindeutigen Identifier mit, wodurch jede Time Series aus Sicht von Prometheus einzigartig wird.
Wir haben viele solcher Jobs und sie sind geschäftskritisch. Metrikverluste sind inakzeptabel, weil wir SLOs falsch berechnen, False-Negative-Alerts bekommen und wichtige Entscheidungsgrundlagen verlieren können. Hinzu kommt: Die Cardinality der Pod-Namen dieser Jobs ist erheblich. Prometheus wurde zum Speicherfresser in unserem Cluster, und alle Queries auf diesen Metriken liefen langsam und verbrauchten viele Ressourcen.
Problemstellung
- Alle Metriken aus kurzlebigen Jobs erfassen
- Korrektheit der Metriken sicherstellen
- Kosten und Performance im Rahmen halten
- Dashboarding und Alerting darauf aufbauen können
- Engineer-freundlich gestalten (gemeinsames Paket, leicht wiederverwendbar)
Wir starten mit den Pflicht-Punkten und kümmern uns anschließend um die UX. Also zuerst Erfassung und Korrektheit, danach Kosten, Performance und gemeinsame Pakete.
Ausgangspunkt
Der naive Ansatz:
- Prometheus Pushgateway nutzen
- Metriken in der Default-Registry registrieren
- Metriken bei Job-Abschluss pushen
pusher := metric.NewPusher("reports", cfg.PromPushGatewayAddr)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Als kleine Verbesserung lässt sich ein periodischer Pusher ergänzen – eine Goroutine, die Metriken regelmäßig ins Push Gateway schiebt.
pusher := metric.NewPusher(jobName, cfg.PromPushGatewayAddr)pusher.PushPeriodicMetrics(logger.With(), 30*time.Second)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Dieser Ansatz war besser als nichts, aber wir stießen auf Probleme bei der Korrektheit. Bei jedem Push gab es Metrik-Kollisionen über alle Jobs hinweg. Dadurch wurde der finale Wert in Prometheus überschrieben, sodass Counter rauf und runter sprangen (ein Korrektheitsproblem).
Wir entschieden uns, pod_name zu ergänzen, um solche Kollisionen zu vermeiden und die Korrektheit sicherzustellen. POD_NAME kommt aus der Kubernetes Downward API.
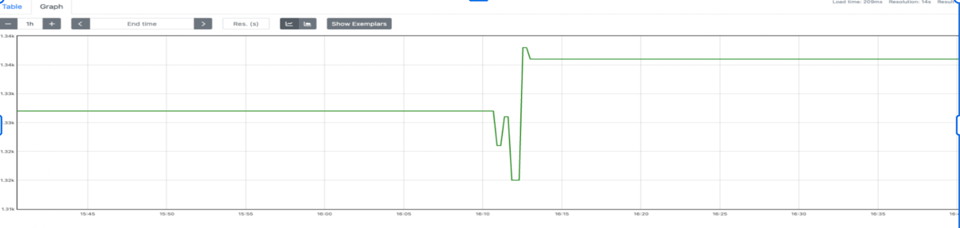
podName, exists := os.LookupEnv("POD_NAME")if !exists { podName = cfg.Conf.SvcID}pusher := metric.NewPusher(podName, cfg.PromPushGatewayAddr)Nach der Prüfung sahen unsere Daten korrekt aus. Allerdings konnten wir weder Dashboards noch Alerts bauen. Kurz gesagt: increase funktionierte nicht. Damit increase arbeiten kann, brauchen wir das Delta zwischen T1 und T2. Daten kamen erst bei T2 an – fehlte die Metrik beim ersten Scrape (der erste Push hat noch nicht stattgefunden), gab es kein Delta und damit kein Increase. Zusätzlich fiel auf, dass Prometheus immer mehr Speicher verbrauchte. Kurzlebige Jobs sind eben kurzlebig, wir haben viele davon, und jeder bringt seinen eigenen eindeutigen Pod-Namen mit – die Cardinality schießt in die Höhe.
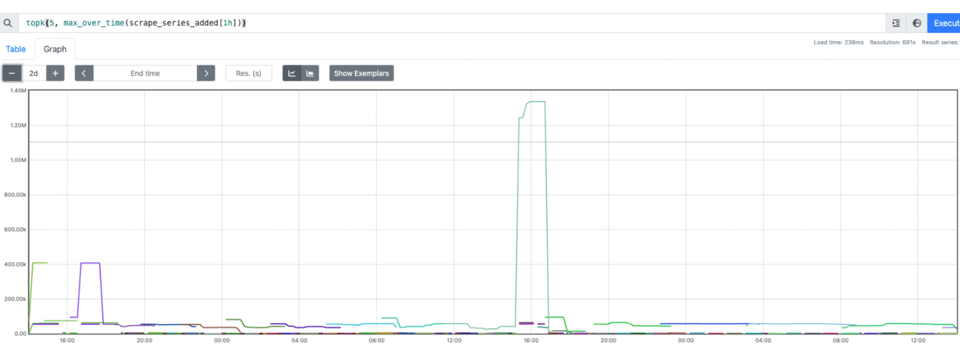
Wir hatten also korrekte Daten und ein gemeinsames Paket, das einfach zu nutzen ist. Offen blieben Dashboards, Alerts, bessere Performance und niedrigere Kosten.
