大規模環境での短命Kubernetesジョブ監視
 vmagentのストリーミング集約で、短命workloadsのメトリクス欠損・カーディナリティ爆発・崩れたダッシュボードを解決した方法
vmagentのストリーミング集約で、短命workloadsのメトリクス欠損・カーディナリティ爆発・崩れたダッシュボードを解決した方法
はじめに
Kubernetesを使い始め、アプリケーションをいくつかデプロイする。メトリクスを公開し、Prometheusを導入する。順風満帆です。
そこに、実行が必要なジョブがいくつか出てきます。同じPrometheusパッケージを使ってメトリクスを公開する。すると突然、アラートが鳴り出します。PrometheusがOOM。ダッシュボードを見ると、job_idごとに固有の時系列が大量に増えています。さらに、短命ジョブのダッシュボードの値もどうやら正しくないようです。
これは、誰しもが遅かれ早かれぶつかる話です。
本記事では、私たちがこの課題にどう向き合ったかを共有します。
背景
短命ジョブはKubernetesで広く使われています。
- バッチworkloads
- CronJob
- イベント駆動型パイプライン
- コスト最適化されたコンピュート
効率的でスケーラブルですが、長期稼働サービスを前提に設計された監視システムにとっては悩みの種となります。
監視システムにはプル型とプッシュ型の2種類があります。プッシュ型は任意のタイミングでデータを送信できます。プル型は一定間隔でターゲットをスクレイピングします。
Prometheus(および同種のツール)はデフォルトでプル型です。ターゲットの一覧を保持し、指定エンドポイントから一定間隔TごとにPrometheus形式でメトリクスをスクレイピングし、ローカルデータベースに保存します。
短命ジョブでは、この「間隔」がネックになります。ジョブがT1とT2の間で終了すると、メトリクスはスクレイピングされません。もう一つのよくある問題がカーディナリティです。各ジョブにはpod_nameなど何らかの一意な識別子が付くため、Prometheusから見るとすべての時系列が別物になってしまいます。
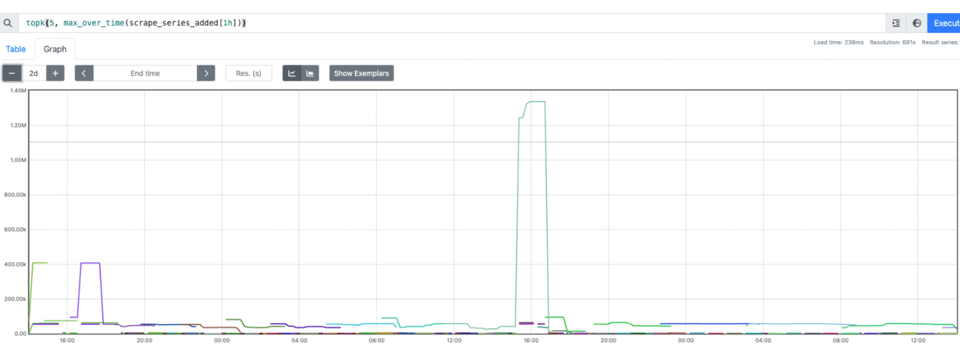
私たちは、こうしたジョブを多数、しかもミッションクリティカルな用途で動かしています。メトリクスの欠損は許容できません。SLOの計算を誤ったり、誤検知のアラートが発生したり、意思決定に必要な重要データを見落とすおそれがあるからです。加えて、これらのジョブのpod名のカーディナリティは膨大で、Prometheusはクラスター内でメモリを食い潰すようになり、これらのメトリクスを使うクエリは軒並み遅く、リソースを大量に消費しました。
課題の整理
- 短命ジョブからすべてのメトリクスを収集すること
- メトリクスの正確性を担保すること
- コストとパフォーマンスを妥当な水準に保つこと
- ダッシュボードとアラートの両方で活用できること
- Engineersが扱いやすいこと(共有パッケージとして再利用しやすい)
まずは「必須」項目から着手し、その後でUXを磨きます。つまり、収集と正確性を最優先にし、続いてコスト、パフォーマンス、共有パッケージへと進めます。
出発点
まずは素朴なアプローチです。
- Prometheus Pushgatewayを使う
- デフォルトレジストリにメトリクスを登録する
- ジョブ完了時にメトリクスをプッシュする
pusher := metric.NewPusher("reports", cfg.PromPushGatewayAddr)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()小さな改善として、定期的なプッシュ処理も追加できます。これは、push gatewayへ定期的にメトリクスをプッシュするgoroutineです。
