
Cuando enfrentas un problema crítico de infraestructura en la nube, cada segundo cuenta. Necesitas ayuda rápida y precisa. Pero incluso sin prisa, no quieres perder tu tiempo llenando formularios eternos; quieres describir tu problema y que el resto se resuelva solo.
El reto: lograr un soporte asistido por IA más ágil e interactivo
En DoiT contamos con Ava para resolver tus consultas de FinOps y cloud. Aun así, a veces prefieres conversarlo con un experto humano. Para esos casos, nuestro sistema Case IQ ayuda a los clientes a aportar los detalles técnicos correctos al abrir un caso, de modo que nuestros Customer Reliability Engineers (CREs) tengan todo lo necesario para resolver los problemas con rapidez.
La idea nació en nuestro hackathon del verano de 2024 y se construyó sobre las APIs de OpenAI. Aun así, decidimos ir más allá del status quo y mejorar, enfocándonos en la latencia de las recomendaciones al cliente para que el sistema se sintiera más ágil e interactivo.
El experimento: cinco modelos puestos a prueba en latencia, costo y rendimiento
Para resolverlo, diseñamos un experimento de 2 semanas en el que comparamos nuestro modelo actual (GPT-4o de OpenAI) frente a cuatro alternativas:
- GPT-4.1 mini (el modelo más nuevo y rápido de OpenAI)
- Llama 3.1 8B (modelo más pequeño y ultrarrápido sobre el hardware especializado de Groq)
- Llama 3.3 70B (modelo más grande y capaz sobre Groq)
- Llama 4 Scout 17B (modelo en preview de la última familia de Meta, con capacidades prometedoras)
El objetivo principal era encontrar un modelo con menor latencia que el baseline de GPT-4o. Asumíamos que tendríamos que ceder un poco en calidad de respuesta para conseguirlo, y cualquier ahorro en costo sería un buen efecto secundario.
Probamos estos modelos en cinco tareas que Case IQ ejecuta cuando creas un engagement:
- Detección de plataforma: ¿con qué plataforma específica se relaciona la solicitud?
- Identificación del producto: ¿qué servicio cloud específico necesita ayuda?
- Evaluación de severidad: ¿qué tan urgente es el problema?
- Identificación del activo: ¿qué proyecto o cuenta se ve afectado?
- Extracción de detalles técnicos: ¿qué información específica necesitan nuestros Engineers?
En dos semanas procesamos 21,517 traces a lo largo de 755 engagements reales con clientes, midiendo latencia, costo y precisión.
La base técnica que facilitó esta comparación fue nuestra integración existente con LangChain. Como ya usábamos LangChain en nuestra implementación con GPT-4o, sumar los modelos a comparar fue muy directo: añadimos llamadas a ChatGroq junto a nuestra integración con ChatOpenAI, ejecutándolas de forma asíncrona para no afectar el sistema en producción.
Nos apoyamos en LangSmith para una instrumentación integral, capturando automáticamente mediciones de latencia, uso de tokens, tasas de error y logging de inputs y outputs en todos los traces.
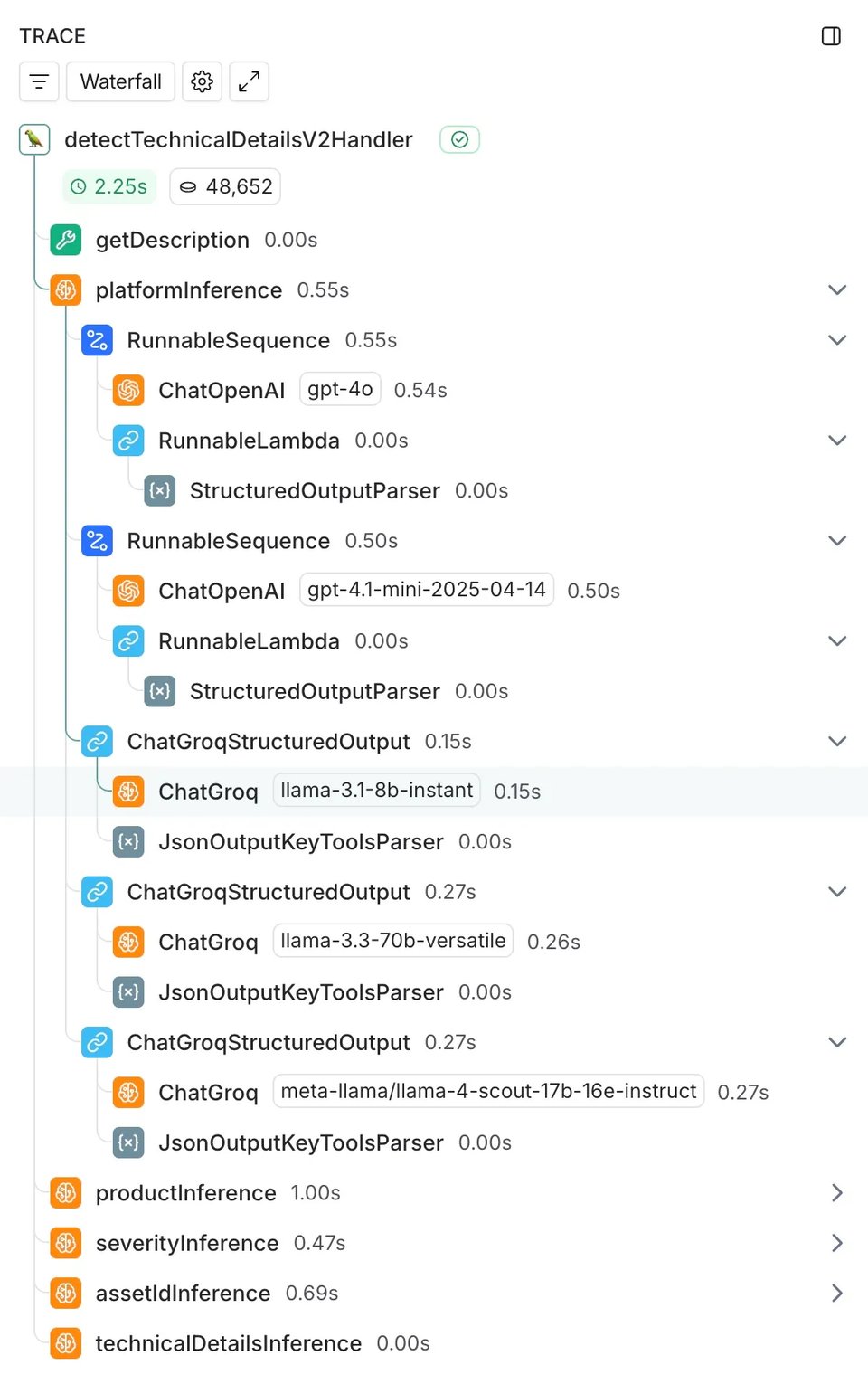
Los resultados: más velocidad con un costo mínimo en calidad
Los resultados superaron nuestras expectativas:
⚡ Mejoras de velocidad de 4–5x
- Detección de plataforma: 571ms → 249ms (4.1x más rápido, con Llama 3.3 70B)
