Monitoreo de Kubernetes Jobs efímeros a gran escala
 Cómo resolvimos la pérdida de métricas, la explosión de cardinalidad y los dashboards rotos en workloads efímeros usando la agregación en streaming de vmagent
Cómo resolvimos la pérdida de métricas, la explosión de cardinalidad y los dashboards rotos en workloads efímeros usando la agregación en streaming de vmagent
Introducción
Empiezas a usar Kubernetes y despliegas algunas aplicaciones por aquí y por allá. Comienzas a exponer métricas con Prometheus y todo marcha sobre ruedas.
Tienes algunos jobs que necesitas ejecutar. Mismo paquete de Prometheus, mismas métricas expuestas. De repente, suena la alerta: Prometheus se quedó sin memoria (OOM). Revisas tus dashboards y, en efecto, hay un montón de series temporales nuevas, todas únicas por job_id. Vuelves a revisar los dashboards y notas que se ven incorrectos para los jobs efímeros.
Esta es una historia con la que todos se topan tarde o temprano.
En este artículo compartimos cómo le encontramos la vuelta.
Contexto
Los jobs efímeros se usan mucho en Kubernetes:
- Batch workloads
- CronJobs
- Pipelines orientados a eventos
- Cómputo optimizado en costo
Son eficientes y escalables, pero plantean retos para los sistemas de monitoreo pensados para servicios de larga duración.
Existen dos tipos de sistemas de monitoreo: pull-based y push-based. Con los push-based, envías datos cuando quieres. Los pull-based hacen scrape de los targets en un intervalo definido.
Prometheus (y otros) son pull-based por defecto. Mantiene un inventario de targets, hace scrape de las métricas cada intervalo T en formato Prometheus desde un endpoint determinado y las guarda en una base de datos local.
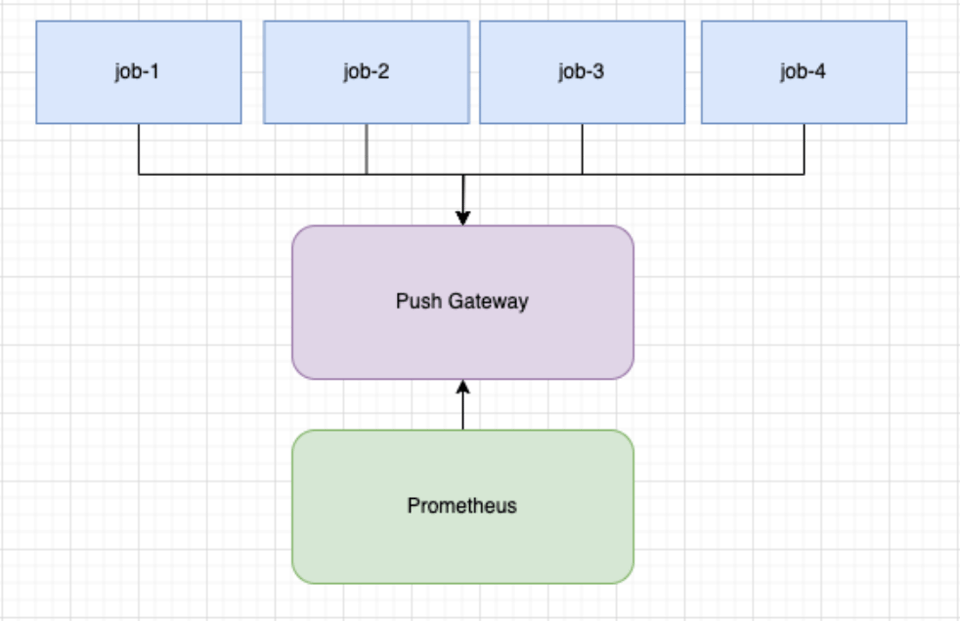
Para los jobs efímeros, este enfoque se queda corto en el intervalo: si un job muere entre T1 y T2, sus métricas nunca se recolectan. Otro problema habitual es la cardinalidad. Cada job tendrá un pod_name u otro identificador único, lo que hace que cada serie temporal sea única a los ojos de Prometheus.