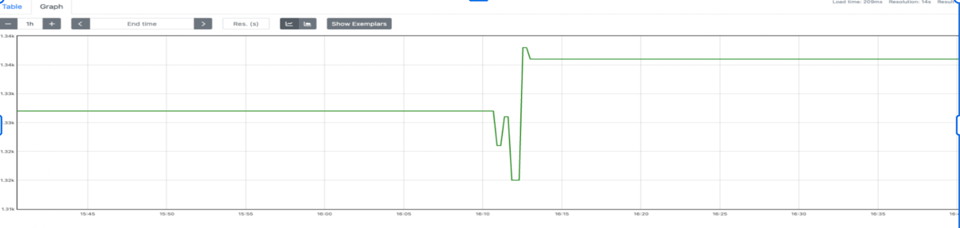
pusher := metric.NewPusher(jobName, cfg.PromPushGatewayAddr)pusher.PushPeriodicMetrics(logger.With(), 30*time.Second)defer func() { if err := pusher.PushMetrics(); err != nil { logger.Errorf("could not push metrics: %s", err) }}()この方法は何もしないよりはマシでしたが、正確性に問題が出ました。プッシュのたびに全ジョブ間でメトリクスが衝突し、Prometheus上で最終値が上書きされ、カウンターが上下に揺れる事態になったのです(正確性の問題)。
そこで衝突を回避し正確性を担保するため、pod_nameを付与することにしました。POD_NAMEはKubernetes Downward APIから取得します。
podName, exists := os.LookupEnv("POD_NAME")if !exists { podName = cfg.Conf.SvcID}pusher := metric.NewPusher(podName, cfg.PromPushGatewayAddr)データを確認すると、たしかに値は正しく見えました。ところが、ダッシュボードもアラートも組めません。端的に言えば、increaseが効かなかったのです。increaseを成立させるにはT1とT2の差分計算が必要ですが、データはT2にしか現れません。最初のスクレイプ時点でメトリクスが存在しなければ(初回プッシュが発生していなければ)、差分も増分も計算できません。さらに、Prometheusのメモリ消費が増え始めていることにも気づきました。短命ジョブはまさに短命で、それが大量に存在し、しかもそれぞれが固有のpod名を持つため、カーディナリティが一気に膨れ上がります。
こうして、正確なデータと使いやすい共有パッケージは手に入りました。残るは、ダッシュボードとアラートの構築、パフォーマンス改善、コスト削減です。
改善
まずは王道として、Prometheus組み込みのrecording rulesを使いました。次のように追加します。
record: metric_name:aggrexp: sum(metric_name) without (job)
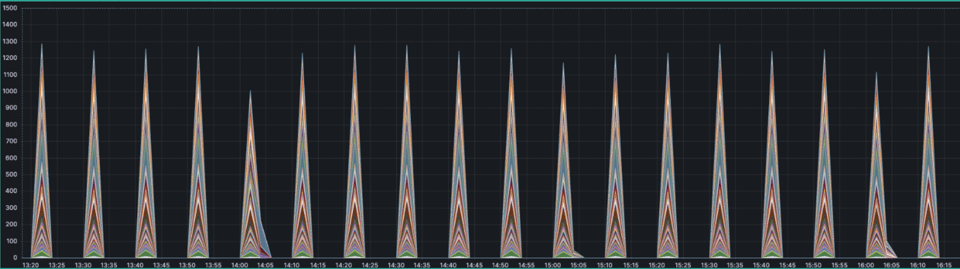
この方法の問題点は、依然としてincreaseが機能しないことでした。頻繁にプッシュされるメトリクスでは問題なくても、頻度の低い短命ジョブでは、肝心な初期値0が欠けてしまうのです。
さらに大きな問題は、Prometheusのメモリ消費が増え続けたこと。加えて、この式をN間隔ごとに再計算して保存するため、CPU使用率も上昇しました。
最終的な仕上げ
私たちが求めていたのは次のような姿です。Prometheusが値を保存する前に集約を済ませ、その結果だけを保存する。さらに、実際の値が出現する前に0をプッシュできれば理想的。加えて、他の集約ルールにも対応でき、ダッシュボードやアラートへの変更は最小限、エンジニアリングチームが容易に採用できれば言うことなしです。Prometheus風に表現すると、こんなイメージです。