- Detección de producto: 851ms → 406ms (2.1x más rápido, con Llama 3.1 8B)
- Detección de severidad: 605ms → 126ms (2.6x más rápido, con Llama 3.3 70B)
- Detección de activo: 593ms → 220ms (2.7x más rápido, con Llama 3.3 70B)
- Extracción de detalles técnicos: 1,914ms → 334ms (5.7x más rápido, con Llama 3.1 8B)
💰 Reducciones de costo de hasta 50x
Aunque la velocidad era nuestro objetivo principal, los ahorros en costo fueron notables: algunas tareas pasaron a ser 50x más baratas de ejecutar sin perder calidad.
🎯 Rendimiento que se sostiene
Tras revisar manualmente engagements reales con clientes, vimos que mientras GPT-4o alcanzaba una precisión del 92–96%, nuestras alternativas más rápidas se mantuvieron en buen nivel:
- Llama 3.3 70B: 88–96% de precisión con mejoras de velocidad de 2–3x
- Llama 3.1 8B: 55–88% de precisión con mejoras de velocidad de 4–5x
La estrategia ganadora: un enfoque híbrido
En vez de quedarnos con un único "mejor" modelo, concluimos que la solución óptima requería combinar varios:
- Llama 3.1 8B para detección de producto y detalles técnicos (como estas tareas dependen entre sí, es donde la velocidad más importa)
- Llama 3.3 70B para detección de plataforma, severidad e identificación de activos (Llama 3.1 8B parecía tener dificultades con esta tarea, aunque creemos que aún hay margen de optimización vía prompting)
¿El resultado? El tiempo total de respuesta baja de más de 3 segundos a menos de 1: una aceleración global de 3–4x. Además, con este enfoque híbrido proyectamos un ahorro de ~93% sobre nuestra factura total.
Qué significa esto para ti
⚡ Respuestas casi instantáneas: cuando describes tu problema de infraestructura en la nube, CaseIQ puede analizarlo y pedirte los detalles técnicos correctos casi al instante.
🔄 Canales de soporte en tiempo real: estas mejoras de velocidad abren nuevas posibilidades. Estamos explorando llevar el soporte directamente a Slack u otras plataformas de mensajería donde nuestros clientes ya están.
🚀 Mejor resolución a la primera: descripciones más precisas y completas para nuestros especialistas se traducen en respuestas más rápidas y menos idas y vueltas.
Conclusiones y próximos pasos
Aunque los detalles técnicos completos son fascinantes (y están disponibles aquí), el aprendizaje clave fue doble:
- La selección estratégica de modelos funciona: elegir con cuidado el proveedor y el modelo, sumado a decisiones de arquitectura inteligentes, permite mejoras drásticas en latencia (de más de 3 segundos a sub-segundo) y, como bonus, reducciones masivas de costo.
- La evaluación humana es insustituible: las métricas automatizadas dan baselines útiles, pero la revisión manual sigue siendo esencial para entender el rendimiento real cuando se trata de texto y personas; siempre hay matices que solo alguien humano puede valorar bien.
En DoiT creemos en ser "powered by technology, perfected by people". Estas mejoras garantizan que, cuando necesites la experiencia humana de nuestros CREs, nuestra IA ya habrá hecho el trabajo previo para darte respuestas lo antes posible.
—
¿Quieres probar el nuevo Case IQ por ti mismo? Habla con nosotros hoy y descubre cómo podemos ayudarte.