
Quando o problema é crítico na infraestrutura em nuvem, cada segundo conta. Você precisa de ajuda rápida e que ela seja certeira. Mas, mesmo sem pressa, ninguém quer perder tempo precioso preenchendo formulários enormes pedindo um monte de informação; você quer descrever o problema e deixar que cuidem do resto.
O desafio: deixar o suporte com IA mais ágil e interativo
Na DoiT, contamos com o Ava para ajudar você com dúvidas de FinOps e nuvem. Mas, às vezes, você quer trocar uma ideia com um especialista humano. É aí que entra o nosso sistema Case IQ: ele ajuda os clientes a fornecer os detalhes técnicos certos na hora de abrir um chamado, garantindo que nossos Customer Reliability Engineers (CREs) tenham tudo o que precisam para resolver o problema rapidinho.
A ideia surgiu no nosso hackathon do verão de 2024 e foi construída sobre as APIs da OpenAI. Mas resolvemos ir além do status quo e fazer melhor, com foco na latência das recomendações ao cliente — para deixar o sistema mais ágil e interativo.
O experimento: cinco modelos avaliados em latência, custo e desempenho
Para resolver isso, montamos um experimento de 2 semanas comparando o nosso modelo atual (o GPT-4o, da OpenAI) com quatro alternativas:
- GPT-4.1 mini (modelo mais novo e mais rápido da OpenAI)
- Llama 3.1 8B (modelo menor e ultrarrápido, no hardware especializado da Groq)
- Llama 3.3 70B (modelo maior e mais robusto, na Groq)
- Llama 4 Scout 17B (modelo em preview da família mais recente da Meta, com recursos promissores)
O objetivo principal era achar um modelo com latência menor do que o baseline do GPT-4o. Já contávamos com uma queda (pequena) na qualidade da resposta para chegar lá, e qualquer corte de custo seria um bônus bem-vindo.
Testamos esses modelos em cinco tarefas que o Case IQ executa quando você cria um engajamento:
- Detecção de plataforma: a qual plataforma específica a solicitação se refere
- Identificação do produto: qual serviço de nuvem precisa de ajuda?
- Avaliação de severidade: o quão urgente é o problema?
- Identificação de ativo: qual projeto ou conta foi afetado?
- Extração de detalhes técnicos: de quais informações específicas nossos engenheiros precisam?
Em duas semanas, processamos 21.517 traces em 755 engajamentos reais de clientes, medindo latência, custo e precisão.
A base técnica que facilitou essa comparação foi a nossa integração já existente com o LangChain. Como já usávamos LangChain na implementação do GPT-4o, incluir os modelos comparados foi simples: adicionamos chamadas ao ChatGroq ao lado da nossa integração com o ChatOpenAI, executando-as de forma assíncrona para não impactar o sistema em produção.
Usamos o LangSmith para uma instrumentação completa, capturando automaticamente medidas de latência, uso de tokens, taxas de erro e logs de entrada/saída em todos os traces.
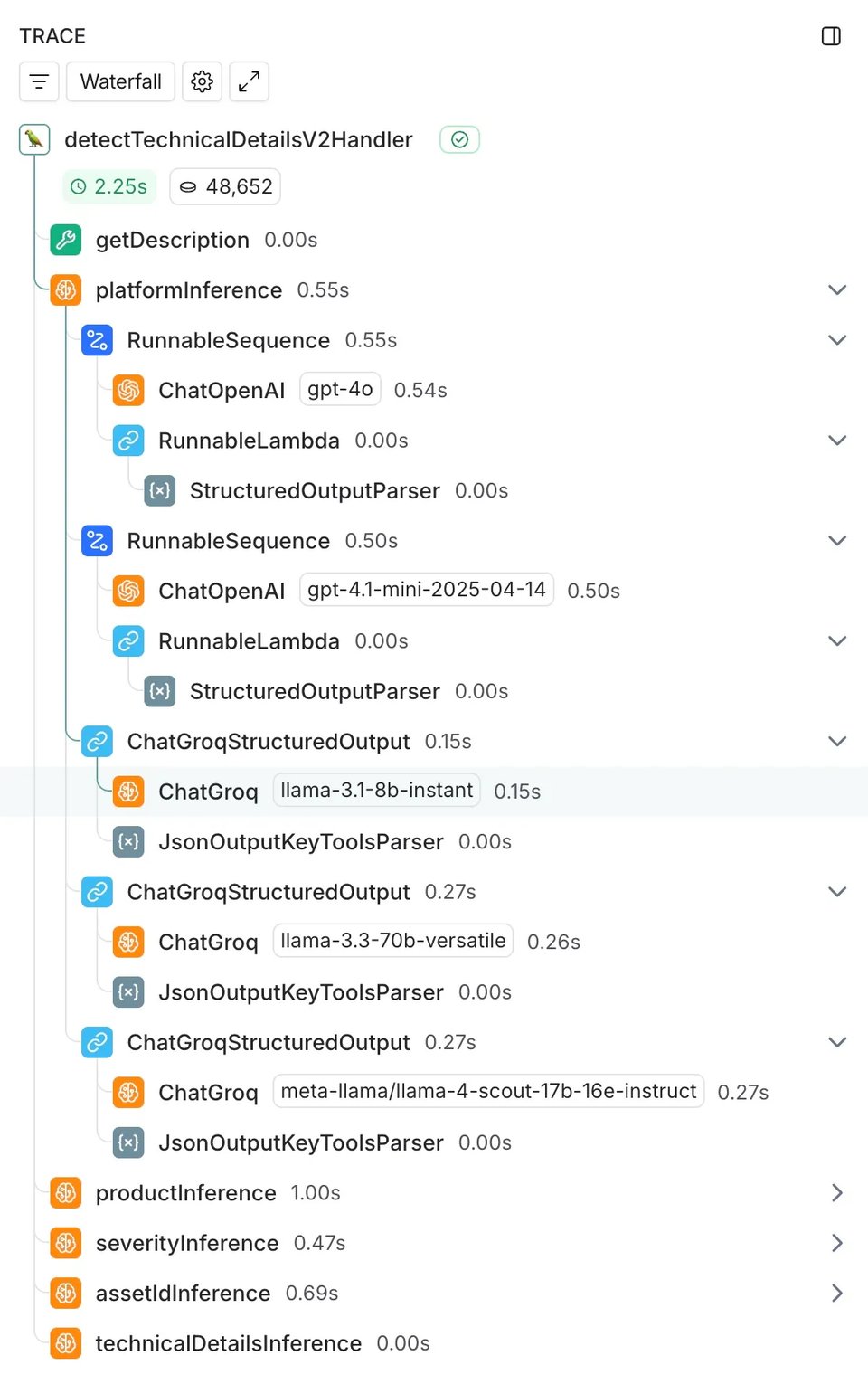
Os resultados: muito mais velocidade, com um pequeno custo em qualidade
Os resultados superaram nossas expectativas:
⚡ Ganhos de velocidade de 4 a 5x
- Detecção de plataforma: 571ms → 249ms (4,1x mais rápido, com Llama 3.3 70B)