Tenemos muchos jobs así y son mission critical. Perder métricas no es una opción, porque podríamos calcular mal los SLOs, tener alertas con falsos negativos y quedarnos sin datos clave para tomar decisiones. Sumado a eso, la cardinalidad de los pod names en estos jobs es considerable. Prometheus se convirtió en un devorador de memoria en nuestro cluster, y cualquier consulta sobre esas métricas se volvía lenta y consumía muchísimos recursos.
Planteamiento del problema
- Recolectar todas las métricas de los jobs efímeros
- Garantizar la exactitud de las métricas
- Mantener el costo y el rendimiento bajo control
- Soportar tanto dashboarding como alerting encima de eso
- Que sea cómodo para los engineers (paquete compartido, fácil de reutilizar)
Arrancamos por los "imprescindibles" y después afinamos la UX. Es decir, primero recolección y exactitud, luego costo, rendimiento y paquetes compartidos.
Punto de partida
Enfoque básico:
- Usar Prometheus Pushgateway
- Registrar las métricas con el registry por defecto
- Hacer push de las métricas al terminar el job
pusher := metric.NewPusher("reports", cfg.PromPushGatewayAddr)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Como pequeña mejora, podemos sumar un pusher periódico: una goroutine que envía métricas al push gateway cada cierto tiempo.
pusher := metric.NewPusher(jobName, cfg.PromPushGatewayAddr)pusher.PushPeriodicMetrics(logger.With(), 30*time.Second)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()Este enfoque era mejor que nada, pero detectamos problemas de exactitud. En cada push había colisiones de métricas entre los distintos jobs, lo que sobrescribía el valor final en Prometheus y hacía que los counters subieran y bajaran (un problema de exactitud).
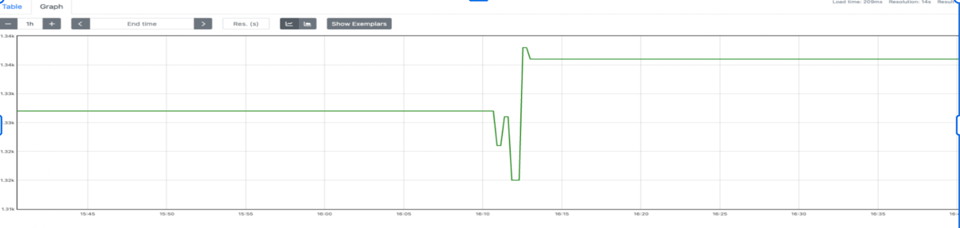
Decidimos agregar pod_name para evitar esas colisiones y garantizar la exactitud. POD_NAME vendría de la Kubernetes Downward API.
podName, exists := os.LookupEnv("POD_NAME")if !exists { podName = cfg.Conf.SvcID}pusher := metric.NewPusher(podName, cfg.PromPushGatewayAddr)Al revisar los datos, se veían correctos. Sin embargo, no podíamos armar dashboards ni alertas. Dicho simple: increase no funcionaba. Para que increase funcione hay que calcular el delta entre T1 y T2. Los datos solo llegaban en T2, así que si la métrica no estaba presente en el primer scrape (el primer push no ocurre), no había delta ni increase. También notamos que Prometheus empezó a consumir muchísima memoria. Los jobs efímeros son efímeros, y tenemos un montón, cada uno con su pod name único, lo que dispara la cardinalidad rápidamente.
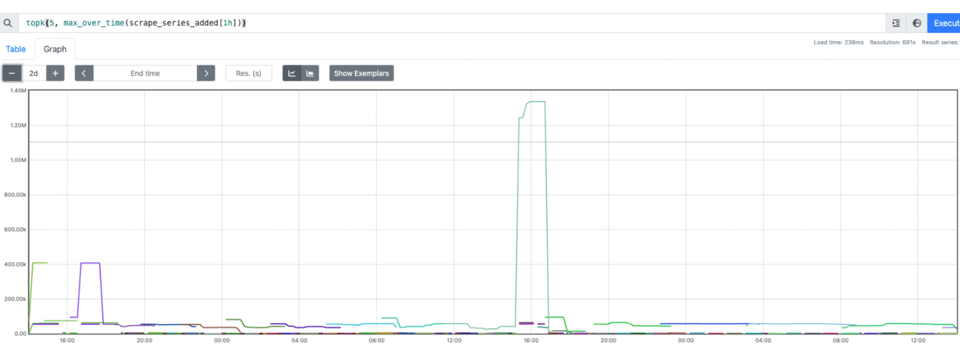
Entonces, ya teníamos datos correctos y un paquete compartido fácil de usar. Nos faltaba cubrir la creación de dashboards, las alertas, mejorar el rendimiento y reducir el costo.
