
クラウドインフラの重大なトラブルでは、一刻を争います。求められるのは、迅速かつ的確なサポート。とはいえ急ぎでない場面でも、長々としたフォーム入力に貴重な時間を費やしたくはないはずです。問題を伝えれば、あとはお任せ──そんな体験こそ理想ではないでしょうか。
課題:AIサポートをもっと軽快に、もっとインタラクティブに
DoiTでは、FinOpsやクラウドに関するご質問にお応えするAvaをご用意しています。とはいえ、人間の専門家とじっくり相談したい場面もあるはずです。そんなときに役立つのがCase IQです。ケースを起票する際にお客様が必要な技術情報を漏れなく伝えられるようサポートし、Customer Reliability Engineers(CRE)が問題をすばやく解決するための材料をすべて揃えます。
このアイデアは2024年夏のハッカソンで生まれ、OpenAIのAPIをベースに構築されました。ただ、私たちはそこで満足せず、さらに先を目指しました。お客様への提案までのレイテンシに徹底的にこだわり、より軽快でインタラクティブな体験へと磨き上げたのです。
検証:5つのモデルでレイテンシ・コスト・性能を比較
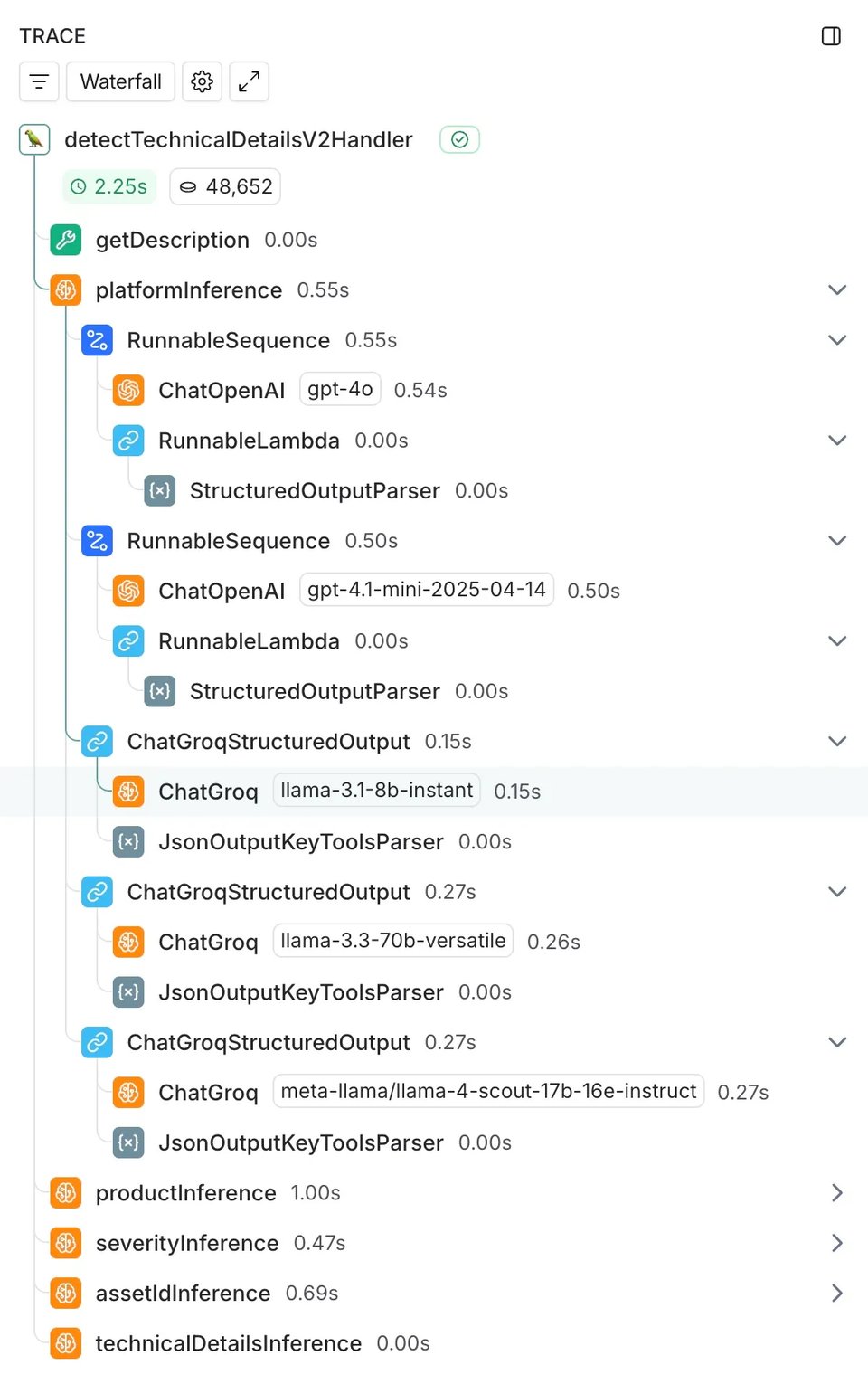
そのために、現行モデル(OpenAIのGPT-4o)と4つの代替モデルを比較する2週間にわたる包括的な検証を実施しました。
- GPT-4.1 mini(OpenAIの新世代の高速モデル)
- Llama 3.1 8B(Groqの専用ハードウェアで動作する小型・超高速モデル)
- Llama 3.3 70B(Groq上で動作する大型・高性能モデル)
- Llama 4 Scout 17B(Metaの最新モデルファミリーの有望なプレビューモデル)
主な狙いは、GPT-4oをベースラインとし、それより低いレイテンシを実現できるモデルを見つけることです。応答品質はある程度(わずかに)落ちることを覚悟しつつ、コスト削減はうれしいおまけとして捉えました。
これらのモデルを、お客様がエンゲージメントを作成する際にCase IQが担う5つのタスクで検証しました。
- プラットフォーム検出:リクエスト対象のプラットフォームは何か
- プロダクト識別:サポートが必要なクラウドサービスはどれか
- 緊急度判定:この問題はどの程度緊急か
- アセット識別:どのプロジェクトまたはアカウントが影響を受けているか
- 技術情報の抽出:エンジニアに必要な具体情報は何か
2週間で755件の実顧客エンゲージメントから21,517件のトレースを処理し、レイテンシ、コスト、精度を測定しました。
この比較をスムーズに進められた技術的な土台が、既存のLangChain連携です。GPT-4o実装ですでにLangChainを採用していたため、比較対象モデルの追加は容易でした。既存のChatOpenAI連携と並べてChatGroq呼び出しを組み込み、本番システムに影響を与えないよう非同期で実行しました。
計測基盤にはLangSmithを活用し、すべてのトレースについてレイテンシ、トークン使用量、エラー率、入出力ログを自動で記録しています。
結果:わずかな品質低下と引き換えに、大幅な高速化
結果は、私たちの想定を超えるものでした。
⚡ 4〜5倍のスピード向上
- プラットフォーム検出:571ms → 249ms(Llama 3.3 70B、4.1倍高速)
