
When you’re dealing with a critical cloud infrastructure issue, every second counts. You need help fast, and you need it to be accurate. But even when you’re not in a rush, you don’t want to spend your precious time going through long forms asking to be filled out; you want to describe your problem and you want the rest to be taken care of.
The Challenge: making AI-assisted support snappier and more interactive
At DoiT, we have Ava to assist you with your FinOps and cloud queries. Sometimes, though, you want to talk things through with a human expert. This is when our Case IQ system helps customers provide the correct technical details when opening a case, ensuring our Customer Reliability Engineers (CREs) have everything they need to solve problems quickly.
The idea originated from our hackathon in summer 2024 and was built on OpenAI APIs. However, we decided to push the status quo and do better, focusing on the latency of our recommendations to the customer, making the system feel more snappy and interactive.
The Experiment: testing five models for latency, cost, and performance
To solve this, we designed a comprehensive 2-week experiment comparing our current model (OpenAI’s GPT-4o) against four alternatives:
- GPT-4.1 mini (OpenAI’s newer, faster model)
- Llama 3.1 8B (smaller, ultra-fast model on Groq’s specialized hardware)
- Llama 3.3 70B (larger, more capable model on Groq)
- Llama 4 Scout 17B(preview model from Meta’s latest family of models with promising capabilities)
The main aim was to find a model with lower latencies than the GPT-4o baseline. We expect to take a (small) hit on response quality to achieve that, and take any cost-cutting as a nice side-effect.
We tested these models across five tasks that Case IQ performs when you create an engagement:
- Platform detection: What specific platform is the request related to
- Product identification: Which specific cloud service needs help?
- Severity assessment: How urgent is this problem?
- Asset identification: Which project or account is affected?
- Technical details extraction: What specific information do our engineers need?
Over two weeks, we processed 21,517 traces across 755 real customer engagements, measuring latency, cost, and accuracy.
The technical foundation that made this comparison easy was our existing LangChain integration. Since we were already using LangChain for our GPT-4o implementation, adding the comparison models was straightforward: we added ChatGroq calls alongside our existing ChatOpenAI integration, running them asynchronously to avoid impacting our production system.
We leveraged LangSmith for comprehensive instrumentation, automatically capturing latency measurements, token usage, error rates, and input/output logging across all traces.
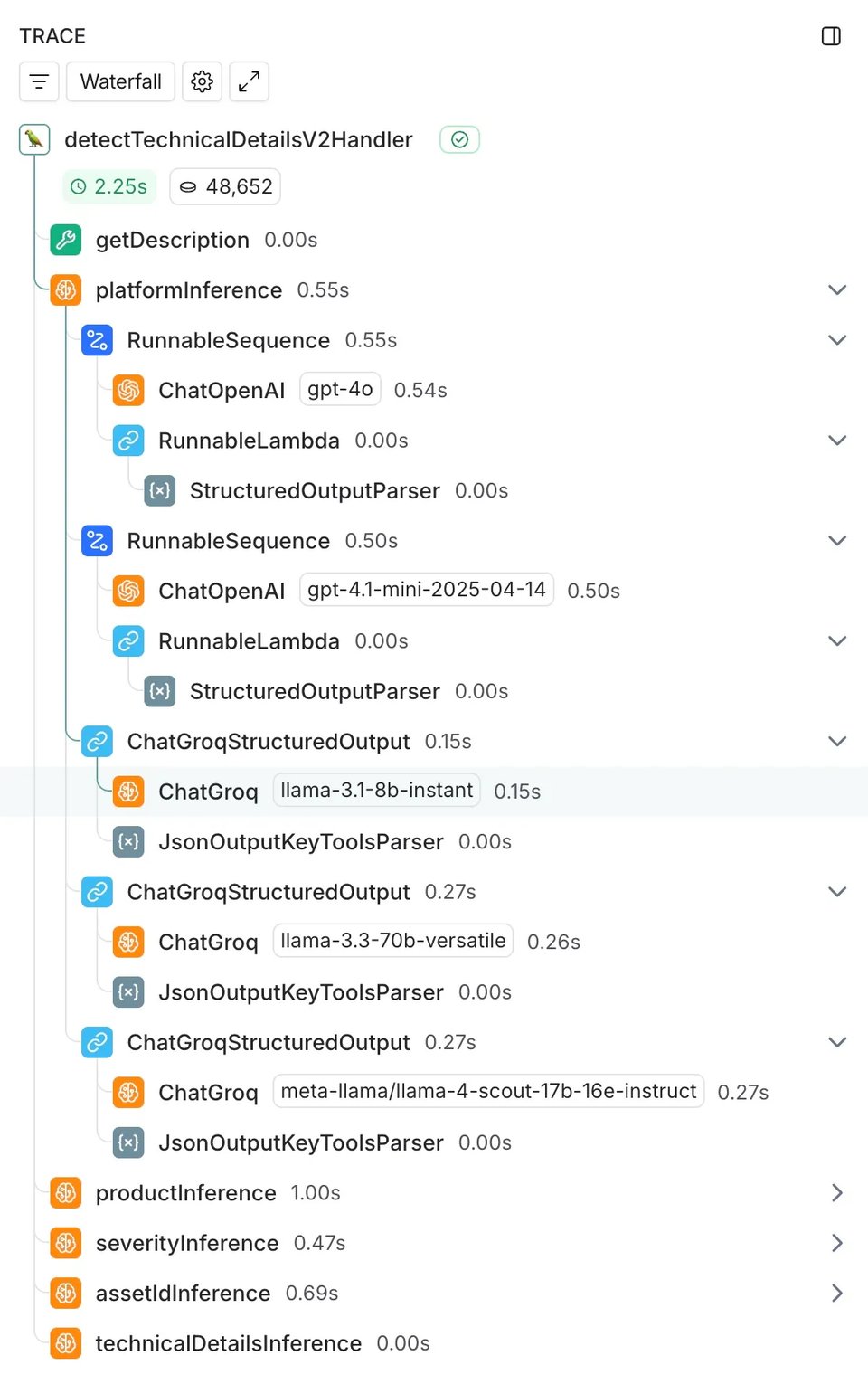
The Results: increased speed for a small sacrifice in quality
The results exceeded our expectations:
⚡ 4–5x speed improvements
- Platform detection: 571ms → 249ms (4.1x faster, using Llama 3.3 70B)