SELECT *, SUM(value)FROM METRICSWHERE METRIC_NAME LIKE 'COUNT'GROUP BY * WITHOUT JOB;ここで登場するのがvmagentのストリーミング集約です。vmagenthttps://docs.victoriametrics.com/victoriametrics/vmagent/ はVictoriaMetricsが開発した軽量・高性能なメトリクス収集エージェントで、さまざまなソースからデータをスクレイピング・処理し、監視システムに取り込みます。まさに私たちが望んだ動きをしてくれます。push gatewayとして機能し、集約済みメトリクスをPrometheusへプッシュします。
プッシュするcount系メトリクス向けのルール例です。
- match: '{__name__=~".+_count"}' interval: 2m outputs: ["total"] without: ["pod_name"] staleness_interval: 15m keep_metric_names: true flush_on_shutdown: trueこうして、グラフは期待どおりの形に整いました。
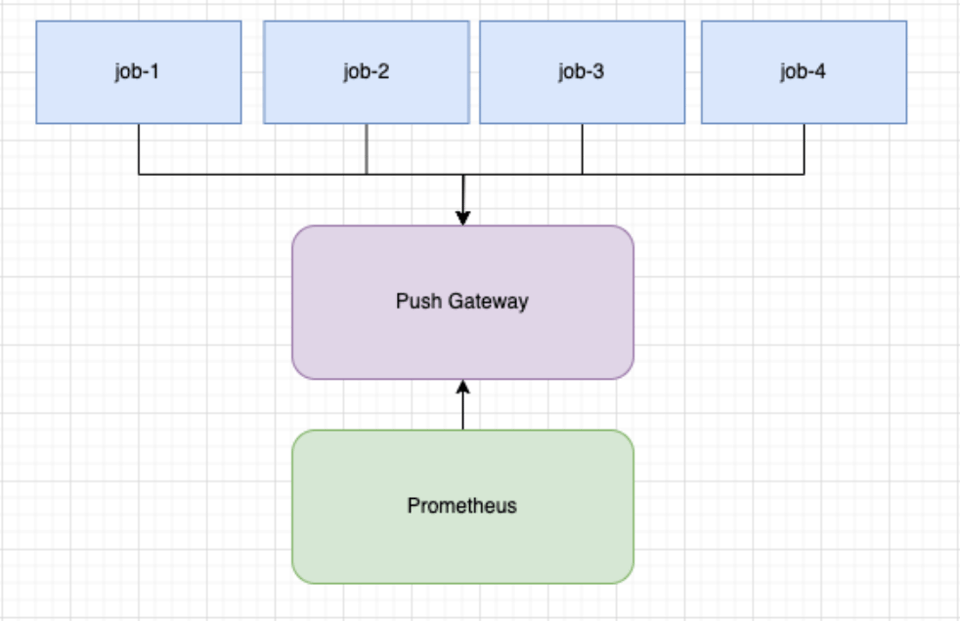
最終的なソリューション
+-----------------------------+| K8s Jobs || (shared metrics package) |+-------------+---------------+ | | push metrics v+-----------------------------+| Push Endpoint || (e.g. Pushgateway) |+-------------+---------------+ | | metrics flow v+-----------------------------+| vmagent || (streaming aggregation) || - reduce cardinality || - aggregate counters |+-------------+---------------+ | | push v+-----------------------------+| Prometheus || (stores aggregated data) |+-----------------------------+フローをおさらいします。共有パッケージが定期的にvmagentへメトリクスをプッシュし、ラベルとしてpod_nameを付与します。処理終了時には最終プッシュを実行します。
vmagentはデータを受け取り、集約状態を保持します。届いたカウンターをメトリクス名ごとに合算し、間隔ごとに結果をPrometheusへプッシュします。
これで、当初の要件をすべて満たすことができました。
残る課題
事前集約するということは、生データを失うということでもあります。特定のpodのメトリクスを取り出したい、というニーズには応えられません。
vmagentは状態を保持します。リセットされれば0からやり直しです。これはダッシュボードやアラートには大きな問題はなく、通常のsum()でギャップを補えます。ただし、vmagentが停止している間はデータが失われます。
さらに、設定・運用が必要なコンポーネントが一つ増えることにもなります。
大規模な短命workloadsの監視は、標準ツールだけでは賄いきれません。意図的なアーキテクチャ設計が欠かせないのです。同様のKubernetes可観測性の課題に取り組むチームには、DoiTのEngineersがスタックに合ったソリューションの設計・実装をご支援します。詳しくは https://www.doit.com/solutions/forward-deployed-engineering をご覧ください。