Mejora
Empezamos por lo obvio: usar las recording rules integradas de Prometheus. Añadimos lo siguiente:
record: metric_name:aggrexp: sum(metric_name) without (job)
El problema con este enfoque era que increase seguía sin funcionar. Para métricas que se enviaban con frecuencia estaba bien, pero para los jobs efímeros poco frecuentes nos faltaba ese valor inicial de 0, tan importante.
Un problema mayor era que la memoria en Prometheus seguía creciendo. Además, recalculábamos y guardábamos esa expresión una vez cada N intervalos, lo que también disparaba el uso de CPU.
Refinamiento final
Lo que queríamos era esto: antes de que Prometheus almacene cualquier cosa, hacer primero la agregación y solo entonces guardar el resultado. Un plus sería enviar un 0 antes de que aparezca el valor real. Y otro plus, poder definir otras reglas de agregación con cambios mínimos en dashboards y alertas, y que fuera fácil de adoptar por los equipos de engineering. Algo así, pero en lenguaje Prometheus:
SELECT *, SUM(value)FROM METRICSWHERE METRIC_NAME LIKE 'COUNT'GROUP BY * WITHOUT JOB;Aquí entra la agregación en streaming de vmagent. vmagenthttps://docs.victoriametrics.com/victoriametrics/vmagent/ es un agente de recolección de métricas ligero y de alto rendimiento, diseñado por VictoriaMetrics para hacer scrape, procesar e ingerir datos desde distintas fuentes hacia sistemas de monitoreo. Hace exactamente eso: actúa como push gateway y envía las métricas agregadas a Prometheus.
Regla de ejemplo para las métricas de count que enviamos:
- match: '{__name__=~".+_count"}' interval: 2m outputs: ["total"] without: ["pod_name"] staleness_interval: 15m keep_metric_names: true flush_on_shutdown: trueY nuestras gráficas empezaron a verse justo como queríamos.
Solución final
+-----------------------------+| K8s Jobs || (paquete de métricas || compartido) |+-------------+---------------+ | | push de métricas v+-----------------------------+| Push Endpoint || (ej. Pushgateway) |+-------------+---------------+ | | flujo de métricas v+-----------------------------+| vmagent || (agregación en streaming) || - reduce cardinalidad || - agrega counters |+-------------+---------------+ | | push v+-----------------------------+| Prometheus || (almacena datos agregados)|+-----------------------------+Para resumir el flujo: tenemos un paquete compartido que envía métricas a vmagent de forma periódica e incluye pod_name como label. Al terminar la ejecución hace un push final.
Los datos llegan a vmagent, que mantiene el estado de la agregación. Suma los counters entrantes por nombre de métrica y, una vez por intervalo, envía el resultado a Prometheus.
Así cumplimos con todos nuestros requisitos.
Problemas
Pre-agregar los datos implica perder los datos crudos. Si alguien quiere consultar métricas de un pod específico, no se puede.
vmagent almacena estado. Si se reinicia, arrancamos desde 0. Eso funciona para dashboards y alertas, y puedes usar un sum() normal para tapar los huecos. Sin embargo, si vmagent no está disponible, vamos a perder datos.
Además, estamos corriendo un componente adicional que hay que configurar y administrar.
Monitorear workloads efímeros a gran escala requiere más que las herramientas por defecto: requiere decisiones de arquitectura intencionales. Si tu equipo está enfrentando retos similares de observabilidad en Kubernetes, nuestros engineers pueden ayudarte a diseñar e implementar soluciones que encajen con tu stack. Conoce más en https://www.doit.com/solutions/forward-deployed-engineering.