- Product detection: 851ms → 406ms (2.1x faster, using Llama 3.1 8B)
- Severity detection: 605ms → 126ms (2.6x faster, using Llama 3.3 70B)
- Asset detection: 593ms → 220ms (2.7x faster, using Llama 3.3 70B)
- Technical details extraction: 1,914ms → 334ms (5.7x faster, using Llama 3.1 8B)
💰 Up to 50x cost reductions
While speed was our primary goal, the cost savings were remarkable — some tasks became 50x cheaper to run while maintaining quality.
🎯 Keeping up performance
Through manual review of real customer engagements, we found that while GPT-4o scored 92–96% accuracy, our faster alternatives maintained strong performance:
- Llama 3.3 70B: 88–96% accuracy with 2–3x speed improvements
- Llama 3.1 8B: 55–88% accuracy with 4–5x speed improvements
The Winning Strategy: A Hybrid Approach
Rather than picking a single “best” model, we concluded that different models were needed for an overall optimal solution:
- Llama 3.1 8B for product and technical detail detection (since these tasks have dependencies on each other, this is where speed matters most)
- Llama 3.3 70B for platform, and severity detection, and asset identification (Llama 3.1 8B seemed to struggle with this task, although we believe there is room for optimisation through prompting)
The result? Total response time drops from over 3 seconds to under 1 second: a 3–4x overall speedup. Moreover, with this hybrid approach, we are expecting a cost savings of ~93% on our total bill.
What this means for you
⚡ Near-Instant Responses: When you describe your cloud infrastructure problem, CaseIQ can now analyze it and request the correct technical details almost instantly.
🔄 Real-Time Support Channels: These speed improvements unlock new possibilities. We are exploring putting support directly in Slack or other messaging platforms where our customers are already present.
🚀 Better First-Time Resolution: More accurate and complete problem descriptions for our specialists lead to faster response times and reduced back-and-forth.
Takeaways and what’s next
While the full technical details are fascinating (and available here), the key learning was twofold:
- Strategic model selection works: Careful provider and model selection combined with smart architectural decisions can achieve dramatic latency improvements (3+ seconds to sub-second) while delivering massive cost reductions as a bonus.
- Human evaluation is irreplaceable: While automated metrics provide useful baselines, manual review remains essential for understanding actual performance when dealing with text and humans; there’s always nuance that only people can properly evaluate.
At DoiT, we believe in being “powered by technology, perfected by people.” These improvements ensure that when you need human expertise from our CREs, our AI has already done the groundwork to get you answers as quickly as possible.
—
Want to experience the improved Case IQ for yourself? Talk to us today and see how we can help you.