Verbesserung
Wir begannen mit dem Naheliegenden: den eingebauten Recording Rules in Prometheus. Wir ergänzten Folgendes:
record: metric_name:aggrexp: sum(metric_name) without (job)
Das Problem: increase funktionierte weiterhin nicht. Für häufig gepushte Metriken war es in Ordnung, aber für seltene, kurzlebige Jobs fehlte der wichtige initiale 0-Wert.
Das größere Problem: Der Speicherverbrauch von Prometheus stieg weiter. Obendrein wurde dieser Ausdruck einmal pro N-Intervall neu berechnet und gespeichert, was auch die CPU spürbar belastete.
Finale Optimierung
Unser Ziel: Bevor Prometheus etwas speichert, soll zuerst aggregiert und nur das Ergebnis abgelegt werden. Ein Bonus wäre, eine 0 zu pushen, bevor der tatsächliche Wert erscheint. Ein weiterer Bonus: zusätzliche Aggregationsregeln, mit minimalen Änderungen an Dashboards und Alerts und leicht für Engineering-Teams zu übernehmen. Also in etwa so, nur in Prometheus-Sprache:
SELECT *, SUM(value)FROM METRICSWHERE METRIC_NAME LIKE 'COUNT'GROUP BY * WITHOUT JOB;Auftritt vmagent Streaming Aggregation. vmagenthttps://docs.victoriametrics.com/victoriametrics/vmagent/ ist ein leichtgewichtiger, performanter Agent für die Metrikerfassung von VictoriaMetrics, der Daten aus verschiedenen Quellen scraped, verarbeitet und in Monitoring-Systeme einspeist. Genau das tut er: Er fungiert als Push Gateway und schiebt aggregierte Metriken nach Prometheus.
Beispielregel für Count-Metriken, die wir pushen:
- match: '{__name__=~".+_count"}' interval: 2m outputs: ["total"] without: ["pod_name"] staleness_interval: 15m keep_metric_names: true flush_on_shutdown: trueUnd unsere Graphen sahen genau so aus, wie wir es erwartet hatten.
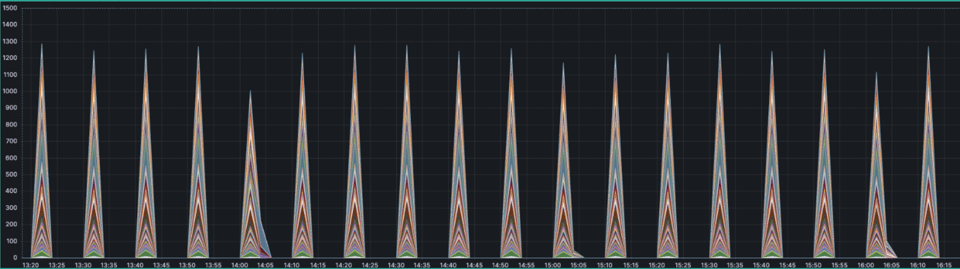
Finale Lösung
+-----------------------------+| K8s Jobs || (shared metrics package) |+-------------+---------------+ | | push metrics v+-----------------------------+| Push Endpoint || (e.g. Pushgateway) |+-------------+---------------+ | | metrics flow v+-----------------------------+| vmagent || (streaming aggregation) || - reduce cardinality || - aggregate counters |+-------------+---------------+ | | push v+-----------------------------+| Prometheus || (stores aggregated data) |+-----------------------------+Der Ablauf im Überblick: Ein gemeinsames Paket pusht periodisch Metriken in vmagent und ergänzt pod_name als Label. Am Ende der Ausführung erfolgt ein finaler Push.
Die Daten landen in vmagent, der den Aggregationszustand hält. Er summiert eingehende Counter pro Metrik-Namen und pusht das Ergebnis einmal pro Intervall nach Prometheus.
Damit haben wir alle Anforderungen erfüllt.
Kompromisse
Die Vor-Aggregation bedeutet, dass wir Rohdaten verlieren. Wer Metriken für einen bestimmten Pod abrufen möchte, hat Pech.
vmagent hält Zustand. Bei einem Reset starten wir wieder bei 0. Für Dashboards und Alerts ist das vertretbar, und mit einem regulären sum() lassen sich Lücken überbrücken. Während einer Ausfallzeit von vmagent gehen jedoch Daten verloren.
Hinzu kommt: Wir betreiben eine zusätzliche Komponente, die konfiguriert und gewartet werden will.
Das Monitoring kurzlebiger Workloads at Scale verlangt mehr als Standard-Tooling – es verlangt bewusste Architekturentscheidungen. Wenn Ihr Team vor ähnlichen Kubernetes-Observability-Herausforderungen steht, helfen Ihnen unsere Engineers, passende Lösungen für Ihren Stack zu entwerfen und umzusetzen. Mehr dazu unter https://www.doit.com/solutions/forward-deployed-engineering.