
Face à un incident critique sur votre infrastructure cloud, chaque seconde compte. Il vous faut une aide rapide et précise. Mais même hors urgence, pas question de perdre un temps précieux à remplir de longs formulaires : vous voulez décrire votre problème et que tout le reste soit pris en charge.
Le défi : un support assisté par IA plus réactif et plus interactif
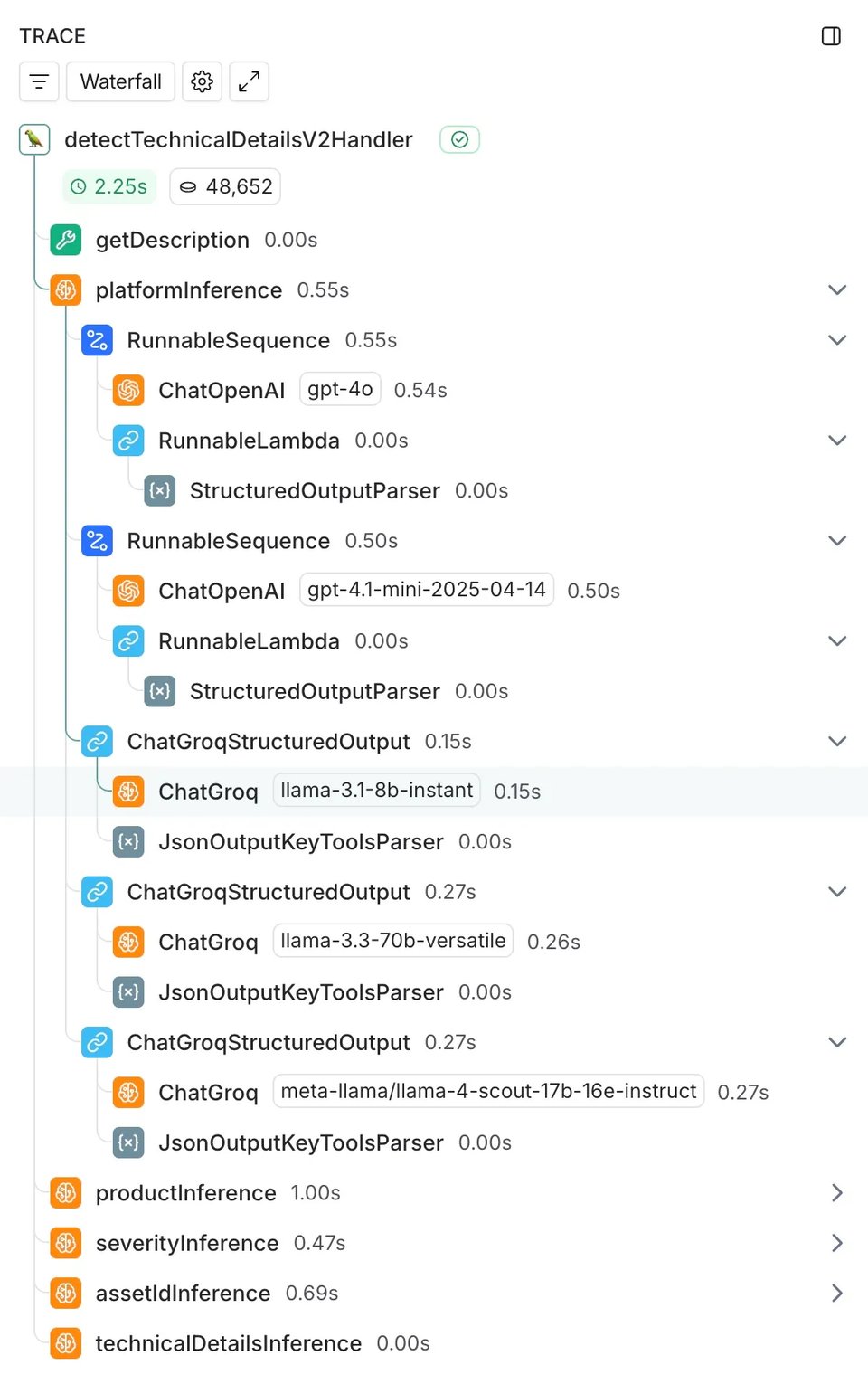
Chez DoiT, Ava répond à vos questions FinOps et cloud. Mais il arrive que vous préfériez en discuter avec un expert humain. C'est là qu'intervient notre système Case IQ : il aide les clients à fournir les bons détails techniques dès l'ouverture d'un ticket, pour que nos Customer Reliability Engineers (CRE) disposent de tout ce qu'il leur faut afin de résoudre rapidement les problèmes.
L'idée est née de notre hackathon de l'été 2024 et reposait sur les API d'OpenAI. Nous avons toutefois décidé d'aller plus loin, en travaillant sur la latence des recommandations envoyées au client pour rendre le système plus fluide et plus interactif.
L'expérience : cinq modèles évalués sur la latence, le coût et la performance
Pour cela, nous avons mené une expérience approfondie sur deux semaines, en comparant notre modèle actuel (le GPT-4o d'OpenAI) à quatre alternatives :
- GPT-4.1 mini (le modèle plus récent et plus rapide d'OpenAI)
- Llama 3.1 8B (modèle compact et ultra-rapide sur le matériel spécialisé de Groq)
- Llama 3.3 70B (modèle plus volumineux et plus performant sur Groq)
- Llama 4 Scout 17B (modèle en preview de la dernière famille de Meta, aux capacités prometteuses)
L'objectif principal : trouver un modèle dont la latence soit inférieure à celle de GPT-4o pris comme référence. Nous nous attendions à une (légère) baisse de qualité des réponses pour y parvenir, et considérions toute réduction de coûts comme un bonus appréciable.