- プロダクト検出:851ms → 406ms(Llama 3.1 8B、2.1倍高速)
- 緊急度判定:605ms → 126ms(Llama 3.3 70B、2.6倍高速)
- アセット検出:593ms → 220ms(Llama 3.3 70B、2.7倍高速)
- 技術情報の抽出:1,914ms → 334ms(Llama 3.1 8B、5.7倍高速)
💰 最大50分の1のコスト削減
主目的はスピード向上でしたが、コスト削減効果も目を見張るものでした。品質を保ったまま、一部のタスクは実行コストが50分の1にまで下がっています。
🎯 性能はしっかり維持
実際の顧客エンゲージメントを手動でレビューしたところ、GPT-4oが92〜96%の精度を示した一方、より高速な代替モデルも十分な性能を保っていました。
- Llama 3.3 70B:精度88〜96%、2〜3倍の高速化
- Llama 3.1 8B:精度55〜88%、4〜5倍の高速化
勝ちパターン:ハイブリッドアプローチ
たった一つの「ベスト」モデルを選ぶのではなく、全体として最適な解を得るには、タスクごとに異なるモデルを使い分けるのが正解だと結論づけました。
- Llama 3.1 8B:プロダクト検出と技術情報の抽出に採用(両タスクは互いに依存しており、スピードが最も効くため)
- Llama 3.3 70B:プラットフォーム検出、緊急度判定、アセット識別に採用(Llama 3.1 8Bはこれらで苦戦しましたが、プロンプト調整による改善の余地はあると考えています)
結果は? 合計応答時間は3秒超から1秒未満へ短縮、全体で3〜4倍の高速化を実現しました。さらに、このハイブリッド構成により総コストの約93%削減も見込まれます。
お客様にとっての意味
⚡ ほぼ瞬時のレスポンス:クラウドインフラの問題を入力すると、CaseIQがほぼ即座に内容を解析し、必要な技術情報をその場で確認します。
🔄 リアルタイムなサポートチャネル:この高速化により、新たな可能性が広がります。お客様が日常的に使うSlackなどのメッセージングプラットフォーム上で、直接サポートを提供することも検討中です。
🚀 初回解決率の向上:スペシャリストに届く問題説明がより正確かつ網羅的になることで、応答時間が短くなり、やり取りの往復も減ります。
学びと次のステップ
技術的な詳細(こちらで公開中)も読み応えがありますが、押さえるべき学びは大きく2つです。
- 戦略的なモデル選定は効く:プロバイダーとモデルを慎重に選び、賢いアーキテクチャ判断と組み合わせれば、レイテンシを劇的に改善し(3秒超から1秒未満へ)、おまけに大幅なコスト削減まで手にできます。
- 人による評価はやはり欠かせない:自動メトリクスは有用なベースラインになりますが、テキストや人間が関わる場面で実際の性能を見極めるには、手動レビューが不可欠です。人にしか拾えないニュアンスが必ずあります。
DoiTは「powered by technology, perfected by people(テクノロジーで動かし、人の手で磨き上げる)」を信条としています。今回の改善により、CREの専門知識が必要になったときには、AIがすでに下準備を整えており、できるだけ早く答えをお届けできる体制が整っています。
—
進化したCase IQをぜひご自身で体感してみませんか? 今すぐお問い合わせください。私たちがどのようにお力になれるかをご紹介します。