- Detecção de produto: 851ms → 406ms (2,1x mais rápido, com Llama 3.1 8B)
- Detecção de severidade: 605ms → 126ms (2,6x mais rápido, com Llama 3.3 70B)
- Detecção de ativo: 593ms → 220ms (2,7x mais rápido, com Llama 3.3 70B)
- Extração de detalhes técnicos: 1.914ms → 334ms (5,7x mais rápido, com Llama 3.1 8B)
💰 Redução de custo de até 50x
A velocidade era o objetivo principal, mas a economia chamou a atenção — algumas tarefas ficaram 50x mais baratas de rodar, sem perder qualidade.
🎯 Desempenho mantido
Na revisão manual de engajamentos reais, vimos que o GPT-4o atingiu 92–96% de precisão, e nossas alternativas mais rápidas mantiveram um desempenho sólido:
- Llama 3.3 70B: 88–96% de precisão, com ganho de velocidade de 2–3x
- Llama 3.1 8B: 55–88% de precisão, com ganho de velocidade de 4–5x
A estratégia vencedora: uma abordagem híbrida
Em vez de eleger um único modelo "melhor", chegamos à conclusão de que precisávamos de modelos diferentes para a solução ideal:
- Llama 3.1 8B para detecção de produto e detalhes técnicos (como essas tarefas têm dependência entre si, é onde a velocidade pesa mais)
- Llama 3.3 70B para detecção de plataforma e severidade, além da identificação de ativo (o Llama 3.1 8B teve dificuldade nessa tarefa, embora acreditemos que dá para otimizar via prompting)
E o resultado? O tempo total de resposta cai de mais de 3 segundos para menos de 1 segundo: um ganho geral de 3 a 4x. E mais: com essa abordagem híbrida, esperamos uma economia de cerca de 93% na conta total.
O que isso significa para você
⚡ Respostas quase instantâneas: ao descrever seu problema de infraestrutura em nuvem, o CaseIQ agora consegue analisá-lo e pedir os detalhes técnicos corretos quase na hora.
🔄 Canais de suporte em tempo real: esses ganhos de velocidade abrem novas possibilidades. Estamos avaliando levar o suporte direto para o Slack ou outras plataformas de mensageria onde nossos clientes já estão.
🚀 Mais resoluções logo no primeiro contato: descrições mais precisas e completas para os nossos especialistas significam respostas mais rápidas e menos idas e vindas.
Aprendizados e próximos passos
Os detalhes técnicos completos são fascinantes (e estão disponíveis aqui), mas o aprendizado central foi duplo:
- Seleção estratégica de modelos funciona: escolher provedor e modelo com cuidado, combinado com boas decisões de arquitetura, gera ganhos drásticos de latência (de mais de 3 segundos para menos de 1) e, de quebra, uma economia enorme de custo.
- A avaliação humana é insubstituível: métricas automatizadas dão um bom ponto de partida, mas a revisão manual segue essencial para entender o desempenho real quando o assunto envolve texto e pessoas — sempre há nuances que só gente consegue avaliar de verdade.
Na DoiT, a gente acredita em ser "powered by technology, perfected by people". Essas melhorias garantem que, quando você precisar da expertise humana dos nossos CREs, nossa IA já terá feito a lição de casa para te entregar respostas o mais rápido possível.
—
Quer ver o Case IQ aprimorado em ação? Fale com a gente hoje e descubra como podemos ajudar.