Nous avons testé ces modèles sur cinq tâches que Case IQ exécute lors de la création d'un engagement :
- Détection de la plateforme : à quelle plateforme précise se rapporte la demande ?
- Identification du produit : quel service cloud est concerné ?
- Évaluation de la sévérité : quelle est l'urgence du problème ?
- Identification de l'asset : quel projet ou compte est impacté ?
- Extraction des détails techniques : de quelles informations précises nos ingénieurs ont-ils besoin ?
En deux semaines, nous avons traité 21 517 traces issues de 755 engagements clients réels, en mesurant la latence, le coût et la précision.
Le socle technique qui a simplifié cette comparaison, c'est notre intégration LangChain déjà en place. Comme nous utilisions déjà LangChain pour notre implémentation GPT-4o, l'ajout des modèles à comparer s'est fait sans accroc : nous avons branché des appels ChatGroq en parallèle de notre intégration ChatOpenAI, en mode asynchrone pour ne pas perturber la production.
Nous nous sommes appuyés sur LangSmith pour une instrumentation complète : capture automatique des temps de latence, de la consommation de tokens, des taux d'erreur et des entrées/sorties sur l'ensemble des traces.
Les résultats : beaucoup plus de vitesse pour une perte de qualité minime
Les résultats ont dépassé nos attentes :
⚡ Vitesse multipliée par 4 à 5
- Détection de la plateforme : 571 ms → 249 ms (4,1x plus rapide, avec Llama 3.3 70B)
- Détection du produit : 851 ms → 406 ms (2,1x plus rapide, avec Llama 3.1 8B)
- Détection de la sévérité : 605 ms → 126 ms (2,6x plus rapide, avec Llama 3.3 70B)
- Détection de l'asset : 593 ms → 220 ms (2,7x plus rapide, avec Llama 3.3 70B)
- Extraction des détails techniques : 1 914 ms → 334 ms (5,7x plus rapide, avec Llama 3.1 8B)
💰 Jusqu'à 50x de réduction des coûts
Si la vitesse restait notre objectif premier, les économies se sont révélées spectaculaires : certaines tâches coûtent désormais 50x moins cher à exécuter, sans compromis sur la qualité.
🎯 Un niveau de performance maintenu
Une revue manuelle d'engagements clients réels nous a montré que GPT-4o atteignait 92 à 96 % de précision, tandis que nos alternatives plus rapides tenaient solidement la route :
- Llama 3.3 70B : 88 à 96 % de précision pour une vitesse 2 à 3x supérieure
- Llama 3.1 8B : 55 à 88 % de précision pour une vitesse 4 à 5x supérieure
La stratégie gagnante : une approche hybride
Plutôt que de retenir un seul modèle champion toutes catégories, nous avons conclu qu'il fallait combiner plusieurs modèles pour obtenir une solution globalement optimale :
- Llama 3.1 8B pour la détection du produit et des détails techniques (ces tâches étant interdépendantes, c'est ici que la vitesse compte le plus)
- Llama 3.3 70B pour la détection de la plateforme, de la sévérité et de l'asset (Llama 3.1 8B semblait peiner sur ces tâches, même si une marge d'optimisation existe sans doute côté prompting)
Le résultat ? Le temps de réponse total passe de plus de 3 secondes à moins d'une seconde, soit un gain global de 3 à 4x. Cette approche hybride devrait par ailleurs nous faire économiser environ 93 % sur notre facture totale.
Ce que cela change pour vous
⚡ Des réponses quasi instantanées : lorsque vous décrivez votre problème d'infrastructure cloud, Case IQ l'analyse et réclame les bons détails techniques presque immédiatement.
🔄 Du support en temps réel : ces gains de vitesse ouvrent de nouvelles possibilités. Nous étudions l'intégration directe du support dans Slack ou d'autres messageries déjà utilisées par nos clients.
🚀 Une meilleure résolution dès le premier contact : des descriptions de problèmes plus précises et plus complètes pour nos spécialistes, c'est moins d'allers-retours et des temps de réponse réduits.
À retenir, et la suite
Les détails techniques complets sont passionnants (et disponibles ici), mais l'enseignement clé tient en deux points :
- Le choix stratégique des modèles paie : un choix réfléchi du fournisseur et du modèle, combiné à de bonnes décisions d'architecture, permet de réduire drastiquement la latence (de plus de 3 secondes à moins d'une seconde) avec, en prime, des économies massives.
- L'évaluation humaine reste irremplaçable : les métriques automatisées fournissent des points de repère utiles, mais la revue manuelle reste essentielle pour comprendre la performance réelle dès qu'il s'agit de texte et d'humains ; il y a toujours des nuances que seules des personnes peuvent juger correctement.
Chez DoiT, nous croyons à une approche powered by technology, perfected by people. Ces améliorations garantissent que, lorsque vous avez besoin de l'expertise humaine de nos CRE, notre IA a déjà préparé le terrain pour vous apporter des réponses au plus vite.
—
Envie de tester par vous-même le nouveau Case IQ ? Parlons-en dès aujourd'hui : voyons comment nous pouvons vous aider.